
As of March 21, 2026, GPT-5 nano is still the cheapest option, but GPT-5.4 nano is usually the better cheap OpenAI API default for new workloads. That is the short answer. The current GPT-5 nano model page still makes a clear case for ultra-cheap summarization and classification. But that same page now says that for most new speed- and cost-sensitive workloads, OpenAI recommends starting with GPT-5.4 nano. Once you line up the current prices, cutoff dates, tool support, and workflow fit, the split becomes easier to understand: use GPT-5 nano when absolute minimum token cost is the point, and use GPT-5.4 nano when you want the better modern cheap lane.
The important nuance is that this is not a normal "newer model costs more, but maybe it is also bigger" comparison. Both models currently list the same 400,000-token context window, the same 128,000 max output, and the same published rate limits on their official model pages. So the choice is not really about throughput ceilings or context size. It is about whether saving 4x on token price is worth giving up a much newer knowledge cutoff, a higher reasoning posture, and a better tool surface for low-cost workers.
TL;DR
| Model | Best for | Why you pick it | Main tradeoff |
|---|---|---|---|
| GPT-5 nano | Bare-bones summarization, cheap classification, and traffic where the absolute lowest token bill matters most | It is far cheaper than GPT-5.4 nano on input, cached input, and output pricing | Older May 31, 2024 cutoff and a thinner cheap-agent tool surface |
| GPT-5.4 nano | New extraction, ranking, helper-agent, and modern low-cost workflow lanes | OpenAI now routes most new speed- and cost-sensitive workloads here, and it adds newer knowledge plus better tools without reducing context or rate limits | Around 4x the token price of GPT-5 nano |
If you want one practical rule, use this one: keep GPT-5 nano for the narrow cases where ultra-low cost is the main product requirement. Start with GPT-5.4 nano when you are building a new cheap lane and still want the lane to feel current.
Why This Comparison Is Really "Absolute Cheapest" vs "Better Current Default"
At first glance, this keyword looks like a tiny version bump. Both names end in "nano." Both are small OpenAI models. Both sit on the cheap end of the product ladder. That makes it easy to assume the only real difference is a modest pricing change.
The current docs show something more important than that. GPT-5 nano is still live, still priced, and still useful. OpenAI describes it as the fastest, most cost-efficient version of GPT-5 and says it is great for summarization and classification tasks. That part is real. But the same GPT-5 nano page also says that for most new speed- and cost-sensitive workloads, OpenAI recommends starting with GPT-5.4 nano instead. The latest GPT-5.4 guide pushes in the same direction by saying that for smaller, faster variants developers should start with gpt-5.4-mini or gpt-5.4-nano.
That wording changes the nature of the comparison. GPT-5 nano is no longer the obvious future-facing cheap default. It is the model you keep because your work is simple enough and cost-sensitive enough that the cheaper branch still makes sense. GPT-5.4 nano is the model you start with when you want a cheap lane that still feels aligned with OpenAI's current routing story.
That is why the right question is not "which nano is better?" The right question is "am I optimizing for the absolute minimum token bill, or for the better current cheap lane?"
Pricing, Freshness, Tools, and Rate Limits Side by Side

The biggest surprise in this comparison is not the price gap. It is how cleanly the price gap lines up against the capability and freshness gap.
According to the official model pages checked on March 21, 2026, GPT-5 nano costs $0.05 per 1M input tokens, $0.005 cached input, and $0.40 per 1M output tokens. GPT-5.4 nano costs $0.20 input, $0.02 cached input, and $1.25 output. On simple arithmetic, GPT-5 nano is much cheaper across the board. For teams that run huge volumes of short classification or summarization requests, that difference is not cosmetic.
