
Picking the right AI API provider is no longer just a technical decision. With OpenAI's GPT-5.4 launching at $2.50 per million input tokens, Google's Gemini 3.1 Pro offering comparable intelligence at $2.00, and Anthropic's Claude Opus 4.6 commanding a premium at $5.00 for its reasoning depth, the per-token prices only tell part of the story. What actually determines your monthly bill is a combination of model choice, workload characteristics, and optimization strategies that most comparison guides completely ignore. This guide provides the latest verified pricing data as of March 2026, calculates real monthly costs for three business scenarios, and delivers a concrete playbook to reduce your API spending by 60-80%.
TL;DR
Google Gemini offers the widest price range from $0.10/MTok (Flash-Lite) to $2.00/MTok (3.1 Pro), making it the most cost-flexible platform with a generous free tier. OpenAI's GPT-5.4 sits at $2.50/$15.00 with the most mature ecosystem and cached input pricing that is approximately ten times cheaper. Claude commands premium pricing (Sonnet 4.6 at $3.00/$15.00, Opus 4.6 at $5.00/$25.00) but delivers superior reasoning quality and 90% cache-hit discounts. For most production workloads, combining model tiering with batch processing and prompt caching reduces costs by 60-80% regardless of which provider you choose.
Complete API Pricing Breakdown (March 2026)
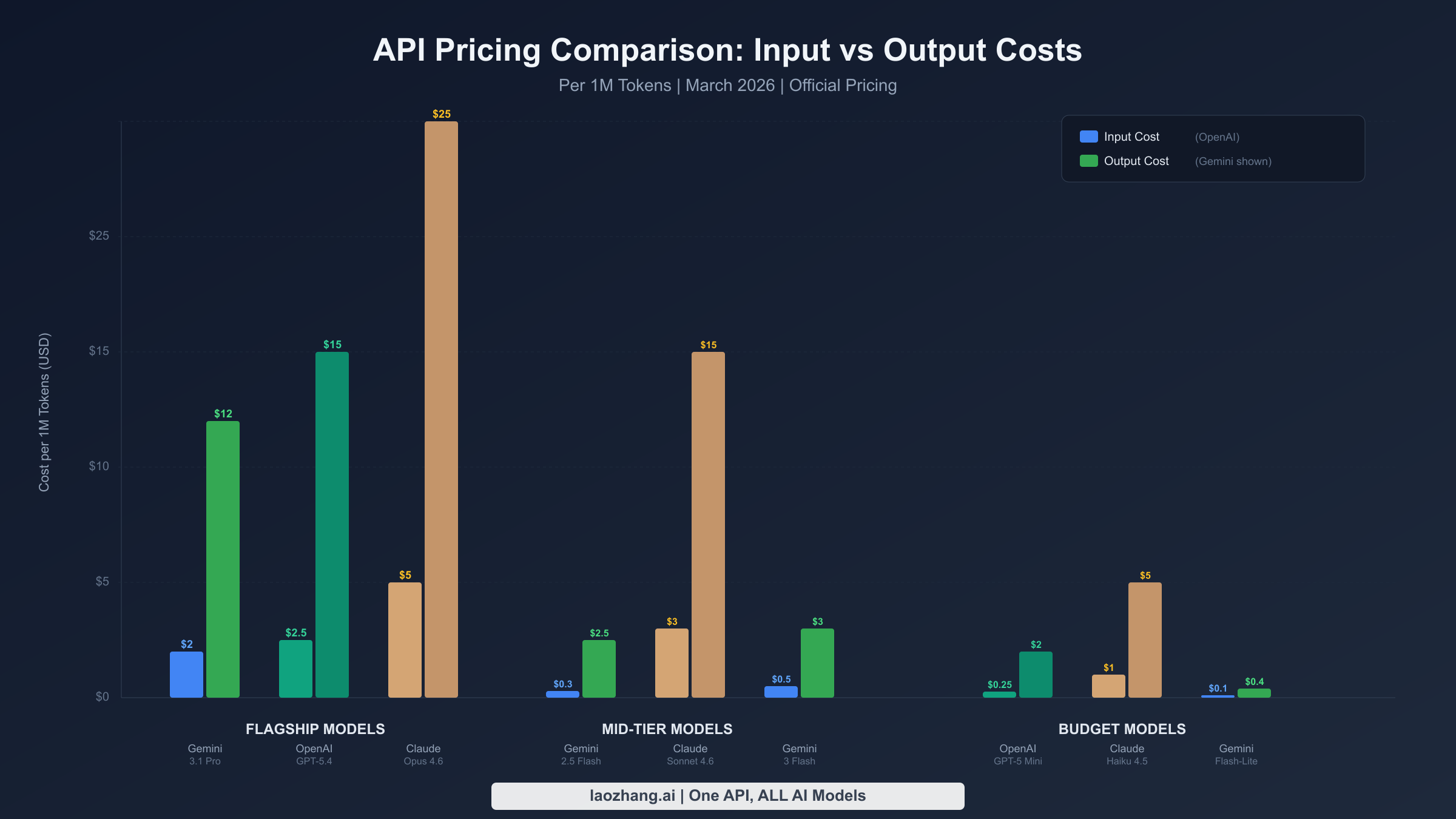
Understanding the full pricing landscape requires looking beyond flagship models. Each provider offers a tiered lineup designed for different quality-to-cost tradeoffs, and the spread between their cheapest and most expensive models often exceeds 50x. The following data was verified against official pricing pages on March 17, 2026, with sources noted for each data point.
