Los límites de velocidad de Claude Code se presentan en dos versiones completamente diferentes, y confundirlos es la razón número uno por la que los desarrolladores pierden tiempo aplicando la solución incorrecta. Ya sea que estés viendo un mensaje genérico de "límite de uso alcanzado" en tu plan Pro o un error HTTP 429 preciso desde la API, esta guía te ayudará a identificar el cuello de botella exacto, aplicar la solución correcta y construir hábitos que eviten que los límites interrumpan tu flujo de trabajo nuevamente.
Resumen rápido
Claude Code aplica dos sistemas de límites independientes: cuotas de suscripción (ventanas rotativas de 5 horas en planes Pro y Max, compartidas con Claude.ai) y límites de velocidad de la API (topes de RPM/ITPM/OTPM por minuto vinculados a tu nivel de gasto). La solución más rápida para los límites de suscripción es esperar al reinicio de la ventana de 5 horas o actualizar a Max. Para los límites de la API, implementa retroceso exponencial, utiliza el caché de prompts para reducir el consumo efectivo de tokens hasta en un 80%, o enruta las solicitudes a través de un servicio de API de terceros como laozhang.ai que cobra por token sin límites por minuto.
¿Por qué Claude Code alcanza límites de velocidad? (Dos sistemas separados)

Lo más importante que debes entender sobre los límites de velocidad de Claude Code es que existen dos sistemas completamente separados que controlan cuánto puedes usar la herramienta. La mayoría de las guías de solución de problemas en línea confunden estos dos sistemas, lo que lleva a los desarrolladores por caminos equivocados que desperdician un tiempo de programación valioso. Comprender qué sistema te está limitando determina si la solución tarda cinco segundos o cinco minutos.
Sistema 1 — Cuotas de suscripción se aplican cuando usas Claude Code a través de un plan de pago (Pro a $20/mes, Max 5x a $100/mes, o Max 20x a $200/mes, según aparece en la página de precios de Anthropic, verificado en marzo de 2026). Estas cuotas miden tu uso total durante una ventana rotativa de 5 horas y se comparten entre Claude.ai chat y Claude Code. Cuando agotas tu cuota de suscripción, Claude Code muestra un mensaje suave como "límite de uso alcanzado" o "has alcanzado tu límite por ahora" en lugar de un código de error HTTP estándar. El detalle clave aquí es que los modelos más pesados consumen tu cuota más rápido — Opus 4.6 consume aproximadamente cinco veces más recursos que Sonnet 4.6 para la misma longitud de conversación, lo que explica por qué los usuarios del plan Max que usan Opus por defecto pueden alcanzar los límites sorprendentemente rápido.
Sistema 2 — Límites de velocidad de la API entran en acción cuando tú (o una herramienta en tu nombre) realizas llamadas directas a la API de mensajes de Anthropic. Estos límites se miden en solicitudes por minuto (RPM), tokens de entrada por minuto (ITPM) y tokens de salida por minuto (OTPM). Están vinculados al nivel de gasto de tu organización API en lugar de tu plan de suscripción, y devuelven un código de respuesta HTTP 429 estándar con un encabezado retry-after cuando se exceden. La API utiliza un algoritmo de bucket de tokens (documentado en la página de límites de velocidad de Anthropic, verificado en marzo de 2026), lo que significa que tu capacidad se rellena continuamente en lugar de reiniciarse en intervalos fijos.
Estos dos sistemas operan de manera independiente. Puedes estar bien dentro de tus límites de velocidad de la API mientras tu cuota de suscripción está agotada, o viceversa. Un desarrollador que recientemente actualizó de Pro a Max 5x podría ver desaparecer los límites de suscripción solo para descubrir que ahora está alcanzando los topes de ITPM del nivel API porque las conversaciones de múltiples turnos de Claude Code agrupan prompts del sistema, contenido de archivos y tokens de uso de herramientas en cada solicitud. Si tienes curiosidad sobre cómo encaja el nivel gratuito de Claude Code en este panorama, el plan gratuito tiene límites aún más estrictos en ambos frentes.
Límites de suscripción — Cuotas de Pro, Max 5x y Max 20x
Los límites de suscripción son los que la mayoría de los usuarios de Claude Code encuentran primero, porque cada plan de pago incluye acceso a Claude Code y las cuotas se comparten entre todos los productos de Claude. Cuando Anthropic introdujo cuotas semanales el 28 de agosto de 2025 — un cambio cubierto extensamente por medios como TechCrunch — la comunidad de desarrolladores experimentó un cambio significativo en la agresividad con la que podían depender de Claude Code para sesiones de programación prolongadas.
La siguiente tabla resume los niveles de suscripción actuales para usuarios individuales (verificado desde claude.com/pricing e informes de terceros, marzo de 2026):
| Plan | Precio mensual | Mensajes aprox. / 5 horas | Modelos disponibles | Umbral de degradación automática |
|---|---|---|---|---|
| Gratuito | $0 | Muy limitado (varía según demanda) | Sonnet, Haiku | N/A |
| Pro | $20 ($17/mes anual) | ~45 mensajes | Sonnet 4.6 | N/A |
| Max 5x | $100 | ~225 mensajes (5x Pro) | Sonnet 4.6, Opus 4.6 | Opus a Sonnet al 20% de uso |
| Max 20x | $200 | ~900 mensajes (20x Pro) | Sonnet 4.6, Opus 4.6 | Opus a Sonnet al 50% de uso |
Varios detalles críticos determinan cómo se sienten estos límites en la práctica. Primero, la métrica de "mensajes" es aproximada porque la huella de tokens de cada interacción varía enormemente dependiendo del tamaño del contexto de tu base de código, el número de archivos incluidos en la conversación y si Claude Code ejecuta llamadas a herramientas como lecturas de archivos o comandos bash. Una pregunta simple sobre un solo archivo podría consumir una "unidad de mensaje" mientras que una tarea de refactorización compleja que toca docenas de archivos podría consumir el equivalente a diez o más mensajes en un solo turno.
