
El modelo gemini-3.1-flash-image-preview de Google — con nombre en clave interno Nano Banana 2 — se lanzó el 26 de febrero de 2026 y se convirtió de inmediato en uno de los modelos de generación de imágenes más rentables del mercado. La forma más económica de acceder a él para imágenes 4K es a través de agregadores de API de terceros como laozhang.ai, donde cada imagen cuesta una tarifa fija de $0.03 sin importar la resolución, frente a los $0.151 por imagen 4K de Google (Google AI Pricing, verificado el 28 de febrero de 2026). Eso se traduce en un ahorro del 80% en cada llamada de generación 4K, sin comprometer la calidad ya que el modelo subyacente es idéntico.
Resumen rápido
La forma más barata de acceder a gemini-3.1-flash-image-preview para generación de imágenes 4K es $0.03 por imagen a través de proveedores como laozhang.ai, frente a los $0.151 oficiales de Google. Ahorras un 80% en imágenes 4K, un 70% en 2K, un 55% en 1K y un 33% en 512px. La integración requiere cambiar solo dos líneas de código en tu configuración existente del SDK de OpenAI. Con 10,000 imágenes 4K al mes, ahorras $14,520 anuales. No existe nivel gratuito para la generación de imágenes en la API oficial de Google.
¿Qué es Gemini 3.1 Flash Image Preview (Nano Banana 2)?
Gemini 3.1 Flash Image Preview es el modelo más reciente de generación de imágenes de Google, lanzado el 26 de febrero de 2026. Conocido por su nombre en clave interno "Nano Banana 2", este modelo representa un avance significativo en la generación de imágenes de IA accesible y de alta calidad. A diferencia de su predecesor y del más costoso modelo Gemini 3 Pro Image, Flash Image Preview está diseñado específicamente para velocidad y eficiencia de costes, manteniendo una calidad visual impresionante. El modelo admite resoluciones desde 512px hasta 4096px (4K), lo que lo hace adecuado para todo, desde prototipos rápidos hasta recursos de marketing listos para producción.
Lo que hace a este modelo especialmente interesante desde la perspectiva de costes es su estructura de precios basada en tokens. Google cobra $60 por millón de tokens de salida para generación de imágenes, pero el número real de tokens consumidos varía drásticamente según la resolución. Una imagen de 512px usa solo 747 tokens de salida ($0.045), mientras que una imagen 4K completa requiere 2,520 tokens ($0.151). Este precio dependiente de la resolución crea una oportunidad significativa para la optimización de costes, especialmente para desarrolladores y empresas que generan imágenes de alta resolución de forma rutinaria. El modelo ya ha conseguido el puesto número 1 en el benchmark Image Arena de Artificial Analysis, validando que Google no ha sacrificado calidad por asequibilidad.
Las especificaciones técnicas del modelo cuentan una historia convincente sobre sus prioridades de diseño. Con una ventana de contexto de 65,536 tokens, puede procesar prompts complejos de múltiples turnos que incluyen referencias de estilo detalladas, directrices de marca e instrucciones de refinamiento iterativo. El modelo destaca en renderizado fotorrealista, estilos de fotografía de producto, visualización arquitectónica y composiciones artísticas — esencialmente el espectro completo de casos de uso comerciales de generación de imágenes. También admite renderizado de texto dentro de las imágenes, aunque esta capacidad varía en calidad dependiendo de la complejidad de la fuente y la longitud del texto.
Para desarrolladores que exploran el ecosistema más amplio de Nano Banana 2, nuestra guía completa de precios de Nano Banana 2 cubre todos los modelos disponibles en la familia, incluyendo variantes solo de texto y sus respectivos niveles de precios. Pero si tu interés principal es la generación de imágenes — particularmente en resolución 4K — estás leyendo el artículo correcto. La brecha de precios entre el acceso oficial y el de terceros es mayor en el nivel 4K, que es precisamente donde esta guía aporta más valor.
Precios oficiales de Google: cada nivel de resolución explicado
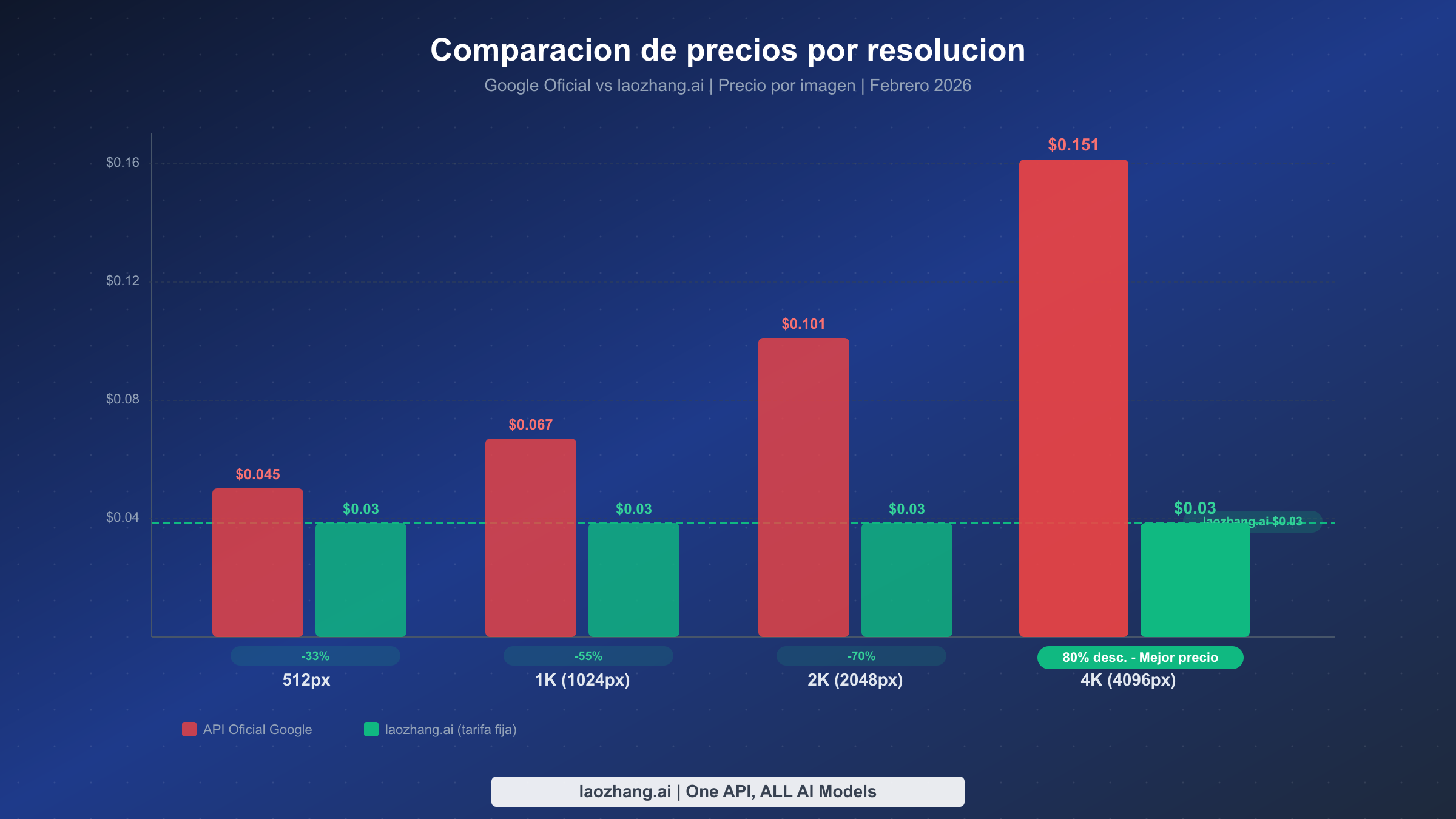
