
Respuesta corta: empieza con Claude Sonnet 4.6 salvo que ya sepas que tu trabajo necesita de forma habitual razonamiento más profundo, ejecución autónoma más larga o salidas de una sola pasada más grandes. Esa es la lectura más sólida de la documentación actual de Anthropic a 19 de marzo de 2026.
El matiz que todavía se pierde en muchas comparativas es este: la decisión cambió el 13 de marzo de 2026. La documentación actual de Anthropic ya trata a Opus 4.6 y Sonnet 4.6 como modelos con 1M de contexto a precio estándar, por lo que Opus dejó de ser la única vía práctica para contexto largo dentro de Claude.
Eso no significa que ambos modelos sean intercambiables. En la tabla actual de modelos, Opus 4.6 sigue ocupando el techo de inteligencia, con 128k de salida máxima y latencia comparativa moderada, mientras que Sonnet 4.6 se mantiene como la mejor combinación entre velocidad e inteligencia, con 64k de salida máxima y latencia rápida. El precio también importa: Opus 4.6 figura en $5 input / $25 output por millón de tokens, y Sonnet 4.6 en $3 input / $15 output. Si pagas por API, no es una diferencia menor.
La decisión útil, por tanto, es directa: Sonnet 4.6 como modelo por defecto y Opus 4.6 como escalado intencional. Esta guía explica por qué con fuentes oficiales actuales y separa tres decisiones que muchas páginas mezclan: acceso por plan en la app, acceso en Claude Code y economía en API.
Resumen rápido
Si solo quieres una recomendación: usa Claude Sonnet 4.6 como modelo diario. Usa Claude Opus 4.6 cuando el coste de fallar sea alto, el problema requiera cadenas largas de razonamiento o te beneficies del mayor techo de salida de Opus.
| Categoría | Claude Opus 4.6 | Claude Sonnet 4.6 | Conclusión práctica |
|---|---|---|---|
| Fecha de lanzamiento | 5 de febrero de 2026 | 17 de febrero de 2026 | Ambos pertenecen a la generación Claude 4.6 |
| Rol oficial | Modelo más inteligente de Anthropic para agentes y coding | Mejor equilibrio entre velocidad e inteligencia | Opus es carril premium; Sonnet es carril por defecto |
| Precio base API | $5 input / $25 output por 1M | $3 input / $15 output por 1M | Sonnet es claramente más barato para uso continuo |
| Precio batch | $2.50 input / $12.50 output | $1.50 input / $7.50 output | La brecha de precio se mantiene en batch |
| Ventana de contexto | 1M tokens | 1M tokens | Desde el 13 de marzo de 2026 ambos 4.6 tienen 1M a precio estándar |
| Salida máxima | 128k | 64k | Opus da más margen para salidas largas de una sola pasada |
| Latencia comparativa | Moderada | Rápida | Sonnet encaja mejor como default interactivo |
| Rol en planes de consumo | Disponible en planes de pago por encima de Free | Default en Free y Pro | Sonnet es más fácil como punto de entrada |
| Acceso en Claude Code | Compatible, pero en Pro requiere comprar uso extra para Opus | Compatible por defecto | Esta fricción operativa aparece antes que muchas diferencias de calidad |
| Mejor encaje | Investigación profunda, code review complejo, agentes largos, pase final premium | Coding diario, redacción, análisis, pipelines de alto volumen, iteración rápida | Empieza con Sonnet y escala a Opus cuando la tarea lo justifique |
La forma más clara de decir el veredicto es: Sonnet 4.6 es el modelo con el que debes empezar; Opus 4.6 es el modelo que debes justificar.
