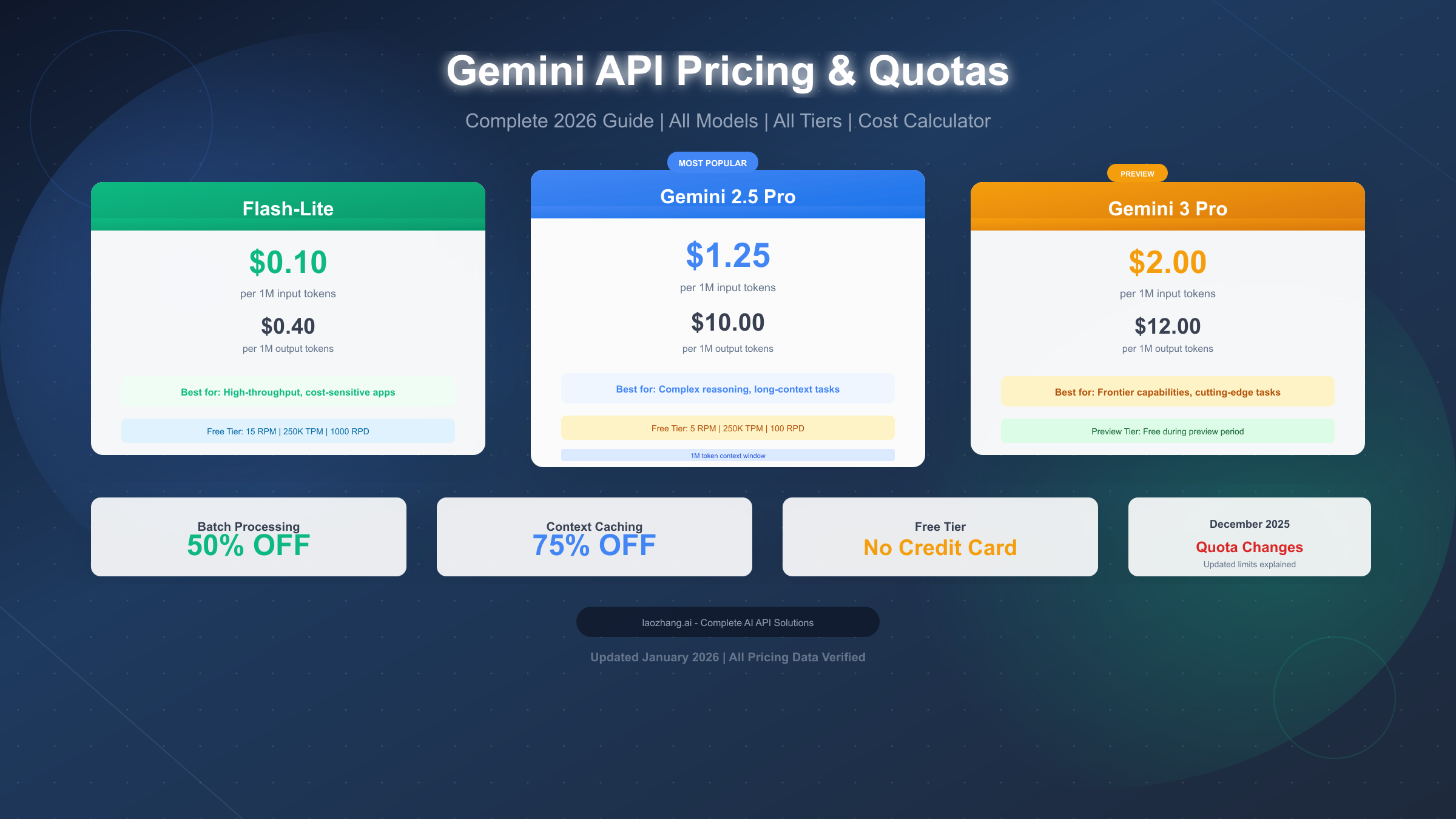
Google's Gemini API pricing operates on a token-based model with distinct free and paid tiers, offering rates from $0.10 per million input tokens for Flash-Lite to $2.00 for Gemini 3 Pro Preview. As of January 2026, the free tier provides 5-15 requests per minute depending on the model, with 250,000 tokens per minute and up to 1,000 requests per day—though these limits were significantly adjusted in the December 2025 quota changes. Whether you're prototyping on the free tier or running production workloads, understanding how pricing and quotas interact is essential for controlling costs and avoiding unexpected 429 errors.