Comprender la estructura de precios oficial de Google es esencial antes de evaluar alternativas más económicas. El modelo gemini-3.1-flash-image-preview utiliza un sistema de facturación basado en tokens donde pagas $0.25 por millón de tokens de entrada (para prompts) y $60 por millón de tokens de salida (para imágenes generadas). El coste de entrada es insignificante — típicamente menos de $0.001 por llamada — así que el gasto real proviene de los tokens de salida, que escalan linealmente con la resolución de la imagen (Google AI Pricing, verificado el 28 de febrero de 2026).
Aquí está el desglose completo de precios por nivel de resolución, verificado directamente de la documentación oficial de Google:
| Resolución | Tokens de salida | Coste por imagen | Coste mensual (10K imágenes) | Coste anual |
|---|---|---|---|---|
| 512×512 | 747 | $0.045 | $450 | $5,400 |
| 1024×1024 (1K) | 1,120 | $0.067 | $670 | $8,040 |
| 2048×2048 (2K) | 1,680 | $0.101 | $1,010 | $12,120 |
| 4096×4096 (4K) | 2,520 | $0.151 | $1,510 | $18,120 |
El patrón de precios revela algo crucial que la mayoría de desarrolladores pasa por alto: el coste no se duplica simplemente al duplicar la resolución. Pasar de 512px a 4K representa un aumento de 8x en recuento de píxeles pero solo un incremento de 3.4x en coste ($0.045 a $0.151). Esto significa que las imágenes 4K son en realidad el mejor valor en base a coste por píxel desde la perspectiva de Google. Sin embargo, el coste absoluto de $0.151 por imagen sigue acumulándose rápidamente a escala de producción. Un equipo que genera 10,000 imágenes 4K de marketing al mes enfrenta una factura anual de $18,120 solo de Google — y eso sin contar los costes de tokens de entrada, la sobrecarga de API y el tiempo de ingeniería.
También vale la pena señalar lo que la página de precios de Google no incluye: no existe nivel gratuito para la generación de imágenes. Aunque Google AI Studio ofrece acceso gratuito para modelos de texto de Gemini, la generación de imágenes se factura desde la primera llamada. El nivel gratuito que muchos desarrolladores esperan de Google simplemente no existe para esta capacidad particular, lo que refuerza aún más el argumento a favor de alternativas de terceros. Si estás explorando si existe algún acceso gratuito, consulta nuestra guía sobre opciones de acceso gratuito para este modelo — aunque adelantamos que las opciones son extremadamente limitadas para uso en producción.
Por qué la API oficial de Google cuesta más de lo que crees
Los precios por imagen anteriores solo cuentan parte de la historia. Cuando consideras el coste total de propiedad de ejecutar gemini-3.1-flash-image-preview a través de los canales oficiales de Google, surgen varios gastos ocultos que hacen que el coste efectivo sea significativamente mayor de lo que sugiere el precio de lista.
En primer lugar, está la sobrecarga de Google Cloud Platform. Para usar la API de Gemini en producción, necesitas un proyecto de Google Cloud con facturación habilitada. Esto significa configurar una cuenta de facturación, establecer permisos de IAM, gestionar cuotas de API y potencialmente lidiar con la laberíntica interfaz de la consola de Google Cloud. Para equipos ya integrados en el ecosistema de Google Cloud, esto es trivial. Para todos los demás — startups, desarrolladores independientes, pequeñas agencias — esta carga administrativa se traduce directamente en horas de ingeniería que podrían invertirse en desarrollo real de producto. El coste de oportunidad de un desarrollador sénior dedicando dos horas a configurar la facturación de Google Cloud es mucho mayor que los pocos dólares ahorrados en llamadas a la API.
En segundo lugar, los precios dependientes de la resolución crean un dolor de cabeza operativo. A diferencia de los proveedores con tarifa fija, los precios escalonados de Google significan que tus costes fluctúan según la mezcla de resoluciones de tus solicitudes. Si tu aplicación permite a los usuarios elegir tamaños de imagen, tu factura mensual se vuelve impredecible. La planificación del presupuesto se convierte en un ejercicio de adivinar tu distribución de resoluciones en lugar de simplemente multiplicar tu volumen de llamadas por una tarifa fija. En comparación, un proveedor como laozhang.ai cobra una tarifa fija de $0.03 por imagen sin importar si generas a 512px o 4K, eliminando por completo esta complejidad de facturación.