Google Gemini has the broadest range of models at remarkably different price points. The recently released Gemini 3.1 Pro Preview charges $2.00 per million input tokens and $12.00 per million output tokens for prompts under 200,000 tokens, stepping up to $4.00 and $18.00 for longer contexts (ai.google.dev, March 2026). On the budget end, Gemini 2.5 Flash-Lite offers production-grade performance at just $0.10 input and $0.40 output per million tokens, making it roughly 20x cheaper than the flagship model. The Gemini 3 Flash Preview sits in the middle at $0.50/$3.00, offering strong reasoning capabilities at a fraction of the Pro price. Perhaps most importantly, Gemini provides a genuinely useful free tier that covers most models, making it the only major provider where you can prototype and run small-scale applications at zero cost. For developers exploring the full range of Gemini API pricing options, the tiered structure means there is almost always a model that fits any budget constraint.
| Model | Input ($/1M) | Output ($/1M) | Batch Input | Batch Output | Context |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | $2.00 / $4.00 | $12.00 / $18.00 | $1.00 / $2.00 | $6.00 / $9.00 | 1M |
| Gemini 3 Flash | $0.50 | $3.00 | $0.25 | $1.50 | 1M |
| Gemini 2.5 Pro | $1.25 / $2.50 | $10.00 / $15.00 | $0.625 / $1.25 | $5.00 / $7.50 | 1M |
| Gemini 2.5 Flash | $0.30 | $2.50 | $0.15 | $1.25 | 1M |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | $0.05 | $0.20 | 1M |
OpenAI positions GPT-5.4 as its current flagship at $2.50 per million input tokens and $15.00 per million output tokens for standard-context use. A significant pricing innovation is the short-versus-long context split: prompts exceeding 272,000 tokens on GPT-5.4 incur 2x input and 1.5x output pricing ($5.00/$22.50), which materially impacts costs for RAG and document analysis workloads. The GPT-5 Mini remains the go-to budget option at $0.25/$2.00, delivering GPT-4-class quality at a fraction of the cost. OpenAI's cached input pricing is its strongest cost advantage, often reducing input costs by approximately 90% for repetitive system prompts, and the Batch API provides a flat 50% discount for all non-real-time processing.
| Model | Input ($/1M) | Output ($/1M) | Cached Input | Batch Discount | Context |
|---|---|---|---|---|---|
| GPT-5.4 (short) | $2.50 | $15.00 | $0.25 | 50% | 1.05M |
| GPT-5.4 (long >272K) | $5.00 | $22.50 | $0.50 | 50% | 1.05M |
| GPT-5 | $1.25 | $10.00 | $0.125 | 50% | 128K |
| GPT-5 Mini | $0.25 | $2.00 | $0.025 | 50% | 128K |
Anthropic Claude occupies the premium tier, with its pricing reflecting the platform's emphasis on reasoning depth and safety. Claude Opus 4.6, the flagship model, costs $5.00 input and $25.00 output per million tokens, making it the most expensive option among the three providers but consistently top-ranked in reasoning benchmarks. Claude Sonnet 4.6 at $3.00/$15.00 offers a compelling middle ground with strong coding and analytical capabilities, while Haiku 4.5 at $1.00/$5.00 provides the entry point. Claude's prompt caching delivers dramatic savings with cache hits priced at just 10% of standard input costs. As we have covered in our Claude API pricing breakdown, the key cost driver is the output-heavy nature of Claude's detailed responses.