Understanding Gemini API Quotas
Before diving into pricing, understanding quota mechanics is crucial because quotas directly impact how you can use the API regardless of your budget. The Gemini API enforces limits through four primary dimensions that work together to control access and ensure fair usage across all developers.
Requests Per Minute (RPM) represents the maximum number of API calls you can make within any rolling 60-second window. For the free tier, this ranges from 5 RPM for Gemini 2.5 Pro to 15 RPM for Flash-Lite. When you exceed this limit, the API returns a 429 error with a Retry-After header indicating when you can resume requests. The RPM limit is particularly important for real-time applications where response latency matters.
Tokens Per Minute (TPM) caps the total number of tokens—both input and output combined—processed within a minute. The free tier universally sets this at 250,000 TPM across all models, which sounds generous until you consider that a single long-context request with a 100,000-token document consumes 40% of your minute's allocation. Production applications with high-throughput requirements typically need Tier 1 or higher for 1M+ TPM limits.
Requests Per Day (RPD) establishes a daily ceiling that resets at midnight Pacific Time. This quota saw the most dramatic changes in December 2025, with some models dropping from 250+ requests per day to as few as 20-100 for free tier users. For a deeper understanding of how these limits work under the hood, see our detailed explanation of Gemini API rate limits.
Images Per Minute (IPM) is a newer quota dimension specifically for image generation capabilities in models like Nano Banana Pro. This limits how many images you can generate per minute, separate from your text processing quotas.
The quota system uses a token bucket algorithm that continuously refills at your allocated rate. When your bucket is full, additional requests are immediately accepted; when empty, requests are queued or rejected. Understanding this mechanism helps you design applications that maximize throughput without hitting limits unexpectedly.

Complete Pricing Breakdown by Model
Google's Gemini API pricing structure varies significantly across model families, with rates depending on capability tier, context length, and input type. All prices are per million tokens unless otherwise specified, and long-context requests exceeding 200,000 tokens incur a 2x multiplier on most models.
Gemini 3 Pro Preview represents the frontier of Google's AI capabilities. Currently in preview with a temporary free tier waiver, the production pricing is set at $2.00 per million input tokens and $12.00 per million output tokens for contexts up to 200,000 tokens. Beyond that threshold, rates double to $4.00/$18.00. Stable pricing expected in early 2026 may settle around $1.50/$10 with additional caching and batch discounts.
Gemini 2.5 Pro remains the workhorse for complex reasoning and long-context tasks. The pricing structure includes:
| Context Length | Input (per 1M) | Output (per 1M) |
|---|---|---|
| ≤200K tokens | $1.25 | $10.00 |
| >200K tokens | $2.50 | $20.00 |
This model supports the full 1-million token context window even on the free tier, making it valuable for document analysis and research applications that require extensive context understanding.
Gemini 2.5 Flash delivers an excellent balance of performance and cost, positioning itself as the go-to model for most production workloads:
| Input Type | Input (per 1M) | Output (per 1M) |
|---|---|---|
| Text | $0.30 | $2.50 |
| Image | $0.30 | $2.50 |
| Video | $0.30 | $2.50 |
| Audio | $0.70 | $2.50 |
Gemini 2.5 Flash-Lite offers the most economical option for high-throughput, latency-sensitive applications at $0.10 per million input tokens and $0.40 per million output tokens. This model is ideal for chatbots, classification tasks, and any scenario where you prioritize speed and cost over maximum capability.
Gemini 2.0 Flash and 2.0 Flash-Lite maintain similar pricing to their 2.5 counterparts but eliminate the short/long context pricing distinction, making them more cost-effective for mixed-context workloads.
Image Generation Pricing follows a different model. Using Nano Banana Pro through the Gemini API, image input costs approximately $0.0011 per image (560 tokens), while output images are priced at $0.039 per image at 1024x1024 resolution (1290 tokens at $30/M) or up to $0.24 per image at 4096x4096 resolution. For detailed pricing on image generation, refer to our complete guide to Gemini API free tier limits.