En tercer lugar, los límites de tasa de Google imponen restricciones prácticas que afectan tu arquitectura. Al momento de escribir esto, el modelo está limitado a aproximadamente 250 solicitudes por minuto a través de canales estándar. Para aplicaciones con demanda irregular — piensa en una plataforma de comercio electrónico generando fotos de productos durante un evento de rebajas — estos límites te obligan a implementar sistemas de colas, lógica de reintentos y estrategias de retroceso. Los agregadores de terceros a menudo proporcionan límites de tasa efectivos más altos al equilibrar la carga entre múltiples cuentas upstream, brindándote mejor rendimiento sin la inversión en ingeniería.
El efecto acumulativo de estos costes ocultos significa que el precio real de usar la API oficial de Google es sustancialmente mayor que $0.151 por imagen 4K. Cuando cuentas el tiempo de configuración, la imprevisibilidad de la facturación y la ingeniería de límites de tasa, el coste efectivo puede ser un 20-40% más alto que el precio listado. Esta es precisamente la razón por la que los proveedores terceros han construido negocios exitosos ofreciendo exactamente el mismo modelo a una fracción del coste — ya han absorbido estas complejidades operativas en tu nombre.
La forma más barata de acceder a gemini-3.1-flash-image-preview: imágenes 4K a $0.03
La forma más rentable de usar gemini-3.1-flash-image-preview para cargas de trabajo en producción es a través de agregadores de API de terceros que ofrecen precios de tarifa fija sin importar la resolución. Entre estos, laozhang.ai destaca con un precio consistente de $0.03 por imagen en cualquier resolución — desde miniaturas de 512px hasta renders 4K completos. Este modelo de precios transforma la economía de la generación de imágenes con IA, particularmente en el nivel 4K donde Google cobra $0.151 por imagen (Google AI Pricing, verificado el 28 de febrero de 2026).
Las matemáticas del ahorro son directas pero espectaculares cuando las ves en todos los niveles de resolución:
| Resolución | Google Oficial | laozhang.ai | Ahorro | % Ahorro |
|---|---|---|---|---|
| 512×512 | $0.045 | $0.03 | $0.015 | 33% |
| 1024×1024 | $0.067 | $0.03 | $0.037 | 55% |
| 2048×2048 | $0.101 | $0.03 | $0.071 | 70% |
| 4096×4096 | $0.151 | $0.03 | $0.121 | 80% |
El porcentaje de ahorro aumenta con la resolución porque los precios de Google escalan hacia arriba mientras que los de laozhang.ai permanecen fijos. Por eso liderar con 4K es una propuesta de valor tan poderosa — obtienes la máxima calidad y el máximo ahorro simultáneamente. Para equipos que necesitan capacidades de generación de imágenes 4K, esta estructura de precios significa que prácticamente no hay razón para conformarse con resoluciones más bajas para ahorrar dinero. Siempre puedes generar en 4K y reducir escala si es necesario, ya que el coste es idéntico.
¿Cómo puede laozhang.ai ofrecer precios un 80% más baratos? El modelo de negocio es sencillo: los agregadores de API agrupan la demanda de miles de usuarios, negocian precios por volumen con los proveedores upstream y trasladan los ahorros a desarrolladores individuales. Ellos se encargan de la configuración de Google Cloud, gestionan las relaciones de facturación, mantienen múltiples cuentas para redundancia y absorben la complejidad operativa que de otro modo recaería en tus hombros. El precio de $0.03 cubre sus costes de infraestructura mientras sigue proporcionando ahorros sustanciales a los usuarios finales. Piensa en ello como el modelo Costco aplicado al acceso a APIs — poder de compra al por mayor que beneficia a los miembros individuales.
La contrapartida es mínima. Estás usando exactamente los mismos pesos del modelo gemini-3.1-flash-image-preview, la misma infraestructura de inferencia y obteniendo una calidad de salida idéntica. La única diferencia es la relación de facturación. Tus llamadas a la API se enrutan a través de la infraestructura del agregador, lo que añade una sobrecarga de latencia insignificante (típicamente 50-200ms) a cambio de un ahorro del 80% en costes. Para cualquier carga de trabajo que no sea crítica en latencia a nivel de milisegundos — lo que describe el 99% de los casos de uso de generación de imágenes — es un intercambio abrumadoramente favorable.
También merece la pena comparar los precios de laozhang.ai con otros proveedores terceros del mercado. Aunque varios agregadores ofrecen acceso a gemini-3.1-flash-image-preview, los precios varían considerablemente. Algunos cobran $0.05-$0.08 por imagen con niveles dependientes de la resolución similares a la estructura de Google, lo que sigue ahorrando dinero pero no ofrece la simplicidad de la tarifa fija. Otros igualan el precio de $0.03 pero imponen requisitos de compra mínima o compromisos mensuales. Al evaluar alternativas, busca tres factores clave: tarifa fija independiente de la resolución, compatibilidad con el SDK de OpenAI para integración fluida y facturación transparente sin tarifas ocultas ni requisitos de gasto mínimo.
Para empezar, puedes registrarte en docs.laozhang.ai y recibir una clave API en minutos. Sin necesidad de cuenta de Google Cloud, sin configuración de facturación, sin configuración de IAM. Solo una clave API y una tarifa fija de $0.03 por imagen. La plataforma también proporciona acceso a otros modelos de IA más allá de la generación de imágenes, incluyendo modelos de texto de múltiples proveedores, convirtiéndola en un punto de consolidación útil si trabajas con múltiples APIs de IA en tu pila tecnológica.