| Model | Input ($/1M) | Output ($/1M) | Cache Hit | Cache Write | Context |
|---|---|---|---|---|---|
| Opus 4.6 | $5.00 | $25.00 | $0.50 | $6.25 | 200K |
| Sonnet 4.6 (≤200K) | $3.00 | $15.00 | $0.30 | $3.75 | 200K-1M |
| Haiku 4.5 | $1.00 | $5.00 | $0.10 | $1.25 | 200K |
Real-World Monthly Cost Scenarios
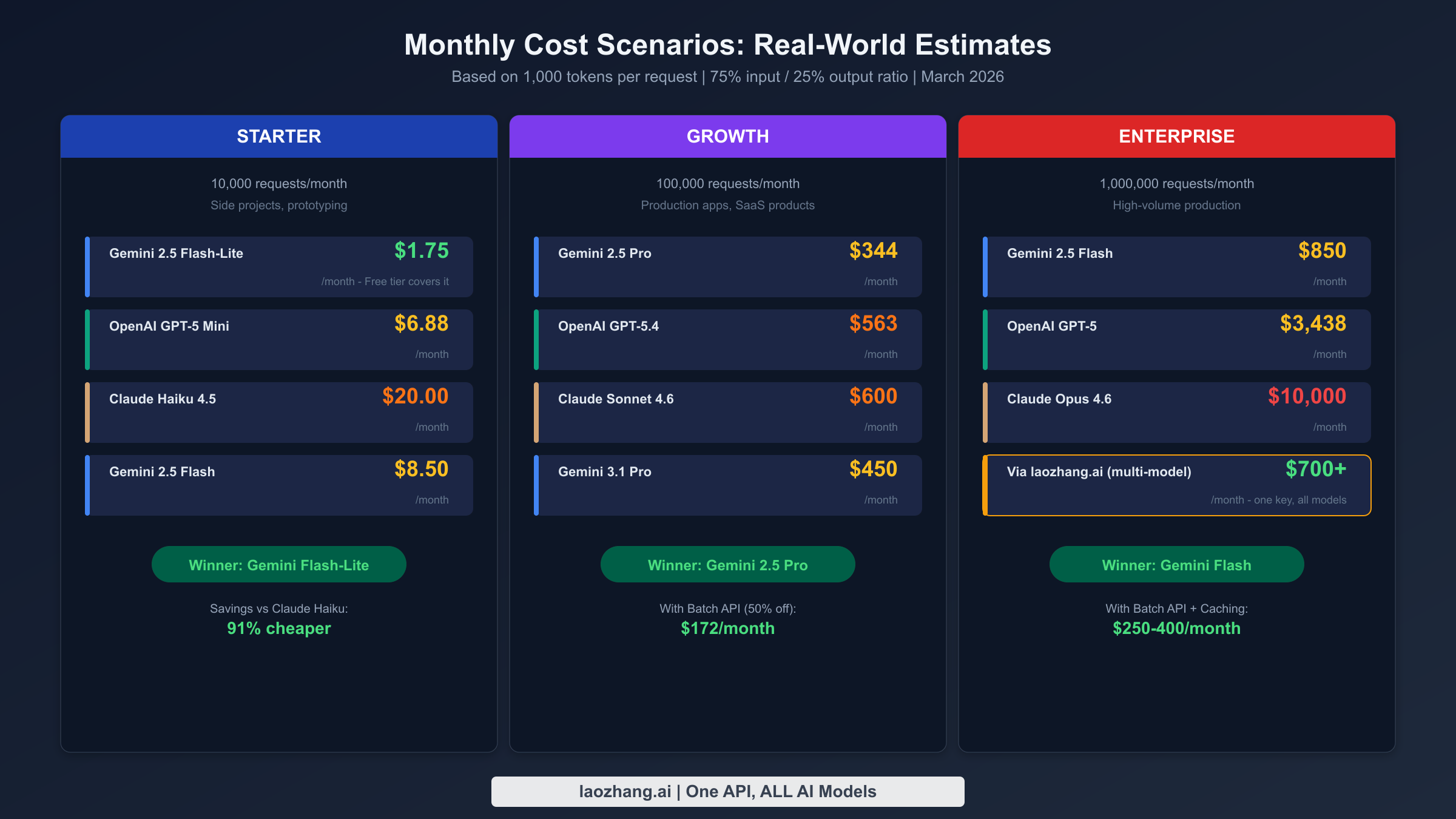
Per-token prices become meaningful only when translated into actual monthly bills. The following scenarios assume 1,000 tokens per request with a 75/25 input-to-output ratio, which represents a typical conversational or analytical workload. These calculations use standard pricing without optimization discounts, providing a baseline that can be dramatically reduced through the strategies covered later in this guide.