Segundo, el comportamiento de degradación automática en los planes Max es tanto una bendición como una frustración. Cuando tu uso de Opus alcanza el umbral (20% en Max 5x, 50% en Max 20x), Claude Code cambia automáticamente a Sonnet para las interacciones posteriores. Esto preserva tu cuota restante para trabajo más ligero, pero puede sentirse brusco cuando la calidad de razonamiento del modelo baja notablemente a mitad de sesión. Puedes anular esto con el comando /model, pero hacerlo consumirá tu cuota restante mucho más rápido.
Tercero, y esto toma desprevenidos a muchos usuarios, tu cuota de suscripción se comparte entre Claude.ai web chat y Claude Code. Si pasaste la mañana teniendo conversaciones largas en la interfaz de Claude.ai, tu cuota de Claude Code para la tarde se reducirá proporcionalmente. Los equipos donde un miembro maneja tanto la investigación (vía chat) como la implementación (vía Claude Code) a menudo descubren esto de la manera difícil.
La controversia de enero de 2026 merece un examen cuidadoso porque revela cómo los límites de suscripción pueden sentirse impredecibles incluso cuando técnicamente se comportan según lo diseñado. Después de que Anthropic duplicó los límites de uso como promoción navideña del 25 al 31 de diciembre de 2025, muchos usuarios reportaron lo que parecía una reducción de aproximadamente el 60% en los límites cuando las cuotas normales se reanudaron el 1 de enero. Anthropic aclaró que los límites volvieron a su línea base estándar, pero el contraste hizo que los límites normales se sintieran restrictivos — un fenómeno que generó una amplia discusión en Reddit, Hacker News y comunidades de desarrolladores en Discord.
La situación se complicó aún más por un hilo de Hacker News de febrero de 2026 que reportaba casos donde los límites de velocidad parecían activarse sin un uso correspondiente. Aunque Anthropic declaró que no podía identificar un error de consumo de tokens, la comunidad documentó varios escenarios donde las operaciones en segundo plano de Claude Code — como la indexación automática de conversaciones, la gestión de la ventana de contexto y la sobrecarga de uso de herramientas — consumían tokens que los usuarios no autorizaron explícitamente. Esto resalta una característica importante de Claude Code: a diferencia de una simple llamada API donde controlas cada token, el comportamiento tipo agente de Claude Code significa que la herramienta misma genera una sobrecarga significativa de tokens a través de prompts del sistema, lecturas de archivos y pasos de razonamiento interno que contribuyen al consumo de tu cuota sin aparecer como "mensajes" visibles en tu terminal.
Comprender este consumo oculto de tokens es clave para gestionar los límites de suscripción de manera efectiva. Una sola interacción con Claude Code que aparece como un intercambio en tu terminal podría involucrar múltiples llamadas API internas — leer archivos, ejecutar comandos, buscar en la base de código — cada una de las cuales consume tokens contra tu cuota. Esta es la razón por la que la métrica de "aproximadamente 45 mensajes por 5 horas" para usuarios Pro puede sentirse tremendamente inexacta: una tarea de programación compleja podría consumir el equivalente a 15 "mensajes" en tokens en lo que parece una sola interacción desde la perspectiva del usuario.
Límites de velocidad de la API — RPM, ITPM y OTPM por nivel

Los límites de velocidad de la API gobiernan las llamadas directas a la API de mensajes de Anthropic y están organizados en cuatro niveles basados en compras acumuladas de créditos. A diferencia de las cuotas de suscripción, estos límites están definidos con precisión y devuelven respuestas de error estructuradas que tu código puede manejar programáticamente. Para un desglose más detallado, consulta la guía completa de niveles y límites de cuota de la API de Claude.
Aquí están los límites de velocidad actuales de la API por nivel para los modelos más utilizados (verificado desde platform.claude.com/docs/en/api/rate-limits, marzo de 2026):
| Modelo | Nivel 1 (RPM / ITPM / OTPM) | Nivel 2 | Nivel 3 | Nivel 4 |
|---|---|---|---|---|
| Sonnet 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Opus 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Haiku 4.5 | 50 / 50K / 10K | 1,000 / 450K / 90K | 2,000 / 1M / 200K | 4,000 / 4M / 800K |
Para avanzar entre niveles, necesitas compras acumuladas de créditos: $5 para el Nivel 1, $40 para el Nivel 2, $200 para el Nivel 3 y $400 para el Nivel 4. Cada nivel también tiene un techo de gasto mensual — $100, $500, $1,000 y $200,000 respectivamente — que actúa como una barrera de seguridad adicional.