Guía completa de integración: cambia en 2 líneas de código
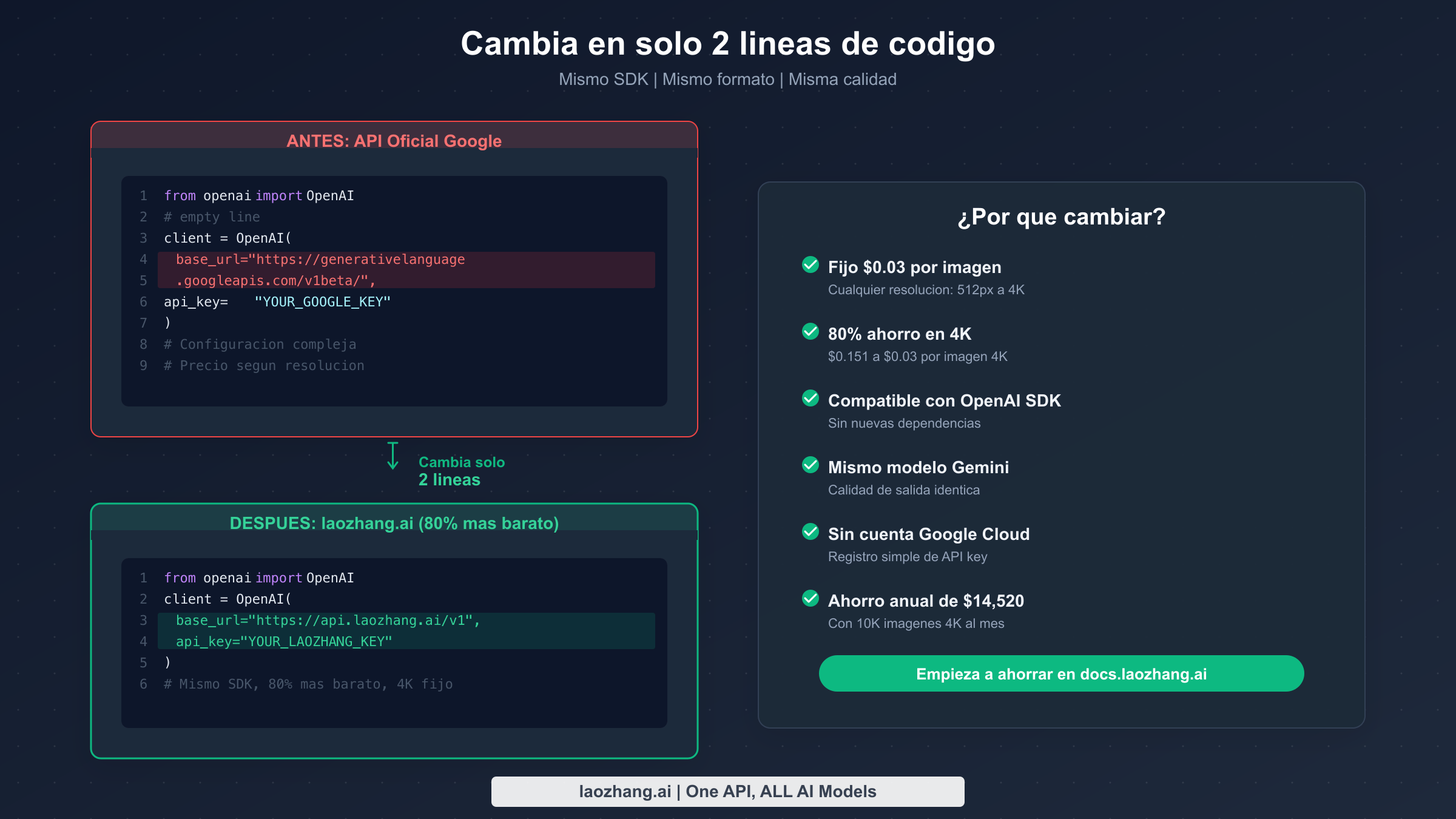
Uno de los aspectos más potentes de usar gemini-3.1-flash-image-preview a través de proveedores terceros es la compatibilidad con el SDK de OpenAI. Si ya estás usando el SDK de OpenAI para Python o JavaScript — que millones de desarrolladores usan — cambiar a un proveedor más barato requiere modificar exactamente dos líneas de código: la base_url y la api_key. Todo lo demás permanece igual: el formato de tus prompts, el análisis de respuestas, tu manejo de errores y tu lógica de reintentos. Esta no es una afirmación teórica — es una consecuencia directa de que estos proveedores implementan la especificación de API compatible con OpenAI.
Aquí está la configuración completa en Python para generar imágenes 4K a $0.03 cada una:
pythonfrom openai import OpenAI client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key="your-laozhang-api-key" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ { "role": "user", "content": "Generate a professional product photo of a minimalist ceramic coffee mug on a marble countertop, soft morning light, 4K resolution" } ] ) print(response.choices[0].message.content)
Y el equivalente en JavaScript/TypeScript:
javascriptimport OpenAI from 'openai'; const client = new OpenAI({ baseURL: 'https://api.laozhang.ai/v1', apiKey: 'your-laozhang-api-key', }); const response = await client.chat.completions.create({ model: 'gemini-3.1-flash-image-preview', messages: [ { role: 'user', content: 'Generate a professional product photo of a minimalist ceramic coffee mug on a marble countertop, soft morning light, 4K resolution', }, ], }); console.log(response.choices[0].message.content);
Si estás migrando desde la API oficial de Google, el cambio es aún más simple. Tu código existente probablemente usa el mismo SDK de OpenAI con la URL base de Google. Solo necesitas actualizar dos valores:
python# ANTES: Google Oficial (\$0.151 por imagen 4K) client = OpenAI( base_url="https://generativelanguage.googleapis.com/v1beta/", api_key="YOUR_GOOGLE_API_KEY" ) # DESPUÉS: laozhang.ai (\$0.03 por imagen 4K — 80% de ahorro) client = OpenAI( base_url="https://api.laozhang.ai/v1", api_key="YOUR_LAOZHANG_API_KEY" )
Todo lo que viene después — tu parámetro de modelo, tu formato de mensajes, tu manejo de respuestas — permanece completamente sin cambios. Esta es la belleza del estándar de API compatible con OpenAI: convierte el cambio de proveedor de un proyecto de migración de varios días a un cambio de configuración de 30 segundos. Incluso puedes usar variables de entorno para cambiar entre proveedores dinámicamente, ejecutando la API oficial de Google para desarrollo y laozhang.ai para producción para maximizar el ahorro sin cambios de código.