But the price savings do not come with a better cutoff, better model age, or a richer worker tool surface. GPT-5 nano lists a May 31, 2024 knowledge cutoff. GPT-5.4 nano lists Aug 31, 2025. That is a large freshness gap for a cheap lane that may still touch evolving APIs, libraries, and product behavior. GPT-5.4 nano also supports hosted shell, apply patch, skills, and distillation on its current model page, while GPT-5 nano does not. If your cheap lane is text-only, that may not matter. If your cheap lane is starting to do agent-adjacent work, it matters a lot.
| Spec | GPT-5.4 nano | GPT-5 nano |
|---|---|---|
| Input price | $0.20 / 1M tokens | $0.05 / 1M tokens |
| Cached input | $0.02 / 1M tokens | $0.005 / 1M tokens |
| Output price | $1.25 / 1M tokens | $0.40 / 1M tokens |
| Context window | 400,000 | 400,000 |
| Max output | 128,000 | 128,000 |
| Knowledge cutoff | Aug 31, 2025 | May 31, 2024 |
| Reasoning level shown on model page | High | Average |
| Snapshot shown on model page | gpt-5.4-nano-2026-03-17 | gpt-5-nano-2025-08-07 |
| Hosted shell | Yes | No |
| Apply patch | Yes | No |
| Skills | Yes | No |
| Distillation support | Yes | No |
| MCP | Yes | Yes |
| Image generation | Yes | Yes |
| Tier 1 limits | 500 RPM / 200,000 TPM | 500 RPM / 200,000 TPM |
| Tier 5 limits | 30,000 RPM / 180,000,000 TPM | 30,000 RPM / 180,000,000 TPM |
The rate-limit rows are what make the comparison especially clear. If GPT-5 nano had a much higher throughput ceiling, the decision would be messier. Right now, the official pages say both models share the same current rate limits and the same context size. That means the tradeoff is not "cheaper but slower" or "cheaper but smaller context." It is "cheaper but older and thinner" versus "more expensive but more current and more capable."
What OpenAI's Current Routing Language Actually Implies
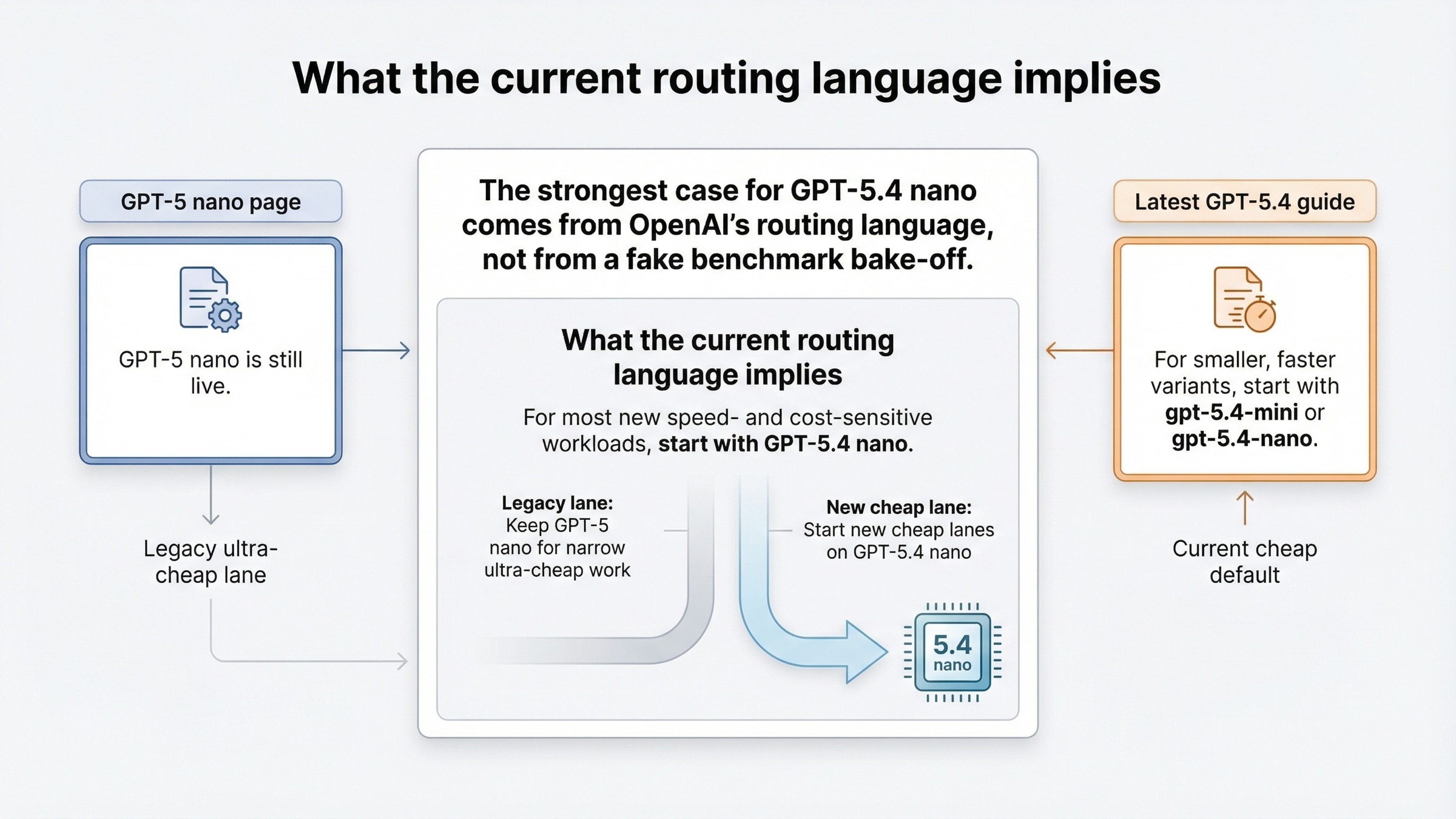
OpenAI has not published one perfect benchmark table that puts GPT-5.4 nano and GPT-5 nano side by side on every metric. That matters, and the article should be honest about it. The strongest current case for GPT-5.4 nano is not a made-up benchmark bake-off. It is OpenAI's own routing language plus the spec differences on the model pages.
The most important sentence in the whole topic is on the GPT-5 nano page itself: for most new speed- and cost-sensitive workloads, OpenAI recommends starting with GPT-5.4 nano. If OpenAI were treating GPT-5 nano as the current default cheap model, that sentence would not exist. Instead, the company is effectively telling you that GPT-5 nano still has a place, but that place is narrower than it used to be.