Grounding with Google Search adds real-time search data to responses. The first 1,500 queries per day are free on paid tiers, after which pricing is $35 per 1,000 grounding queries.
December 2025 Quota Changes Explained
The Gemini API landscape shifted dramatically on December 7, 2025, when Google announced significant adjustments to both free and paid tier quotas. These changes caught many developers off-guard, with unexpected 429 errors disrupting production applications that had been running smoothly for months.
Before December 2025, the free tier was considerably more generous. Gemini 2.5 Flash allowed approximately 250 requests per day with 10-15 RPM. Developers could build and test substantial applications without spending a dollar. The free tier was genuinely useful for small production deployments serving moderate traffic.
After December 2025, the free tier became primarily a testing ground rather than a viable production option. The most impactful changes included:
| Model | Before (RPD) | After (RPD) | Change |
|---|---|---|---|
| Gemini 2.5 Pro | ~250 | 100 | -60% |
| Gemini 2.5 Flash | ~250 | ~20-50 | -80-92% |
| Gemini 2.5 Flash-Lite | ~500 | 1000 | +100% |
Several developers reported that Gemini 2.5 Pro now automatically switches to Flash after 10-15 prompts on the free tier, even when explicitly requesting Pro. This "model blending" approach aims to balance user experience with capacity constraints but has frustrated developers who specifically need Pro's reasoning capabilities.
Why Google Made These Changes likely relates to the exponential growth in API usage and the computational cost of running frontier models. The December 2025 timing coincided with increased adoption following the Gemini 3 Pro Preview announcement, suggesting capacity management was a primary driver.
Migration Strategies for developers affected by these changes include upgrading to Tier 1 (enabling Cloud Billing provides immediate quota increases), implementing request queuing and rate limiting, switching to Flash-Lite for compatible workloads, and using context caching to reduce effective request counts. If you're encountering 429 errors, our guide on fixing Gemini API Resource Exhausted errors provides step-by-step solutions.
Free Tier vs Paid Tiers Comparison
Choosing between Gemini's free and paid tiers involves understanding not just pricing but also feature availability, data handling policies, and quota implications. Here's a comprehensive comparison to help you make an informed decision.
Free Tier Benefits and Limitations
The free tier requires no credit card and provides genuine access to Gemini's capabilities for testing and prototyping. Key characteristics include access to all current models (2.5 Pro, Flash, Flash-Lite, 3 Pro Preview), the full 1-million token context window, Google AI Studio integration at no cost, and RPM limits of 5-15 depending on model. However, there are important caveats: your prompts and responses may be used to improve Google products, daily request limits are restrictive for production use, and there's no access to context caching or batch processing discounts.
Tier 1 (Pay-as-You-Go)
Enabling Cloud Billing immediately unlocks Tier 1, which provides significantly higher quotas without volume commitments. Benefits include 100-500 RPM depending on model, 1M+ TPM, unlimited daily requests, your data is not used for model training, access to context caching (75% savings on repeated prompts), batch processing (50% discount), and priority support access. The cost structure remains pay-per-token with no minimum spend.
Tier 2 (Higher Limits)
Tier 2 requires requesting an upgrade through the Cloud Console and is typically approved for applications demonstrating consistent usage patterns. This tier offers 1,000+ RPM, 4M+ TPM, custom quotas based on needs, and dedicated capacity for critical workloads. Pricing remains the same per-token rates but with the ability to handle significantly higher throughput.
Enterprise Tier
Organizations spending $10,000+ monthly can negotiate custom terms including volume discounts (typically 30-40% off list prices), custom SLAs, dedicated support, data residency options, and private endpoints. Enterprise negotiations typically start around $25,000 monthly spend for meaningful discounts.
For developers exploring Pro model limits specifically, our Gemini 2.5 Pro free API limits guide provides detailed breakdowns.