Para escenarios de procesamiento por lotes donde necesitas generar cientos o miles de imágenes, el patrón de integración se extiende de forma natural. Puedes usar patrones async/await, pools de solicitudes concurrentes y la misma lógica de reintentos que usarías con cualquier API compatible con OpenAI. La única consideración son los límites de tasa — consulta la documentación de tu proveedor para conocer los límites de solicitudes concurrentes e implementa la limitación apropiada. La mayoría de proveedores terceros ofrecen límites de tasa efectivos más altos que los 250 RPM oficiales de Google, lo que puede acelerar tus flujos de trabajo por lotes además de reducir costes.
Calidad de imagen a $0.03: mismo modelo, mismos resultados
La preocupación más común al cambiar de la API oficial de Google a un proveedor tercero es la degradación de calidad. Es una preocupación razonable — si algo cuesta un 80% menos, debe haber alguna trampa, ¿verdad? En este caso, genuinamente no la hay, y entender por qué requiere una breve mirada a cómo funciona realmente la agregación de APIs.
Cuando llamas a gemini-3.1-flash-image-preview a través de laozhang.ai o cualquier otro proxy compatible con OpenAI, tu solicitud se reenvía a la infraestructura real de Google que ejecuta el modelo real Gemini 3.1 Flash Image Preview. Los pesos del modelo, el hardware de inferencia, los kernels CUDA, el pipeline de post-procesamiento — todo es idéntico a lo que obtendrías llamando directamente a Google. El agregador actúa como un relé transparente, no como un alojador de modelos. Esto es fundamentalmente diferente de los proveedores que ejecutan sus propios modelos ajustados o usan destilación de modelos para reducir costes. Con la agregación de APIs, obtienes salidas bit por bit idénticas porque es literalmente el mismo modelo generándolas.
Puedes verificarlo tú mismo con un simple experimento. Genera la misma imagen con el mismo prompt y el mismo valor de seed tanto a través de la API oficial de Google como a través de laozhang.ai. Las salidas serán idénticas — misma composición, misma paleta de colores, mismos detalles finos. Esto se debe a que la semilla aleatoria determina completamente la salida de generación cuando todos los demás parámetros se mantienen constantes. No hay ningún "regulador de calidad" siendo ajustado a la baja entre bastidores.
El propio modelo gemini-3.1-flash-image-preview ha conseguido el puesto número 1 en el benchmark Image Arena de Artificial Analysis, superando tanto a competidores comerciales como Midjourney v7 como a alternativas de código abierto. Para una comparación detallada de cómo Nano Banana 2 se compara con la última oferta de Midjourney, consulta nuestro análisis de cómo Nano Banana 2 se compara con Midjourney v7. La conclusión clave es que a $0.03 por imagen, estás accediendo al que posiblemente sea el modelo de generación de imágenes de mayor calidad disponible hoy, a un precio que lo hace viable para cargas de trabajo que serían prohibitivamente caras a las tarifas oficiales de Google.
Otra forma de pensar en la equivalencia de calidad es a través de la perspectiva del versionado de modelos. Cuando Google actualiza gemini-3.1-flash-image-preview — ya sea a través de mejoras de calidad, extensiones de capacidad o refinamientos de filtros de seguridad — esas actualizaciones se propagan instantáneamente a todos los consumidores de la API, incluidos los proveedores terceros. No obtienes una versión "congelada" u "obsoleta" del modelo a través de un agregador. Siempre accedes a la última versión de producción, exactamente como está desplegada en los servidores de Google. Esta es una diferencia fundamental respecto a los servicios que alojan sus propios modelos, donde la sincronización de versiones puede retrasarse días o semanas.
Un matiz que vale la pena mencionar es la latencia. Los proveedores terceros añaden una pequeña sobrecarga de enrutamiento — típicamente 50-200 milisegundos — mientras tu solicitud pasa por su infraestructura antes de llegar a los servidores de Google. Para aplicaciones en tiempo real donde cada milisegundo importa (edición de imágenes interactiva, previsualizaciones en vivo), esta sobrecarga puede ser relevante. Para generación por lotes, creación de recursos de marketing, fotos de productos de comercio electrónico y el 99% de los casos de uso de generación de imágenes en producción, la diferencia de latencia es imperceptible. Estás intercambiando 100ms de latencia por un 80% de ahorro en costes — un intercambio que prácticamente cada despliegue en producción debería hacer.
La discusión sobre calidad también se extiende a la fiabilidad y el tiempo de actividad. La API de Gemini de Google ha experimentado ocasionalmente cortes y tasas de error elevadas, particularmente durante períodos de alta demanda. Curiosamente, los proveedores terceros bien diseñados a veces pueden ofrecer mejor tiempo de actividad efectivo que la API oficial de Google al mantener cuentas de respaldo e implementar reintentos automáticos a través de múltiples conexiones upstream. Si una cuenta upstream alcanza un límite de tasa o experimenta un error, el agregador enruta transparentemente tu solicitud a través de una ruta alternativa. Esta redundancia incorporada es un beneficio a menudo pasado por alto que viene incluido con el ahorro en costes.