The latest-model guide pushes the same conclusion from the other direction. It says that for smaller, faster variants, developers should start with gpt-5.4-mini or gpt-5.4-nano. That does not automatically mean GPT-5 nano is obsolete. It means GPT-5 nano is no longer the branch OpenAI is steering new cheap-lane design toward.
The March 17, 2026 GPT-5.4 mini and nano launch post reinforces that positioning. It treats GPT-5.4 nano as a real low-cost model for classification, data extraction, ranking, and simpler subagents, not as a stripped-down fallback that exists only to be cheap. The older August 2025 GPT-5 for developers launch post still explains why GPT-5 nano matters: it was built to be the cheapest GPT-5 branch and it still delivers that. But in the current product tree, the older nano page reads more like a legacy ultra-cheap lane than like the recommended place to start.
That difference is why this comparison should not be written as a generic spec recap. The reader needs to understand that OpenAI's own recommendation has shifted, even though GPT-5 nano still exists and still has a rational use case.
When GPT-5 Nano Is Still The Better Choice
GPT-5 nano is still the better choice when the cheap lane is supposed to be brutally simple and brutally inexpensive.
The clearest case is high-volume summarization and lightweight classification where the answer quality is already good enough and the product math is dominated by token cost. If the workload is narrow, prompt-stable, and measured, cutting the bill to one quarter of GPT-5.4 nano's input cost and less than one third of its output cost can easily matter more than getting a newer cutoff or a better reasoning posture.
The second case is cost-capped background traffic. Some systems have a cheap lane whose whole purpose is to handle the easy work as cheaply as possible before a harder lane takes over. In that architecture, GPT-5 nano can still make sense if the lane is not doing agent-style work and if recent world knowledge is not a major requirement.
The third case is legacy confidence. Teams sometimes keep a cheaper older branch because its behavior is already known and the margin structure is built around it. That can be rational. But it should be a measured choice, not a naming-based assumption. The OpenAI Developer Community has already had threads about prompt-caching behavior on GPT-5 nano and GPT-5 mini, which is a good reminder that low-cost routing decisions depend on production testing, not only on a price row.
Use GPT-5 nano if most of these are true:
- Your workload is mainly summarization, light classification, or another well-bounded text task.
- Absolute minimum token cost matters more than newer knowledge or richer cheap-agent tools.