Una de las características más poderosas pero menos comprendidas del sistema de límites de velocidad de Anthropic es el ITPM consciente de caché. Para la mayoría de los modelos actuales, los tokens de entrada en caché no cuentan para tu límite de ITPM. Esto significa que si logras una tasa de acierto de caché del 80% mediante el uso efectivo del caché de prompts, puedes procesar efectivamente cinco veces tu límite nominal de tokens por minuto. Con un límite de ITPM de Nivel 4 de 2,000,000, eso se traduce en un rendimiento efectivo de 10,000,000 de tokens de entrada totales por minuto cuando el caché está optimizado. Para una guía de implementación detallada, consulta nuestra guía de caché de prompts de la API de Claude.
El algoritmo de bucket de tokens merece atención especial porque afecta el comportamiento de ráfagas. A diferencia de un contador simple que se reinicia cada minuto, el bucket de tokens se rellena continuamente a una tasa constante hasta tu límite máximo. Esto significa que una tasa de 60 RPM puede aplicarse como aproximadamente 1 solicitud por segundo — ráfagas cortas que excedan esta tasa instantánea pueden desencadenar errores 429 incluso si tu uso promedio durante un minuto completo permanece bajo el límite. Los desarrolladores que disparan solicitudes en rápida sucesión en un bucle son particularmente propensos a encontrar este comportamiento.
Los límites de velocidad se aplican a nivel de organización, no por clave API. Si tu organización tiene múltiples proyectos o miembros del equipo compartiendo la misma cuenta API, todas sus solicitudes se extraen del mismo pool. Esta es la razón por la que los errores 429 a veces pueden aparecer incluso cuando tu aplicación individual parece estar haciendo solicitudes modestas — la carga de trabajo de otro miembro del equipo podría estar consumiendo la capacidad compartida. Para equipos, Anthropic ofrece configuración de límites a nivel de workspace: los administradores de la organización pueden asignar una porción de la capacidad total a cada workspace, evitando que un solo proyecto monopolice todo el presupuesto de límite de velocidad de la organización. Por ejemplo, si tu organización tiene un límite de Nivel 3 de 800,000 ITPM para Sonnet, podrías asignar 500,000 a tu workspace de producción y 300,000 al de desarrollo, asegurando que los experimentos de desarrollo nunca priven de recursos a tu sistema de producción.
El impacto práctico de estos límites de API en el uso de Claude Code depende en gran medida de cómo esté configurado Claude Code. Cuando Claude Code opera a través de tu suscripción (la configuración predeterminada para planes Pro y Max), utiliza la infraestructura interna de Anthropic y tu cuota de suscripción — no los límites de tu nivel API. Pero cuando configuras Claude Code para usar tu propia clave API (mediante variables de entorno o la bandera --api-key), cambia a usar los límites del nivel API en lugar de tu cuota de suscripción. Esta distinción es crucial para usuarios avanzados: si tienes una cuenta API de Nivel 4 con un límite de gasto mensual de $200,000, configurar Claude Code para usar tu clave API te da un rendimiento vastamente mayor que incluso el plan de suscripción Max 20x, a cambio de pagar por token en lugar de una tarifa mensual fija.
También vale la pena señalar que Anthropic introdujo recientemente el modo rápido para Opus 4.6, que tiene sus propios límites de velocidad dedicados separados de los límites estándar de Opus. Si estás usando la vista previa de investigación del modo rápido, podrías encontrar errores de límite de velocidad distintos de tu asignación estándar de Opus. Los encabezados de respuesta para el modo rápido usan encabezados con prefijo anthropic-fast-* en lugar de los encabezados estándar anthropic-ratelimit-*, así que tu código de monitoreo necesita verificar ambos conjuntos de encabezados si usas el modo rápido junto con la inferencia estándar.
Cómo identificar qué límite de velocidad has alcanzado
Diagnosticar correctamente qué sistema de límite de velocidad te ha restringido es el primer paso crítico para aplicar la solución correcta. Los síntomas son lo suficientemente diferentes como para que generalmente puedas identificar al culpable en segundos si sabes qué buscar.
Indicadores de límite de suscripción son relativamente informales. Claude Code mostrará un mensaje en la terminal que dice algo como "Límite de uso alcanzado" o "Te has quedado sin mensajes por ahora — por favor espera." No hay código de estado HTTP porque el límite se aplica en la capa de aplicación antes de que se realice cualquier llamada API. La interfaz web de Claude.ai también puede mostrar un temporizador de cuenta regresiva indicando cuándo se reinicia tu ventana de 5 horas, y este mismo temporizador se aplica a Claude Code ya que la cuota es compartida.