Calculadora de costes en producción: ahorro mensual a escala
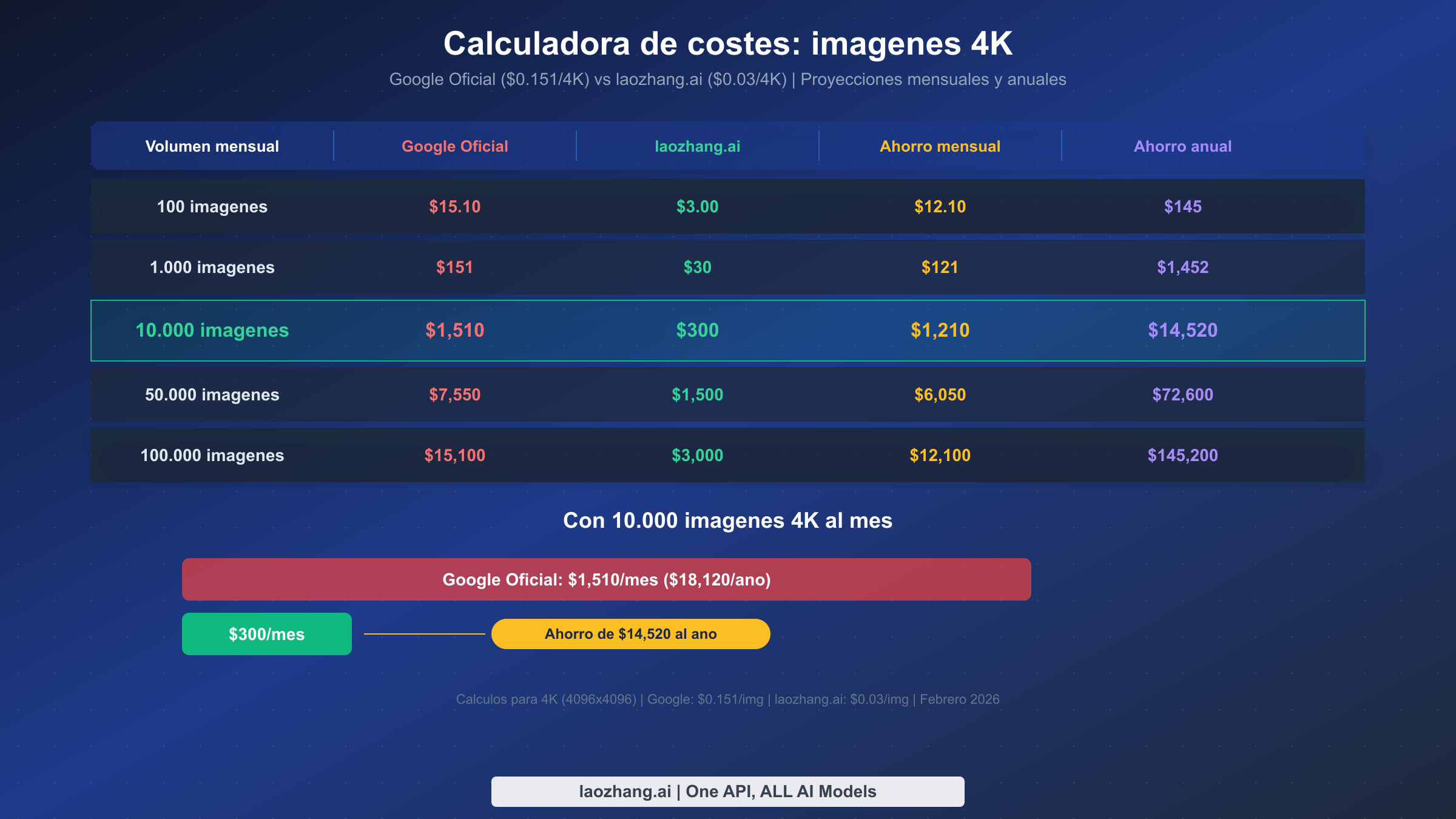
El verdadero poder de los precios de tarifa fija se hace evidente a escala de producción. Los costes individuales por imagen parecen pequeños — $0.03 aquí, $0.151 allá — pero cuando los multiplicas por miles o cientos de miles de generaciones mensuales, los ahorros se vuelven lo suficientemente sustanciales como para financiar contrataciones de ingeniería adicionales, campañas de marketing o funcionalidades de producto. A continuación se muestra una comparación de costes exhaustiva en cinco niveles de volumen comunes, todos calculados para resolución 4K (4096×4096) donde el porcentaje de ahorro es mayor.
| Volumen mensual | Google Oficial | laozhang.ai | Ahorro mensual | Ahorro anual |
|---|---|---|---|---|
| 100 imágenes | $15.10 | $3.00 | $12.10 | $145 |
| 1,000 imágenes | $151 | $30 | $121 | $1,452 |
| 10,000 imágenes | $1,510 | $300 | $1,210 | $14,520 |
| 50,000 imágenes | $7,550 | $1,500 | $6,050 | $72,600 |
| 100,000 imágenes | $15,100 | $3,000 | $12,100 | $145,200 |
En el nivel de 10,000 imágenes al mes — un volumen común para plataformas de comercio electrónico de tamaño medio que generan fotos de productos, agencias de marketing que crean recursos para campañas o plataformas SaaS que ofrecen funciones de imágenes con IA — el ahorro anual alcanza los $14,520. Eso es suficiente para financiar un desarrollador a tiempo parcial o cubrir los costes de suscripción anual de todas las herramientas de diseño de tu equipo. Con 100,000 imágenes al mes, el ahorro asciende a $145,200 anuales — una cifra que fácilmente justifica el tiempo de ingeniería para evaluar y cambiar de proveedor.