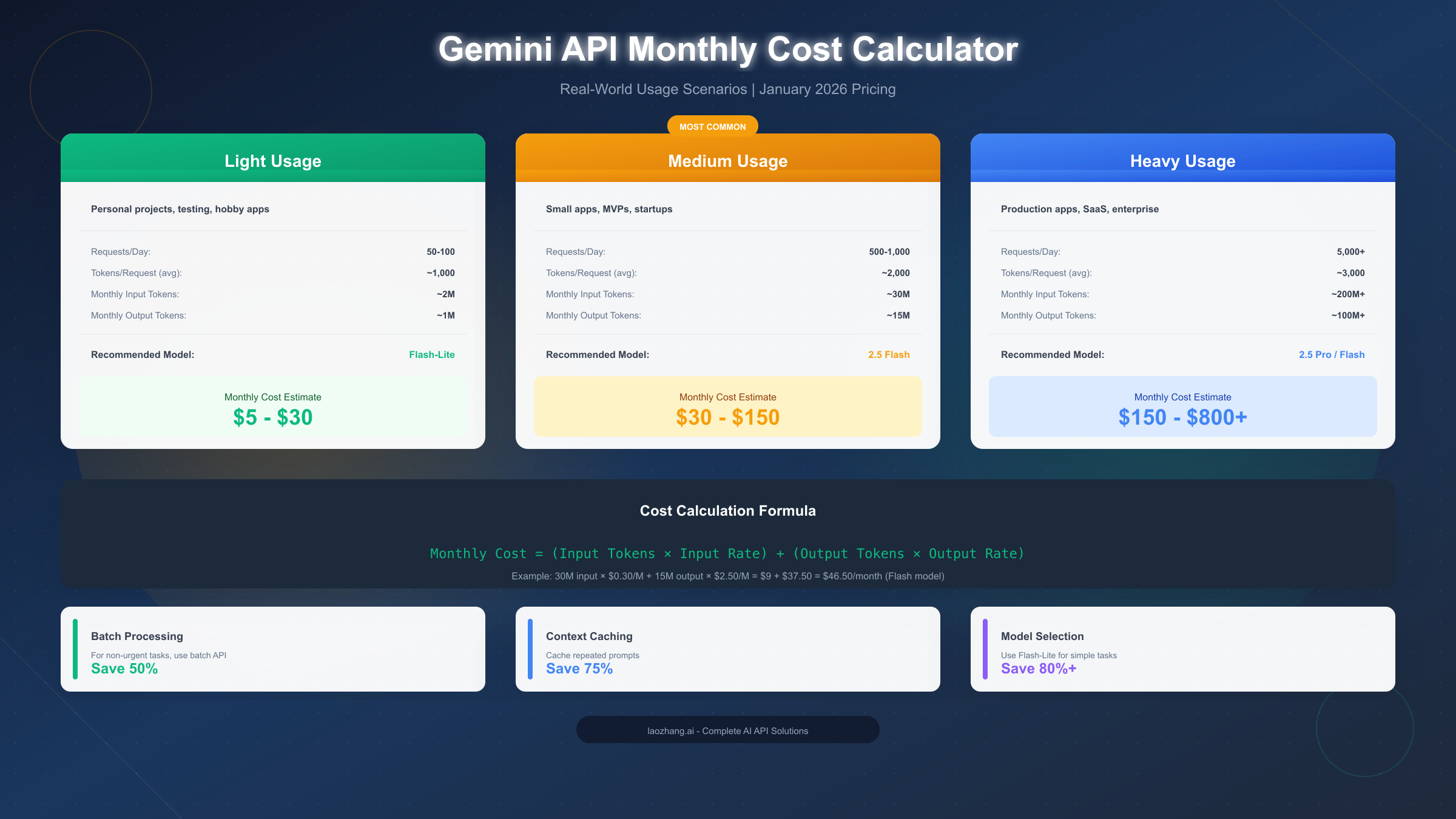
Cost Calculator and Real-World Examples
Understanding theoretical pricing is one thing; knowing what you'll actually pay monthly is another. Let's walk through realistic usage scenarios with concrete cost calculations.
Token Counting Fundamentals
Before calculating costs, understand how Gemini counts tokens. Text tokens roughly correspond to 4 characters or 0.75 words in English, so 1,000 words equals approximately 1,333 tokens. Images are converted to a fixed 560 tokens regardless of size. Video tokens depend on frame rate—at 1 FPS, each second costs 258 tokens. Audio tokens run at 25 per second without timestamps.
Light Usage Scenario: Personal Projects
A developer building a personal assistant chatbot with 50-100 daily queries averaging 1,000 tokens each would see monthly usage of approximately 2M input tokens and 1M output tokens. Using Flash-Lite at current pricing:
Input: 2M tokens × \$0.10/M = \$0.20
Output: 1M tokens × \$0.40/M = \$0.40
Total: \$0.60/month
This easily fits within the free tier limits for Flash-Lite, but transitioning to paid ensures consistent availability without daily quota concerns.