Indicadores de límite de velocidad de la API son precisos y legibles por máquinas. Recibirás una respuesta HTTP 429 con un cuerpo de error JSON que especifica qué límite se excedió (solicitudes, tokens de entrada o tokens de salida). La respuesta incluye un encabezado retry-after que te indica exactamente cuántos segundos esperar. Además, cada respuesta API exitosa incluye un conjunto de encabezados de límite de velocidad que te permiten monitorear tu capacidad restante en tiempo real:
pythonimport anthropic client = anthropic.Anthropic() try: response = client.messages.create( model="claude-sonnet-4-6-20250514", max_tokens=1024, messages=[{"role": "user", "content": "Hello"}] ) # Check remaining capacity from response headers print(f"Requests remaining: {response.headers.get('anthropic-ratelimit-requests-remaining')}") print(f"Input tokens remaining: {response.headers.get('anthropic-ratelimit-input-tokens-remaining')}") print(f"Output tokens remaining: {response.headers.get('anthropic-ratelimit-output-tokens-remaining')}") print(f"Reset time: {response.headers.get('anthropic-ratelimit-requests-reset')}") except anthropic.RateLimitError as e: print(f"Rate limited! Retry after: {e.response.headers.get('retry-after')} seconds") print(f"Error details: {e.message}")
Existe un tercer escenario menos común que vale la pena entender: los límites de aceleración. Incluso cuando estás dentro de tus topes nominales de RPM y TPM, la API de Anthropic aplica límites de aceleración que penalizan picos abruptos en el uso. Si el tráfico de tu organización salta significativamente en un período corto — por ejemplo, pasando de cero solicitudes a cientos en pocos minutos — puedes recibir errores 429 antes de alcanzar tus límites de velocidad publicados. La solución es aumentar el tráfico gradualmente en lugar de hacer una ráfaga de solicitudes. Este comportamiento es particularmente relevante para pipelines de CI/CD que inician múltiples instancias de Claude Code simultáneamente al comienzo de un proceso de compilación.
Si no estás seguro de si estás alcanzando límites de suscripción o de API, verifica estas tres señales en orden. Primero, observa el formato del error — si es un mensaje conversacional en tu terminal de Claude Code en lugar de un error HTTP estructurado, es un límite de suscripción. Segundo, verifica la interfaz web de Claude.ai — si también muestra un banner de límite de uso, tu cuota de suscripción está agotada. Tercero, examina los encabezados de respuesta de la API — si muestran cero tokens o solicitudes restantes, has alcanzado un límite de velocidad de la API. Para más patrones de solución de problemas con errores 429 específicamente, nuestra guía para solucionar errores 429 de límite de velocidad de la API de Claude cubre casos adicionales.
8 formas probadas de solucionar el error "Límite de velocidad alcanzado"
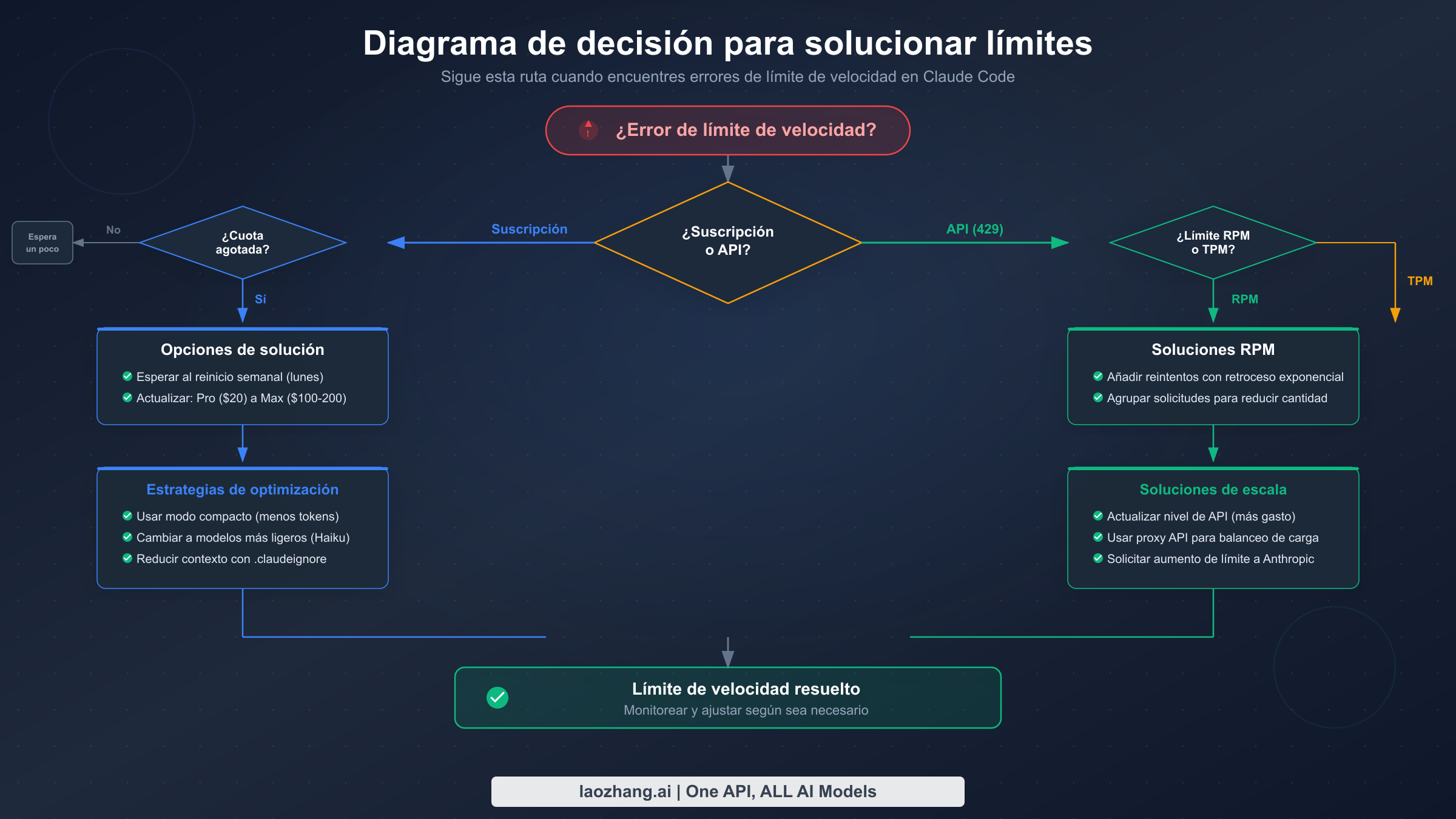
Cuando alcanzas un límite de velocidad, la solución correcta depende de qué sistema lo activó y cuán urgentemente necesitas reanudar el trabajo. Aquí hay ocho estrategias organizadas desde el alivio temporal más rápido hasta la solución más sostenible a largo plazo.