Starter Tier (10,000 requests per month) represents individual developers, side projects, and early-stage prototypes. At this scale, Gemini 2.5 Flash-Lite costs approximately $1.75 per month, and the free tier actually covers this entirely. OpenAI GPT-5 Mini runs about $6.88, while Claude Haiku 4.5 comes in at roughly $20.00. The cost differences at this scale are relatively minor in absolute terms, which means you should prioritize model quality and developer experience over raw pricing. If your project is just getting started, Gemini's free tier is an unbeatable entry point, and you can always scale up to paid models as your requirements grow without changing providers.
Growth Tier (100,000 requests per month) is where pricing decisions start to matter significantly. A production application processing 100K requests monthly with a flagship model reveals meaningful cost gaps. Gemini 2.5 Pro costs approximately $344 per month, GPT-5.4 runs around $563, and Claude Sonnet 4.6 reaches $600. These figures assume standard pricing, but the reality is that most production applications should be using batch processing and caching, which can cut these numbers roughly in half. At this tier, the choice between providers often comes down to whether you need Gemini's balance of cost and quality, OpenAI's ecosystem maturity, or Claude's reasoning depth for your specific use case.
Enterprise Tier (1,000,000 requests per month) magnifies every pricing difference into thousands of dollars. Running a million requests through Gemini 2.5 Flash costs approximately $850, GPT-5 comes to around $3,438, and Claude Opus 4.6 reaches $10,000 per month at standard rates. At this scale, model tiering becomes essential. A well-architected system that routes 70% of simple queries to Flash-Lite ($175), 25% to a mid-tier model ($860), and 5% to a premium model ($500) could handle the same workload for roughly $1,535 total, representing a 55-85% reduction depending on the premium model chosen.
Hidden Costs That Change the Equation
The per-token prices displayed on official pricing pages tell an incomplete story. Several cost multipliers remain buried in documentation or only become apparent after significant usage, and failing to account for them can lead to budget overruns of 30-100%. Understanding these hidden costs is critical for accurate financial planning.
Thinking tokens represent the single largest hidden cost for reasoning-intensive workloads. Both Gemini 2.5 Pro and Claude Sonnet 4.6 generate internal reasoning tokens that count toward output pricing but do not appear in the final response. A request that produces a 500-token visible response might actually consume 2,000-5,000 output tokens when thinking is included, effectively multiplying your output costs by 4-10x for complex reasoning tasks. Gemini's pricing pages explicitly state that output pricing includes thinking tokens, and Claude's extended thinking feature works similarly. When budgeting for applications that rely heavily on reasoning, such as code generation, mathematical analysis, or multi-step planning, always multiply your estimated output volume by at least 3x to account for thinking overhead.
Long-context premiums apply to both Gemini and OpenAI when your prompts exceed specific thresholds. Gemini 2.5 Pro and 3.1 Pro both charge 2x input and 1.5x output when prompts exceed 200,000 tokens. OpenAI GPT-5.4 applies a similar 2x/1.5x multiplier beyond 272,000 tokens. For RAG applications and document analysis workflows that regularly process long contexts, this can double your effective per-token costs. Claude, by contrast, maintains flat pricing regardless of context length up to its 200K standard window, making it the most predictable option for long-context workloads.
Search grounding fees add another layer of cost for Gemini users. Gemini 3.x models charge $14 per 1,000 search queries when using Google Search grounding (after the first 5,000 free monthly prompts). For applications that ground every response in web search results, this adds $14 per thousand requests on top of token costs. OpenAI and Claude do not currently offer integrated search grounding at the API level, so this cost is unique to Gemini but also represents a capability that the other providers cannot match.