Qué cambió después de la actualización documental del 13 de marzo de 2026
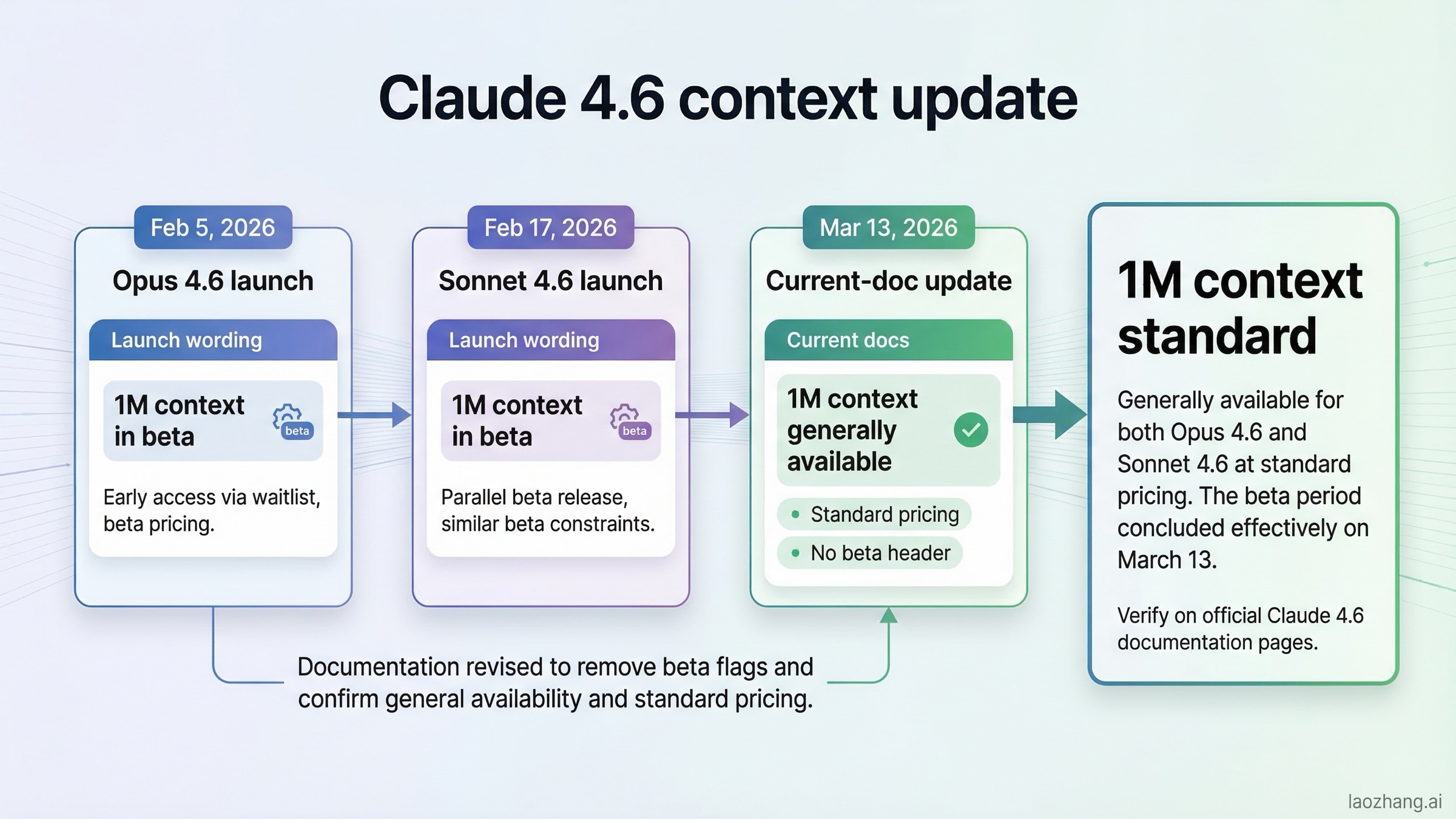
La parte más engañosa de la SERP actual no es un benchmark concreto; es un problema de cronología.
Las páginas de lanzamiento de Anthropic conservan el wording del rollout inicial. La página de lanzamiento de Claude Opus 4.6, del 5 de febrero de 2026, presentó Opus 4.6 con ventana de 1M en beta. La página de Claude Sonnet 4.6, del 17 de febrero de 2026, también describía la ventana de 1M como beta. Si te quedas ahí, parece que 1M sigue siendo una capacidad limitada o especial.