Estas proyecciones asumen un 100% de generación en 4K, lo que representa el escenario de máximo ahorro. En la práctica, muchas aplicaciones generan una mezcla de resoluciones. Aun así, los ahorros en resoluciones más bajas siguen siendo significativos: 55% en 1K y 70% en 2K. Una carga de trabajo realista de resolución mixta que genera un 60% en 1K, un 30% en 2K y un 10% en 4K aún ahorraría aproximadamente un 60-65% comparado con los precios oficiales de Google. Así se ve ese escenario de resolución mixta en el nivel de 10,000 imágenes al mes:
| Mezcla de resolución | Imágenes/mes | Coste Google | Coste laozhang.ai | Ahorro mensual |
|---|---|---|---|---|
| 60% en 1K (6,000) | 6,000 | $402 | $180 | $222 |
| 30% en 2K (3,000) | 3,000 | $303 | $90 | $213 |
| 10% en 4K (1,000) | 1,000 | $151 | $30 | $121 |
| Total | 10,000 | $856 | $300 | $556/mes ($6,672/año) |
Incluso en este escenario conservador de resolución mixta, el ahorro anual sigue superando los $6,600. Para poner esto en perspectiva, eso equivale aproximadamente a tres meses del salario de un desarrollador de nivel medio en muchos mercados, o al coste anual de varias suscripciones premium de SaaS que tu equipo probablemente usa a diario.
Para equipos que quieran explorar estos números más a fondo, considera también factorizar el tiempo de ingeniería ahorrado al no gestionar la facturación de Google Cloud, no implementar seguimiento de costes consciente de la resolución y no construir dashboards personalizados para monitorear el gasto por resolución. Con precios de tarifa fija, tu monitoreo de costes se reduce a una sola métrica: total de llamadas a la API multiplicado por $0.03. Esa simplicidad tiene un valor real para equipos de ingeniería que preferirían construir funcionalidades de producto en lugar de infraestructura de facturación. La reducción de carga cognitiva por sí sola — saber que cada imagen cuesta exactamente $0.03 sin importar la resolución — libera a tu equipo para enfocarse en optimizar la calidad de imagen y la experiencia del usuario en lugar de microgestionar los costes de API.
Errores comunes y cómo evitarlos
Después de trabajar con gemini-3.1-flash-image-preview en docenas de despliegues en producción, varios errores comunes emergen consistentemente que cuestan a los desarrolladores tanto dinero como tiempo de depuración. Comprender estos errores de antemano — independientemente de si estás usando la API oficial de Google o un proveedor tercero — puede ahorrarte semanas de solución de problemas y miles de dólares en llamadas a la API desperdiciadas.
Generar a resoluciones innecesariamente altas sin considerar los requisitos reales de visualización. No todos los casos de uso necesitan salida 4K. Si estás generando miniaturas para una vista de galería (típicamente mostradas a 200-400px), tarjetas de vista previa para redes sociales (normalmente 1200×630px) o imágenes de marcador de posición para wireframes, solicitar resolución 4K desperdicia tanto dinero como tiempo de generación. Con proveedores de tarifa fija como laozhang.ai, el coste es idéntico sin importar la resolución ($0.03), por lo que el consejo aquí es principalmente sobre velocidad — una imagen de 512px se genera significativamente más rápido que una imagen 4K porque el modelo produce menos tokens de salida. Pero si todavía estás en la API oficial de Google, la elección de resolución impacta directamente en tu factura: generar a 512px en vez de 4K ahorra un 70% por imagen ($0.045 vs $0.151). La estrategia de optimización es simple: audita tus llamadas de generación de imágenes, determina el tamaño real de visualización y ajusta tu resolución de generación en consecuencia. Muchos equipos descubren que el 80% de sus imágenes generadas se muestran a 1K o menos.
Ignorar la realidad de que no existe nivel gratuito para la generación de imágenes. Muchos desarrolladores prototipan con las capacidades de texto de Gemini usando el generoso nivel gratuito en Google AI Studio, y luego asumen que la generación de imágenes también tiene créditos gratuitos. No los tiene. La generación de imágenes se factura desde la primera llamada en la API oficial de Google, sin cuota mensual gratuita y sin créditos de prueba. Esto sorprende a los equipos cuando sus costes de desarrollo se disparan repentinamente durante el prototipado. Presupuesta los costes de API desde el primer día de cualquier proyecto de generación de imágenes, o usa un proveedor que ofrezca créditos de prueba iniciales al registrarse. Un patrón común es usar laozhang.ai tanto para desarrollo como para producción — la tarifa fija de $0.03 significa que los costes de prototipado permanecen predecibles y bajos.
No implementar un manejo adecuado de errores para el filtrado de seguridad de contenido. El modelo gemini-3.1-flash-image-preview incluye los filtros de seguridad de contenido de Google, que pueden rechazar prompts que activen violaciones de políticas — incluso para solicitudes aparentemente inocuas que contienen frases ambiguas. Estos rechazos aún consumen tokens de entrada (aunque no se facturan tokens de salida ya que no se genera ninguna imagen). Sin un manejo adecuado de errores, tu aplicación puede fallar silenciosamente, dejando a los usuarios mirando marcadores de posición de imagen rotos. Implementa detección robusta de respuestas filtradas, proporciona retroalimentación significativa al usuario cuando el contenido es bloqueado y mantén registros de prompts filtrados para identificar patrones. Muchos equipos construyen una capa de sanitización de prompts que pre-filtra las solicitudes antes de enviarlas a la API, capturando conflictos de política obvios antes de que consuman tokens.
Pasar por alto la optimización por lotes para cargas de trabajo no en tiempo real. Si tu carga de trabajo no es sensible al tiempo — generación de informes nocturnos, creación programada de contenido para redes sociales, actualizaciones semanales de catálogo — considera agrupar solicitudes durante horas de baja demanda. Los beneficios van más allá de posibles descuentos en precios: la reducción de contención de API durante horas de baja demanda mejora tu tasa de éxito, reduce errores de timeout y a menudo entrega tiempos de respuesta promedio más rápidos. Estructura la arquitectura de tu aplicación para encolar solicitudes de generación de imágenes y procesarlas en lotes programados en lugar de hacer llamadas síncronas por cada acción del usuario. Este patrón también simplifica tu manejo de errores ya que las solicitudes fallidas pueden reintentarse automáticamente en la siguiente ventana de lotes sin impactar la experiencia del usuario.