Which Provider Wins for Your Use Case

Rather than declaring a single winner, the optimal choice depends entirely on your workload characteristics. Each provider has carved out clear advantages in specific domains, and the following recommendations are based on both pricing analysis and real-world performance observations across production deployments.
Customer-facing chatbots and support automation prioritize speed, cost efficiency, and adequate quality for conversational interactions. Gemini 2.5 Flash-Lite at $0.10/$0.40 per million tokens delivers the best economics for high-volume conversational applications, especially when combined with the free tier for development and testing. For applications requiring higher quality responses, Gemini 2.5 Flash at $0.30/$2.50 provides excellent reasoning at a still-affordable price point. The free tier availability means you can validate your chatbot architecture before committing any budget.
RAG and knowledge base applications demand accurate retrieval, faithful summarization, and typically involve processing long document contexts. Gemini 2.5 Pro at $1.25/$10.00 offers the best combination of 1M token context window and reasonable pricing for standard-length prompts, though the 2x premium beyond 200K tokens should be factored into cost projections. Claude Sonnet 4.6 excels at faithfulness and instruction-following in RAG tasks but costs more at $3.00/$15.00. For budget-sensitive RAG deployments, routing the retrieval-augmented queries to Gemini and reserving Claude for synthesis of the most complex retrieved contexts creates an effective hybrid approach.
Code generation and development tools benefit most from strong reasoning and instruction-following capabilities. The Claude Opus 4.6 vs GPT-5 comparison has shown that Claude consistently leads in code generation quality benchmarks. Claude Sonnet 4.6 at $3.00/$15.00 provides the sweet spot of coding capability and cost, making it the most popular choice among developer tool companies. If budget is the primary constraint, Gemini 3 Flash Preview at $0.50/$3.00 delivers surprisingly strong code generation for one-sixth the price.
Agentic workflows and multi-step reasoning require models that can maintain context, plan effectively, and use tools reliably across extended interaction chains. Claude Opus 4.6, despite its premium pricing at $5.00/$25.00, remains the gold standard for agentic applications due to its superior instruction-following and planning capabilities. The thinking tokens overhead makes agentic workloads particularly expensive, but for mission-critical automated workflows, the cost premium is justified by significantly higher task completion rates.
Batch processing and offline analysis should always leverage batch APIs for the straightforward 50% cost reduction. Gemini's batch pricing brings Gemini 2.5 Flash down to $0.15/$1.25, making large-scale document processing remarkably affordable. OpenAI's Batch API applies the same 50% discount across all models with results returned within 24 hours.
Cost Optimization Strategies That Actually Work
Moving from understanding pricing to actively reducing costs requires implementing specific strategies. The following approaches are ranked by impact and implementation difficulty, with concrete calculations showing expected savings.
Model tiering delivers the largest immediate savings for most applications and requires only routing logic changes. The principle is simple: route requests to the cheapest model capable of handling each specific task. A well-designed tiering system sends 70% of straightforward queries to budget models (Flash-Lite at $0.10/$0.40 or GPT-5 Mini at $0.25/$2.00), 25% of moderate-complexity tasks to mid-tier models (Gemini 2.5 Flash at $0.30/$2.50 or Claude Sonnet at $3.00/$15.00), and only 5% of genuinely complex reasoning tasks to premium models (Opus at $5.00/$25.00 or GPT-5.4 at $2.50/$15.00). For a 100K request workload that would cost $600 on Claude Sonnet alone, tiering reduces the bill to approximately $160, a 73% saving.
Batch API processing provides a guaranteed 50% discount on both input and output tokens for any request that does not require real-time responses. All three providers now offer batch processing: Gemini explicitly shows batch pricing across every model, OpenAI provides a flat 50% discount with 24-hour SLA, and Claude offers similar batch capabilities. For data processing pipelines, content analysis, and scheduled generation tasks, there is almost no reason not to use batch pricing. If 40% of your workload can tolerate delayed processing, batch API alone cuts your total bill by 20%.
Prompt caching transforms the economics of applications with repetitive system prompts. Claude's prompt caching system reduces cache-hit input costs to just 10% of standard pricing, while Gemini's context caching offers similar reductions with additional storage-based pricing. If your application uses a 4,000-token system prompt across all requests, caching that prompt saves roughly 90% on those input tokens. For a 100K request application, this translates to approximately $300-500 in monthly savings depending on the model.