Solución 1: Esperar a que se reinicie la ventana rotativa. Para los límites de suscripción, la ventana rotativa de 5 horas significa que tu capacidad regresa gradualmente a medida que el uso anterior expira. No necesitas esperar las cinco horas completas — incluso 30 a 60 minutos de inactividad a menudo liberan suficiente cuota para unas pocas interacciones más. Para los límites de velocidad de la API, el bucket de tokens se rellena continuamente, así que esperar solo la cantidad de segundos especificada en el encabezado retry-after generalmente es suficiente.
Solución 2: Cambiar a un modelo más ligero. Si estás usando Opus 4.6 y alcanzas un límite de suscripción, cambiar a Sonnet 4.6 con el comando /model te da inmediatamente aproximadamente cinco veces más interacciones con la misma cuota restante. Sonnet maneja la gran mayoría de las tareas de programación de manera efectiva, y la diferencia de calidad es insignificante para operaciones rutinarias como edición de archivos, escritura de pruebas y navegación de código. Reserva Opus para tareas que genuinamente requieran un razonamiento más profundo, como decisiones arquitectónicas complejas o búsqueda de errores sutiles.
Solución 3: Reducir el tamaño del contexto de la conversación. Claude Code agrupa tu prompt del sistema, historial de conversación, contenido de archivos y tokens de uso de herramientas en cada solicitud. Iniciar una conversación nueva con /clear o cerrar y reabrir Claude Code elimina los tokens de historial acumulados que inflan la huella de cada solicitud. Sé estratégico sobre qué archivos incluyes en el contexto — evita cargar directorios completos cuando solo necesitas archivos específicos.
Solución 4: Implementar retroceso exponencial para límites de API. Para el acceso programático a la API, el retroceso exponencial con variación aleatoria (jitter) es el enfoque estándar de la industria. Aquí tienes una implementación lista para producción:
pythonimport time import random import anthropic def call_with_backoff(client, max_retries=5, **kwargs): """Call Anthropic API with exponential backoff on rate limit errors.""" for attempt in range(max_retries): try: return client.messages.create(**kwargs) except anthropic.RateLimitError as e: retry_after = int(e.response.headers.get("retry-after", 2 ** attempt)) wait_time = retry_after + random.uniform(0, 1) print(f"Rate limited. Waiting {wait_time:.1f}s (attempt {attempt + 1}/{max_retries})") time.sleep(wait_time) raise Exception(f"Failed after {max_retries} retries") client = anthropic.Anthropic() response = call_with_backoff( client, model="claude-sonnet-4-6-20250514", max_tokens=2048, messages=[{"role": "user", "content": "Analyze this code for bugs..."}] )
Solución 5: Habilitar y optimizar el caché de prompts. Dado que los tokens de entrada en caché no cuentan para los límites de ITPM en la mayoría de los modelos actuales de Claude, un caché efectivo puede multiplicar tu rendimiento efectivo por cinco veces o más. Coloca las instrucciones del sistema, documentos de contexto grandes y definiciones de herramientas al principio de tus mensajes con puntos de interrupción de caché. Monitorea tu tasa de acierto de caché en la página de uso de la consola de Claude y apunta a un 70% o más.
Solución 6: Distribuir solicitudes entre múltiples endpoints de modelo. Dado que los límites de velocidad de la API se aplican por separado a cada clase de modelo, puedes usar Sonnet y Haiku simultáneamente hasta sus respectivos límites. Enruta tareas más simples como formateo de código, generación de documentación y completaciones básicas a Haiku 4.5 mientras reservas Sonnet 4.6 para tareas de razonamiento más complejas. Esto efectivamente duplica o triplica tu rendimiento total sin actualizar niveles.
Solución 7: Actualizar tu plan o nivel de API. Si constantemente alcanzas los límites, actualizar puede ser la solución más rentable. Pasar de Pro ($20/mes) a Max 5x ($100/mes) te da cinco veces la cuota de suscripción más acceso a Opus. En el lado de la API, avanzar del Nivel 1 al Nivel 2 requiere solo $40 en compras acumuladas de créditos pero desbloquea un aumento de 20x en RPM (50 a 1,000) y un aumento de 15x en ITPM para Sonnet (30K a 450K).
Solución 8: Enrutar a través de un servicio de API de terceros. Para desarrolladores que frecuentemente alcanzan los límites de suscripción y quieren flexibilidad a nivel de API sin gestionar la progresión de niveles, los servicios de enrutamiento de API de terceros ofrecen una alternativa. Servicios como laozhang.ai proporcionan acceso a los modelos de Claude a través de un endpoint compatible con OpenAI donde pagas por token consumido sin límites de velocidad por minuto. Este enfoque evita las cuotas de suscripción por completo porque estás haciendo llamadas API directas en lugar de usar la suscripción de Claude Code, y el servicio de enrutamiento maneja el balanceo de carga entre múltiples claves API para evitar límites por organización.