- The lane does not need hosted shell, apply patch, skills, or distillation.
- You already know the prompts and failure modes well enough that a legacy cheap branch is acceptable.
That is still a real set of workloads. It is just narrower than "most new cheap builds."
When GPT-5.4 Nano Is Worth Paying For
GPT-5.4 nano is worth paying for when the cheap lane still needs to feel modern.
The first strong case is extraction, ranking, and helper-agent work where the output has to be structured, the edge cases are messy, and newer knowledge helps. OpenAI explicitly positions GPT-5.4 nano for classification, data extraction, ranking, and sub-agents. That matters because those are exactly the workloads where a cheap model often stops being "just a cheap model" and starts being part of a real system.
The second case is any cheap lane that needs a better tool surface. Hosted shell, apply patch, skills, and distillation support are not cosmetic checkboxes. They expand what a low-cost worker can do inside an agentic stack. If your cheap lane is just a fast text function, GPT-5 nano may still be enough. If the lane needs to participate in a richer workflow, GPT-5.4 nano is much easier to justify.
The third case is freshness-sensitive cheap work. The cutoff gap between May 31, 2024 and Aug 31, 2025 is large. A cheap lane that touches recent documentation, newer libraries, or late-2025 product behavior will start with a meaningfully better baseline on GPT-5.4 nano.
The fourth case is new architecture. If you are designing a system now rather than defending an old one, it is hard to ignore the official routing guidance. OpenAI is telling developers where to start for most new speed- and cost-sensitive workloads. You do not have to obey that blindly, but you should treat it as a serious default and make GPT-5 nano prove that the extra savings are worth the tradeoff.
Use GPT-5.4 nano if most of these are true:
- You are building a new cheap lane rather than preserving an old one.
- The work includes extraction, ranking, subagents, or other structured helper tasks.
- A newer cutoff reduces real product risk.
- The lane benefits from hosted shell, apply patch, skills, or distillation.
- You want the cheap branch to fit OpenAI's current product direction instead of its older cheapest branch.
If the cheap lane is starting to feel heavier than that, your next comparison may actually be GPT-5.4 mini vs GPT-5.4 nano, not GPT-5.4 nano versus GPT-5 nano.
How To Choose For Your Stack