API aggregation platforms like laozhang.ai offer a pragmatic solution for teams that want to use multiple providers without managing separate API keys, billing accounts, and integration code. These platforms provide a single OpenAI-compatible API endpoint that routes requests to any model from Gemini, OpenAI, or Claude, with competitive pricing that often matches or undercuts direct provider rates. Beyond pricing, the operational benefit is significant: one API key gives you instant access to every model, and you can switch between providers without code changes. For teams evaluating multiple models or running hybrid architectures, the reduced integration overhead and vendor flexibility typically justify the aggregation approach.
Making Your Decision: Practical Next Steps
The volume of pricing data and optimization strategies can feel overwhelming, but the decision framework is actually straightforward when you focus on your primary constraints.
If cost is your primary constraint, start with Gemini. The free tier lets you validate your application without any spending, and the progression from Flash-Lite ($0.10/$0.40) through Flash ($0.30/$2.50) to Pro ($1.25/$10.00) provides natural upgrade paths as your quality requirements grow. Gemini also offers the most aggressive batch pricing, bringing already-affordable models down to remarkably low per-token costs.
If quality and reasoning are paramount, invest in Claude. Sonnet 4.6 offers the best quality-to-cost ratio for applications that demand accurate, nuanced, and well-reasoned outputs. The prompt caching system makes repeat interactions significantly cheaper, and the 1M extended context beta opens possibilities for long-document analysis that other providers cannot match at similar quality levels. The $20 per month Pro subscription also includes generous usage for prototyping.
If ecosystem and tooling matter most, OpenAI remains the safest choice. The broadest third-party integration support, the most mature SDK ecosystem, and the largest community of developers mean faster development velocity. The cached input pricing (10x cheaper) and Batch API (50% off) provide strong cost optimization levers, and GPT-5.4's pricing at $2.50/$15.00 is competitive with Gemini's flagship.
For teams building production applications that require flexibility, exploring an API aggregation platform like laozhang.ai provides the ability to test all three providers through a single integration point. With pricing that matches direct provider rates and instant model switching capabilities, it eliminates the vendor lock-in risk that comes with committing to a single provider early. You can get started at docs.laozhang.ai with credits starting from just $5.
Frequently Asked Questions
Which AI API is cheapest in 2026?
Google Gemini 2.5 Flash-Lite at $0.10 input and $0.40 output per million tokens is the cheapest production-ready API from a major provider as of March 2026. When combined with the batch API (50% discount), it drops to $0.05/$0.20, and the free tier covers small-scale usage at zero cost. OpenAI's GPT-5 Mini at $0.25/$2.00 is the cheapest OpenAI option, while Claude Haiku 4.5 at $1.00/$5.00 is Anthropic's most affordable model.
How much does it cost to run 100,000 API requests per month?
Monthly costs for 100K requests (assuming 1,000 tokens each, 75/25 input-output ratio) range from approximately $18 with Gemini Flash-Lite to $1,000 with Claude Opus 4.6. The most popular mid-tier options cost $344 (Gemini 2.5 Pro), $563 (GPT-5.4), and $600 (Claude Sonnet 4.6). Applying batch API and caching optimizations typically reduces these by 40-60%.
Do thinking tokens affect API costs?
Yes, significantly. Both Gemini 2.5 Pro and Claude's models generate internal reasoning tokens that are billed at output token rates but do not appear in the visible response. For reasoning-heavy tasks, thinking tokens can multiply your effective output costs by 3-10x. Always monitor actual token consumption through your provider's usage dashboard rather than estimating based on response length alone.
Is it worth switching from OpenAI to Gemini to save money?
For cost-sensitive workloads, switching to Gemini can reduce API costs by 30-70% depending on your current model usage. The trade-off is that Gemini's model quality, while rapidly improving, may differ from OpenAI's for specific use cases. A practical approach is to route cost-sensitive bulk operations to Gemini while keeping quality-critical flows on your current provider. API aggregation platforms make this hybrid approach straightforward to implement.
How can I reduce my AI API costs by 50% or more?
Three strategies combined typically achieve 60-80% cost reduction: (1) Model tiering routes 70% of requests to budget models, saving 40-60%. (2) Batch API processing provides a flat 50% discount for non-real-time workloads. (3) Prompt caching reduces repetitive input costs by 75-90%. Start with model tiering as it requires no API changes, just routing logic.