Uso de enrutamiento de API de terceros para evitar límites de suscripción
Cuando las cuotas de suscripción se convierten en un cuello de botella persistente, configurar Claude Code para usar un endpoint de API de terceros puede cambiar fundamentalmente tu experiencia. En lugar de una cuota mensual fija que se agota durante sesiones de programación intensivas, pagas solo por los tokens que realmente consumes — lo que significa que tu límite efectivo es tu presupuesto en lugar de un tope de uso arbitrario.
La idea central es sencilla: Claude Code puede configurarse para enviar solicitudes API a cualquier endpoint que implemente el formato de la API de mensajes de Anthropic. Los servicios de enrutamiento de terceros como laozhang.ai aceptan estas solicitudes, las reenvían a la infraestructura de Anthropic (o proveedores de modelos equivalentes) y te cobran por token a tarifas competitivas con los precios directos de la API. Debido a que estos servicios normalmente mantienen pools de claves API entre múltiples organizaciones, los límites de velocidad por organización que restringen a los desarrolladores individuales se distribuyen entre un pool de capacidad mucho mayor.
Así es cómo configurar Claude Code para usar un endpoint de API alternativo con respaldo automático a la API oficial cuando el servicio de enrutamiento no está disponible:
pythonimport os import anthropic # Fallback: direct Anthropic API (subject to tier rate limits) ENDPOINTS = [ { "base_url": "https://api.laozhang.ai/v1", "api_key": os.environ.get("LAOZHANG_API_KEY"), "name": "laozhang.ai routing" }, { "base_url": "https://api.anthropic.com", "api_key": os.environ.get("ANTHROPIC_API_KEY"), "name": "Anthropic direct" } ] def create_message_with_fallback(messages, model="claude-sonnet-4-6-20250514", max_tokens=4096): """Try each endpoint in order, falling back on rate limit errors.""" for endpoint in ENDPOINTS: if not endpoint["api_key"]: continue try: client = anthropic.Anthropic( base_url=endpoint["base_url"], api_key=endpoint["api_key"] ) response = client.messages.create( model=model, max_tokens=max_tokens, messages=messages ) print(f"Success via {endpoint['name']}") return response except anthropic.RateLimitError: print(f"Rate limited on {endpoint['name']}, trying next...") continue except Exception as e: print(f"Error on {endpoint['name']}: {e}, trying next...") continue raise Exception("All endpoints exhausted")
Para la CLI de Claude Code específicamente, puedes establecer la variable de entorno ANTHROPIC_BASE_URL para apuntar a tu servicio de enrutamiento antes de iniciar una sesión. Esto redirige todas las llamadas API de Claude Code a través del endpoint alternativo sin modificar ningún archivo de configuración. La contrapartida es la transparencia de costos — necesitas monitorear tu gasto por token manualmente en lugar de depender del techo predecible de una suscripción mensual.
Este enfoque funciona mejor para desarrolladores que tienen patrones de uso impredecibles: algunos días apenas tocas Claude Code, otros días pasas ocho horas en sesiones intensivas de programación en pareja. Un modelo de pago por token alinea los costos con el consumo real en lugar de forzarte a un nivel que desperdicia dinero en días tranquilos o te deja limitado en días ocupados.
Hay consideraciones importantes a tener en cuenta al evaluar servicios de enrutamiento de terceros. Primero, verifica que el servicio soporte los modelos específicos de Claude que necesitas — algunos proveedores de enrutamiento solo ofrecen Sonnet mientras que otros proporcionan la línea completa de modelos incluyendo Opus y Haiku. Segundo, comprende las implicaciones de latencia — enrutar a través de un intermediario agrega una pequeña cantidad de sobrecarga de red, típicamente 50-200ms por solicitud, que es insignificante para el flujo de trabajo interactivo de Claude Code pero vale la pena conocer para procesamiento por lotes sensible a la latencia. Tercero, verifica si el servicio soporta respuestas en streaming, de las que Claude Code depende para la visualización de salida en tiempo real. Cuarto, evalúa los precios cuidadosamente — aunque los costos por token pueden ser comparables a los precios directos de la API, algunos servicios agregan un margen o cobran una tarifa mínima mensual. Los mejores servicios de enrutamiento ofrecen precios transparentes por token que reflejan de cerca las tarifas oficiales de Anthropic mientras proporcionan el beneficio adicional de límites de velocidad agrupados y conmutación automática por error entre múltiples organizaciones API.
Para equipos que consideran este enfoque a escala, vale la pena ejecutar una comparación de una semana: rastrea tu consumo real de tokens en tu plan actual, calcula cuánto costaría ese mismo uso a través de un servicio de enrutamiento, y compara tanto el costo monetario como el impacto en productividad de no alcanzar límites de velocidad. Muchos equipos descubren que el costo de tokens es comparable a su suscripción pero la eliminación de interrupciones por límites de velocidad produce una mejora medible en productividad que justifica el cambio.
Estrategias de prevención para usuarios intensivos de Claude Code
La forma más efectiva de manejar los límites de velocidad es nunca alcanzarlos en primer lugar. Estas estrategias se basan en patrones observados en miles de sesiones de Claude Code y las recomendaciones oficiales de la documentación de Claude Code.