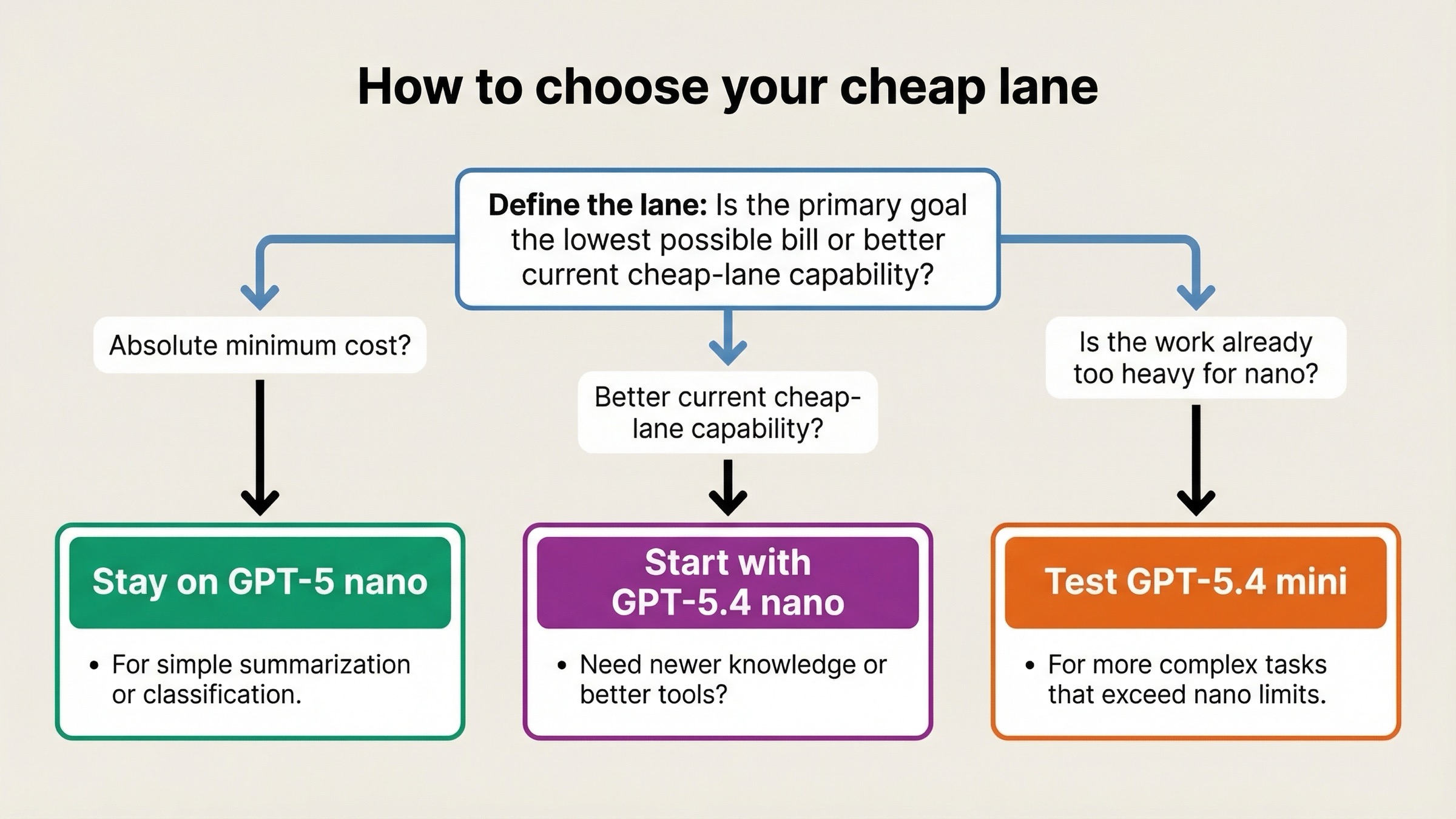
The simplest way to make this decision is to ask one question first: is this lane defined by cost minimization or by current cheap capability?
If the answer is cost minimization, start with GPT-5 nano and benchmark upward only if the errors become expensive. If the answer is current cheap capability, start with GPT-5.4 nano and benchmark downward only if the price gap is harder than the quality gap.
My practical rule looks like this:
- Choose GPT-5 nano when the lane is text-heavy, simple, and built around the lowest possible bill.
- Choose GPT-5.4 nano when the lane is still cheap, but the work is modern enough that newer knowledge and better tools matter.
- If GPT-5.4 nano still feels underpowered for your cheap lane, stop comparing it to GPT-5 nano and move the evaluation up to GPT-5.4 mini vs GPT-5.4 nano.
If you are still getting your API environment ready, our OpenAI API key guide covers the setup side. If your real question is whether the new nano branch or the older mini branch makes more sense, read GPT-5.4 nano vs GPT-5 mini next.
FAQ
Is GPT-5 nano deprecated?
No. As of March 21, 2026, GPT-5 nano still has a live model page, live pricing, and live rate limits. The point is not that it disappeared. The point is that OpenAI no longer treats it as the default starting point for most new cheap workloads.
Is GPT-5.4 nano 4x better because it costs 4x more?
Not in a simple one-number sense, and OpenAI does not publish one clean benchmark table that proves that exact ratio. The better reason to pay for GPT-5.4 nano is that it gives you a newer cutoff, a higher reasoning posture, and a broader cheap-agent tool surface while keeping the same context and current rate limits.
What is the strongest reason to keep GPT-5 nano?
The strongest reason is still price. If the workload is simple, stable, and huge in volume, GPT-5 nano's lower input, cached-input, and output cost can matter more than the newer model's advantages.
What is the strongest reason to move to GPT-5.4 nano?
The strongest reason is that you want a cheap lane that still feels current. OpenAI routes new speed- and cost-sensitive workloads there, and the model gives you better freshness plus better cheap-agent tooling without reducing throughput ceilings.
The shortest honest conclusion is this: GPT-5 nano still wins when the absolute lowest bill is the product requirement. GPT-5.4 nano wins when you want the better cheap default for new work.