Medium Usage Scenario: Startup MVP
A startup running a customer support bot handling 500-1,000 daily queries with 2,000-token average conversations generates roughly 30M input tokens and 15M output tokens monthly. Using 2.5 Flash:
Input: 30M tokens × \$0.30/M = \$9.00
Output: 15M tokens × \$2.50/M = \$37.50
Total: \$46.50/month
Adding context caching for repeated prompt components could reduce input costs by 75%, bringing the total closer to $40/month.
Heavy Usage Scenario: Production SaaS
A production application serving 5,000+ daily requests with complex 3,000-token interactions processes approximately 200M input tokens and 100M output tokens monthly. Using a mix of Pro and Flash:
Pro (complex queries - 30%):
Input: 60M × \$1.25/M = \$75
Output: 30M × \$10.00/M = \$300
Flash (standard queries - 70%):
Input: 140M × \$0.30/M = \$42
Output: 70M × \$2.50/M = \$175
Total: \$592/month
With batch processing for non-urgent requests, this could drop to approximately $450/month.
Python Cost Estimation Code
pythondef estimate_monthly_cost( daily_requests: int, avg_input_tokens: int, avg_output_tokens: int, model: str = "flash" ) -> dict: # Model pricing (per million tokens) pricing = { "flash-lite": {"input": 0.10, "output": 0.40}, "flash": {"input": 0.30, "output": 2.50}, "pro": {"input": 1.25, "output": 10.00}, "3-pro": {"input": 2.00, "output": 12.00} } monthly_input = daily_requests * avg_input_tokens * 30 monthly_output = daily_requests * avg_output_tokens * 30 rates = pricing[model] input_cost = (monthly_input / 1_000_000) * rates["input"] output_cost = (monthly_output / 1_000_000) * rates["output"] return { "model": model, "monthly_input_tokens": monthly_input, "monthly_output_tokens": monthly_output, "input_cost": round(input_cost, 2), "output_cost": round(output_cost, 2), "total_cost": round(input_cost + output_cost, 2) } result = estimate_monthly_cost( daily_requests=500, avg_input_tokens=2000, avg_output_tokens=1000, model="flash" ) print(f"Estimated monthly cost: ${result['total_cost']}")
Choosing the Right Model for Your Use Case
Selecting the optimal Gemini model involves balancing capability requirements against cost constraints. Here's a practical framework for making that decision based on common use cases.
Chatbots and Conversational AI
For general-purpose chatbots, Flash-Lite offers the best cost-performance ratio. It handles standard conversations, FAQ responses, and basic reasoning at 8x lower cost than Flash. Reserve Flash for conversations requiring nuanced understanding or Flash transitions to Pro for complex problem-solving scenarios.
Document Analysis and Summarization
Document analysis benefits from Flash's balance of capability and cost. For documents under 50,000 tokens, Flash processes efficiently. For longer documents approaching the 1M context window, consider whether the analysis requires Pro's enhanced reasoning or if Flash can adequately extract and summarize the content.
Code Generation and Review
Code tasks typically need Pro's reasoning capabilities for architecture decisions, complex debugging, or generating substantial codebases. Flash handles simpler tasks like code completion, documentation generation, and straightforward refactoring. Flash-Lite works for syntax-level tasks like formatting or simple transpilation.
Content Generation
Marketing copy, blog posts, and creative writing work well with Flash for most purposes. Pro adds value for long-form content requiring consistent voice, complex narrative structures, or technical accuracy in specialized domains.
Real-Time Applications
For applications where latency matters—live customer support, interactive gaming, real-time translation—Flash-Lite's speed advantage outweighs its capability limitations. The faster response times also reduce perceived wait times for users, improving overall experience.
Decision Framework Table
| Use Case | Recommended Model | Monthly Cost (1000 req/day) |
|---|---|---|
| Simple chatbot | Flash-Lite | $5-20 |
| Customer support | Flash | $30-80 |
| Document analysis | Flash/Pro | $50-200 |
| Code generation | Pro | $100-400 |
| Real-time apps | Flash-Lite | $10-40 |
| Research/reasoning | Pro/3 Pro | $150-600 |
Cost Optimization Strategies
Reducing Gemini API costs without sacrificing functionality requires strategic approaches to how you structure requests, cache content, and select models. Here are proven techniques that can cut your bills by 50-80%.