Estrategia 1: Estructurar conversaciones para minimizar la inflación del contexto. Cada interacción de Claude Code arrastra el historial de conversación acumulado, lo que significa que el consumo de tokens crece con cada intercambio. Inicia conversaciones nuevas frecuentemente en lugar de ejecutar sesiones maratónicas. Usa el comando /compact para resumir y comprimir el historial de conversación cuando necesites mantener el contexto durante una tarea larga. Sé explícito sobre qué archivos debe leer Claude Code — evita comandos amplios como "mira todo el directorio src" cuando solo necesitas tres archivos específicos.
Estrategia 2: Usar el enrutamiento de modelos estratégicamente. No todas las tareas necesitan el modelo más potente. Crea un sistema de clasificación mental: usa Haiku para búsquedas rápidas de archivos, formateo y ediciones simples; Sonnet para tareas de programación estándar, depuración y generación de pruebas; y Opus solo para razonamiento arquitectónico complejo, errores sutiles o tareas donde Sonnet consistentemente falla. En los planes Max, vigila tu consumo de Opus y cambia a Sonnet proactivamente antes de que se active el umbral de degradación automática, ya que los cambios voluntarios te permiten controlar el momento mientras las degradaciones automáticas ocurren a mitad del flujo de trabajo.
Estrategia 3: Agrupar operaciones relacionadas. En lugar de enviar cinco solicitudes separadas para editar cinco archivos, describe las cinco ediciones en un solo prompt. Claude Code maneja operaciones multi-archivo de manera eficiente, y cada lote cuenta como una interacción contra tu cuota de suscripción en lugar de cinco. De manera similar, al revisar código, haz todas tus preguntas en un solo prompt en lugar de enviarlas una a la vez. Este enfoque también produce mejores resultados porque Claude puede considerar las relaciones entre tus preguntas en lugar de responder cada una de forma aislada.
Estrategia 4: Monitorear el uso proactivamente. Para el uso de la API, verifica los encabezados de límite de velocidad en cada respuesta para ver cuánta capacidad queda antes de alcanzar un muro. Para las cuotas de suscripción, la interfaz de Claude.ai muestra tu nivel de uso actual. Algunos desarrolladores construyen dashboards simples que rastrean sus patrones de consumo de API y envían alertas cuando el uso alcanza el 70% de los límites de su nivel, dándoles tiempo para ajustar su flujo de trabajo antes de que ocurra una interrupción. La página de uso de la consola de Claude proporciona gráficos que muestran tus tasas máximas de tokens por hora junto con tu techo de límite de velocidad, lo cual es invaluable para entender tus patrones de consumo.
Estrategia 5: Implementar el caché de prompts a nivel de infraestructura. Si estás construyendo aplicaciones sobre la API de Claude, haz del caché de prompts una preocupación arquitectónica de primera clase en lugar de un añadido posterior. Coloca el contenido estático (prompts del sistema, definiciones de herramientas, documentos de referencia grandes) al principio de cada solicitud con puntos de interrupción de caché apropiados. Con una tasa de acierto de caché del 80%, tu capacidad efectiva de ITPM aumenta cinco veces, lo cual es equivalente a actualizar dos niveles completos sin gastar un dólar adicional. La clave para lograr altas tasas de acierto de caché es la consistencia en cómo estructuras tus solicitudes — si el prompt del sistema y las definiciones de herramientas son idénticos entre solicitudes, se almacenarán en caché perfectamente. Incluso pequeñas variaciones en el contenido del prefijo pueden invalidar el caché, así que estandariza tus plantillas de prompts y usa puntos de interrupción de caché estratégicamente.
Estrategia 6: Programar cargas de trabajo pesadas durante horas fuera de pico. Aunque Anthropic no publica oficialmente datos de uso por hora del día, las observaciones de la comunidad reportan consistentemente que los límites de velocidad se sienten más generosos durante las horas fuera de pico de Norteamérica (aproximadamente de 2 AM a 8 AM hora del Pacífico). Esto probablemente se debe a que el bucket de tokens se rellena más rápido cuando la carga general de la plataforma es menor y menos solicitudes compiten por la misma capacidad de infraestructura. Si tienes trabajo de tipo lote que no requiere interacción en tiempo real — como generar documentación, ejecutar grandes suites de pruebas contra Claude o procesar revisiones de código — programar estas tareas para horas fuera de pico puede reducir la frecuencia de interrupciones por límites de velocidad.
Estrategia 7: Usar la API de lotes para cargas de trabajo no interactivas. Para tareas que no requieren respuestas inmediatas, la API de lotes de mensajes proporciona un camino dedicado con sus propios límites de velocidad separados de la API en tiempo real. Las solicitudes por lotes pueden encolar hasta 100,000 elementos en el Nivel 1 (500,000 en el Nivel 4), y el procesamiento por lotes cuesta un 50% menos que los precios estándar de la API. Esto lo hace ideal para operaciones masivas como generación de documentación de toda la base de código, revisión masiva de código o tareas de extracción de datos donde puedes enviar todas las solicitudes a la vez y recoger los resultados después. Los límites de cola de lotes son lo suficientemente generosos como para que la mayoría de los desarrolladores nunca los alcancen, dándote efectivamente un rendimiento ilimitado para trabajo asíncrono.