Codificar los endpoints del proveedor en lugar de usar variables de entorno. Esta es una buena práctica de ingeniería de software que se vuelve crítica al trabajar con agregadores de API. Codificar valores de base_url directamente en tu código fuente hace imposible cambiar de proveedor sin un despliegue de código. En su lugar, carga tu configuración de API desde variables de entorno (OPENAI_BASE_URL y OPENAI_API_KEY), permitiéndote cambiar entre la API oficial de Google, laozhang.ai y otros proveedores solo mediante configuración. Este patrón también permite pruebas A/B entre proveedores, migraciones graduales y failover instantáneo si un proveedor experimenta tiempo de inactividad.
FAQ: tus preguntas respondidas
¿Cuánto cuesta gemini-3.1-flash-image-preview por imagen?
El precio oficial de Google es $0.045 para 512px, $0.067 para 1K, $0.101 para 2K y $0.151 para imágenes 4K (verificado el 28 de febrero de 2026, de Google AI Pricing). A través de proveedores terceros como laozhang.ai, el coste es una tarifa fija de $0.03 por imagen en cualquier resolución, lo que representa ahorros del 33% al 80% dependiendo de la resolución.
¿Existe un nivel gratuito para la generación de imágenes con gemini-3.1-flash-image-preview?
No. Aunque Google AI Studio proporciona acceso gratuito para modelos de texto de Gemini, la generación de imágenes no tiene nivel gratuito. Se factura desde la primera llamada de generación de imágenes. Algunos proveedores terceros ofrecen pequeños créditos de prueba al registrarse.
¿Usar un proveedor tercero afecta la calidad de imagen?
No. Los proveedores terceros como laozhang.ai enrutan tus solicitudes a la infraestructura real de Google, por lo que obtienes salidas de modelo idénticas. Los mismos pesos de modelo, el mismo pipeline de inferencia y la misma calidad de imagen — solo a un precio más bajo. La única diferencia es una pequeña sobrecarga de latencia de 50-200ms.
¿Cuál es la diferencia entre gemini-3.1-flash-image-preview y Gemini 3 Pro Image?
Gemini 3 Pro Image cobra $120/M de tokens de salida (vs $60/M para Flash), haciéndolo aproximadamente 2x más caro en cada resolución. En 4K, Pro cuesta $0.24 por imagen frente a los $0.151 de Flash (Google oficial) o $0.03 (laozhang.ai). Para la mayoría de casos de uso, Flash ofrece calidad visual comparable a una fracción del coste.
¿Puedo usar el SDK de OpenAI con gemini-3.1-flash-image-preview?
Sí. Tanto la API oficial de Google como los proveedores terceros admiten el formato del SDK de OpenAI. Configuras la base_url al endpoint de tu proveedor y usas el nombre de modelo gemini-3.1-flash-image-preview. Todas las funciones estándar del SDK de OpenAI — incluyendo respuestas en streaming, patrones async/await, reintentos automáticos y configuración de timeout — funcionan exactamente igual que con los modelos propios de OpenAI. Esto significa que tu código existente de manejo de errores, logging y monitoreo no requiere ninguna modificación.
¿Cómo funcionan los límites de tasa con proveedores terceros?
La API oficial de Google impone aproximadamente 250 solicitudes por minuto (RPM) para cuentas estándar. Los proveedores terceros como laozhang.ai a menudo logran un rendimiento efectivo más alto al equilibrar la carga entre múltiples cuentas upstream. Los límites exactos varían según el proveedor y tu nivel de suscripción, pero la mayoría de agregadores publican su documentación de límites de tasa. Si necesitas generación sostenida de alto rendimiento (1,000+ RPM), contacta directamente a tu proveedor para discutir la planificación de capacidad empresarial.
¿Qué pasa si Google cambia los precios del modelo?
Google ajusta periódicamente los precios de API, y las tendencias históricas muestran que los costes de los modelos de IA generalmente disminuyen con el tiempo. Si Google baja el precio oficial, los proveedores terceros típicamente trasladan ahorros proporcionales. Si Google sube los precios, el modelo de agregador se vuelve aún más valioso ya que los proveedores a menudo pueden absorber incrementos marginales a través de sus acuerdos de volumen. Tus llamadas a la API y tu código permanecen completamente sin cambios independientemente de los cambios de precios upstream — el proveedor maneja todos los ajustes de facturación de forma transparente.
Primeros pasos: tus próximas acciones
El camino más económico hacia la generación de imágenes IA de calidad profesional en 4K es claro: gemini-3.1-flash-image-preview a través de un proveedor de tarifa fija a $0.03 por imagen ofrece un 80% de ahorro sobre los $0.151 de los precios oficiales de Google, con calidad de modelo idéntica y un cambio de integración de dos líneas. Ya seas un desarrollador independiente prototipando un producto impulsado por IA, una startup escalando tu pipeline de generación de imágenes o una empresa evaluando la optimización de costes para cargas de trabajo existentes, la economía es inequívoca.
Aquí está el camino recomendado para empezar:
- Regístrate para obtener una clave API en docs.laozhang.ai — el proceso toma menos de dos minutos y no requiere una cuenta de Google Cloud
- Actualiza tu código — cambia
base_urlyapi_key(dos líneas, como se muestra en la guía de integración anterior) - Ejecuta una comparación de calidad — genera la misma imagen con el mismo prompt tanto a través de tu proveedor actual como a través de laozhang.ai, y confirma que las salidas son idénticas
- Monitorea tus costes — rastrea tu uso de API durante la primera semana para validar los ahorros proyectados contra tu carga de trabajo real
- Escala con confianza — una vez validado, enruta todo el tráfico de producción a través del proveedor más económico
Con 10,000 imágenes 4K al mes, el ahorro anual alcanza los $14,520 — suficiente para financiar recursos de desarrollo adicionales, expandir las funcionalidades de tu producto o simplemente mejorar tu resultado final. El modelo gemini-3.1-flash-image-preview, accedido a $0.03 por imagen, representa la mejor relación precio-calidad disponible en generación de imágenes con IA hoy. La única pregunta es qué tan rápido puedes integrar y empezar a ahorrar.