Batch Processing (50% Savings)
For non-time-sensitive workloads, the Batch API provides a flat 50% discount with a 24-hour SLA. This works well for bulk content generation, overnight document processing, data enrichment pipelines, and scheduled report generation. Structure your application to queue non-urgent requests and process them in batches during off-peak hours.
Context Caching (Up to 75% Savings)
When your prompts include repeated content—system prompts, reference documents, or few-shot examples—context caching stores this content server-side. Subsequent requests reference the cached context at dramatically reduced rates. A typical implementation caches your 10,000-token system prompt once, then references it across thousands of requests, saving $0.01 per request or more.
Prompt Optimization
Concise prompts cost less and often produce better results. Strategies include removing redundant instructions, using structured output formats (JSON schemas reduce output verbosity), implementing prompt templates with variables rather than full rewrites, and trimming conversation history to relevant context only.
Model Selection Optimization
Not every request needs your most capable model. Implement a tiered approach where you start with Flash-Lite for the first attempt, escalate to Flash if the response quality is insufficient, and reserve Pro for explicitly complex queries. A simple quality-check function can route requests appropriately.
Token Efficiency Techniques
Consider these approaches for reducing token consumption: use summarization to compress long inputs before processing, implement incremental context windows that discard old conversation turns, leverage structured data formats over natural language when possible, and cache frequent lookups (like product catalogs) locally rather than including in prompts.
API Aggregation for Cost Management
For teams managing multiple AI APIs across providers, services like laozhang.ai provide unified API access with consistent pricing, eliminating the complexity of multiple billing accounts while offering potential cost savings through aggregated volume. This approach is particularly valuable when your application uses both Gemini and other providers like OpenAI or Claude, as documented at https://docs.laozhang.ai/.
FAQ and Conclusion
Is Gemini API really free?
Yes, the free tier genuinely provides no-cost access to Gemini models including 2.5 Pro, Flash, Flash-Lite, and 3 Pro Preview. However, after the December 2025 changes, daily limits are restrictive (20-100 requests per day for most models), making it suitable for testing and light personal projects rather than production applications.
How does Gemini pricing compare to OpenAI?
Gemini generally offers more competitive pricing, with Flash-Lite at $0.10/M input compared to GPT-4o-mini at approximately $0.15/M. For comparable capability tiers, Gemini 2.5 Pro at $1.25/M input undercuts GPT-4o at $5.00/M. The comparison favors Gemini significantly on a pure cost basis, though capability differences may justify premium pricing for specific use cases.
What happens when I exceed my quota?
The API returns a 429 status code with a Retry-After header indicating when requests can resume. Rate limits reset on a rolling basis—RPM resets every 60 seconds, while RPD resets at midnight Pacific Time. Implementing exponential backoff in your application handles these gracefully.
Can I upgrade from free to paid tier instantly?
Yes, enabling Cloud Billing in the Google Cloud Console immediately activates Tier 1 access with higher quotas. There's no approval process for Tier 1—you simply connect a payment method and start paying for usage above free tier limits.
Do prompts on the free tier train Google's models?
Yes, data from free tier usage may be used to improve Google products. Paid tiers explicitly exclude your data from training. If data privacy is critical, upgrade to Tier 1 minimum.
How do I monitor my API spending?
Google Cloud Console provides detailed usage dashboards showing requests, tokens, and costs by model. Set up billing alerts at specific thresholds to avoid surprises. The Billing API also enables programmatic cost tracking for integration with your monitoring systems.
Key Takeaways
Understanding Gemini API pricing and quotas empowers you to build cost-effective AI applications. The critical points are that free tier works for testing but has significant limitations post-December 2025, Flash-Lite offers exceptional value at $0.10/M input for high-throughput needs, context caching and batch processing can reduce costs by 50-75%, and Tier 1 requires no approval—just enable billing for immediate quota increases.
For ongoing updates on Gemini API pricing and best practices, explore our comprehensive Gemini API documentation resources or dive deeper into specific topics like rate limit handling and error resolution.