Preguntas frecuentes
¿Por qué alcanzo límites de velocidad en el plan Max con solo el 16% de uso mostrado?
El porcentaje de uso mostrado en la interfaz de Claude mide el consumo general de cuota, pero los límites de velocidad también pueden activarse por patrones de ráfaga dentro de ventanas de tiempo más cortas. Si envías un grupo de solicitudes complejas en rápida sucesión, puedes exceder el límite de rendimiento por minuto incluso si tu cuota total de 5 horas tiene bastante margen. Además, Opus 4.6 consume aproximadamente cinco veces más recursos que Sonnet 4.6 por interacción, así que el 16% de la cuota de Max 5x usado exclusivamente en Opus representa un número mucho mayor de intercambios de tokens de lo que el porcentaje sugiere. También hay un malentendido común sobre cómo el medidor de uso calcula su porcentaje — refleja un promedio ponderado que tiene en cuenta la complejidad del modelo, lo que significa que diez conversaciones con Opus podrían mostrar un 16% mientras consumen la misma computación bruta que ochenta conversaciones con Sonnet.
¿Cuál es la diferencia entre los límites de suscripción y los límites de API?
Los límites de suscripción son parte de tu plan Claude Pro o Max, se aplican durante una ventana rotativa de 5 horas, se comparten entre Claude.ai y Claude Code, y producen un mensaje conversacional de "límite de uso alcanzado". Los límites de velocidad de la API están vinculados al nivel de gasto de tu organización ($5 a $400+ en compras acumuladas), se miden en RPM/ITPM/OTPM por minuto, devuelven HTTP 429 con encabezados estructurados y solo se aplican a llamadas API directas. Los dos sistemas son completamente independientes — puedes agotar uno mientras tienes capacidad completa en el otro. Piensa en los límites de suscripción como una membresía mensual de gimnasio con un tope de visitantes, y los límites de API como una instalación de pago por uso con un límite de velocidad en la rapidez con que puedes entrar.
¿Borrar el historial de conversación ayuda con los límites de velocidad?
Para solicitudes futuras, sí — borrar el historial con /clear reduce la huella de tokens de las interacciones posteriores porque se agrupa menos contexto en cada llamada API. Sin embargo, no restaura retroactivamente la cuota que ya fue consumida. Los tokens usados en intercambios anteriores ya fueron contabilizados contra tus límites. Borrar el historial es una estrategia de prevención en lugar de una solución retroactiva. Dicho esto, el impacto puede ser sustancial: una conversación con 50 intercambios podría llevar más de 100,000 tokens de historial en cada solicitud posterior. Borrar ese historial y comenzar de nuevo puede reducir el consumo de tokens por solicitud en un 80% o más, lo que se traduce directamente en un agotamiento más lento de la cuota en adelante.
¿Puedo usar un endpoint de API diferente para evitar los límites?
Sí. Establecer ANTHROPIC_BASE_URL a un servicio de enrutamiento de terceros redirige las llamadas API de Claude Code a través de un endpoint alternativo con diferentes políticas de límite de velocidad. Servicios como laozhang.ai agrupan capacidad entre múltiples organizaciones API, lo que efectivamente proporciona un mayor rendimiento por minuto que una cuenta individual de Nivel 1 o Nivel 2. La contrapartida es que pagas por token consumido en lugar de tener una cuota mensual fija. Este enfoque es particularmente valioso para desarrolladores que experimentan una variación extrema de uso día a día — algunos días cero uso, otros días sesiones maratónicas de doce horas — porque un modelo de pago por token alinea los costos con el consumo real en lugar de requerir margen de suscripción para los días pico.
¿Cuánto tarda en reiniciarse un límite de velocidad?
Para las cuotas de suscripción, la ventana rotativa de 5 horas significa que tu capacidad regresa gradualmente a medida que las interacciones anteriores expiran — no necesitas esperar las cinco horas completas. En la práctica, la mayoría de los usuarios encuentran que 30 a 60 minutos de inactividad liberan suficiente cuota para varias interacciones más, y los modelos más ligeros recuperan cuota más rápido ya que consumieron menos en primer lugar. Para los límites de velocidad de la API, el bucket de tokens se rellena continuamente. El encabezado retry-after en las respuestas 429 te indica exactamente cuántos segundos esperar, típicamente entre 1 y 60 segundos dependiendo de cuánto excediste el límite. Los límites de aceleración (activados por picos repentinos de uso) pueden requerir períodos de enfriamiento más largos de varios minutos.
¿Hay alguna manera de verificar mi uso actual antes de alcanzar el límite?
Para el uso de la API, inspecciona los encabezados de respuesta en cada solicitud exitosa — anthropic-ratelimit-requests-remaining, anthropic-ratelimit-input-tokens-remaining y anthropic-ratelimit-output-tokens-remaining te indican exactamente cuánta capacidad queda. La página de uso de la consola de Claude proporciona gráficos históricos que muestran tus tasas de consumo pico junto con tu techo de límite de velocidad, lo cual ayuda a entender patrones y planificar necesidades de capacidad. Para las cuotas de suscripción, la interfaz web de Claude.ai muestra un indicador de uso, aunque se actualiza con menos frecuencia que los encabezados de la API. Algunos desarrolladores construyen scripts de monitoreo ligeros que registran estos valores de encabezado después de cada llamada API, creando un sistema de alerta temprana que les avisa cuando la capacidad restante cae por debajo del 20% del límite.