Pero la documentación viva actual cuenta otra historia. El models overview lista Opus 4.6 y Sonnet 4.6 con 1M de contexto. La guía de context windows dice de forma explícita que Claude Opus 4.6 y Sonnet 4.6 tienen una ventana de 1M tokens, y diferencia ese estado de Sonnet 4.5 y Sonnet 4, que todavía dependen del beta header más allá de 200k. Lo más relevante: las release notes registran que el 13 de marzo de 2026 la ventana de 1M pasó a disponibilidad general para Claude 4.6 con precio estándar y sin beta header.
Ese cambio altera la comparación. Antes del 13 de marzo, la disponibilidad de 1M era un gran divisor. Después del 13 de marzo, ya no. Hoy la comparación limpia es:
- ambos modelos tienen 1M de contexto
- ambos pertenecen a la misma generación Claude 4.6
- ambos comparten capacidades modernas de razonamiento
- las diferencias decisivas son precio, latencia, salida máxima y techo de razonamiento
Por eso tantas comparativas se sienten algo desactualizadas incluso cuando no inventan datos: se quedaron en el wording de lanzamiento y no integraron el estado documental actual.
Precio, margen de salida y latencia: lo que sí cambia la decisión
Cuando dejas de tratar 1M de contexto como diferencial principal, el tradeoff real se vuelve más claro.
Primero, precio. La página actual de pricing de Anthropic marca Opus 4.6 en $5 input / $25 output por millón de tokens y Sonnet 4.6 en $3 input / $15 output. En batch mantiene la misma forma: Opus pasa a $2.50 / $12.50 y Sonnet a $1.50 / $7.50. Es decir, Sonnet no es un poco más barato: es el modelo claramente más barato para tráfico sostenido.
Segundo, margen de salida. La tabla de modelos indica 128k de salida máxima para Opus 4.6 frente a 64k para Sonnet 4.6. Esa diferencia pesa menos en chats breves y mucho más cuando necesitas:
- refactors grandes con salida extensa
- informes largos estructurados
- reescrituras de código en bloque
- una única pasada grande en lugar de múltiples turnos
Tercero, postura de latencia. Anthropic clasifica Opus 4.6 como Moderate y Sonnet 4.6 como Fast. No significa que Sonnet gane siempre en cualquier benchmark; significa que la propia Anthropic mantiene a Sonnet como default interactivo y a Opus como carril pesado para tareas que merecen más coste y más tiempo de inferencia.
La tabla siguiente resume mejor los palancas reales que muchas páginas posicionadas:
| Palanca de decisión | Dónde gana Sonnet 4.6 | Dónde gana Opus 4.6 |
|---|---|---|
| Disciplina de coste | Menor precio base y batch para sostener default | Más difícil de justificar como default universal |
| Velocidad interactiva | Latencia rápida para iteración diaria | Latencia moderada aceptable cuando importa más la calidad final |
| Tamaño de salida | Suficiente para loops habituales de coding y análisis | Mejor para salidas finales grandes y reescrituras largas |
| Razonamiento difícil | A menudo suficiente para trabajo normal | Mejor para tareas ambiguas, largas o de alto riesgo |
| Pase final premium | Menor coste para despliegue amplio | Mejor cuando necesitas el techo más alto de Claude |
Si tu pregunta es "¿cuál debe ser el default?", precio y latencia inclinan a Sonnet 4.6. Si tu pregunta es "¿cuál tiene mejor techo?", salida máxima y razonamiento inclinan a Opus 4.6.
Si también quieres situar Opus frente a modelos frontier de otros proveedores, puedes usar como referencia adicional nuestra comparativa Claude Opus 4.6 vs GPT-5.3, que se mantiene como fallback en inglés.
Cuándo Sonnet 4.6 es suficiente y cuándo pagar Opus 4.6 sí compensa
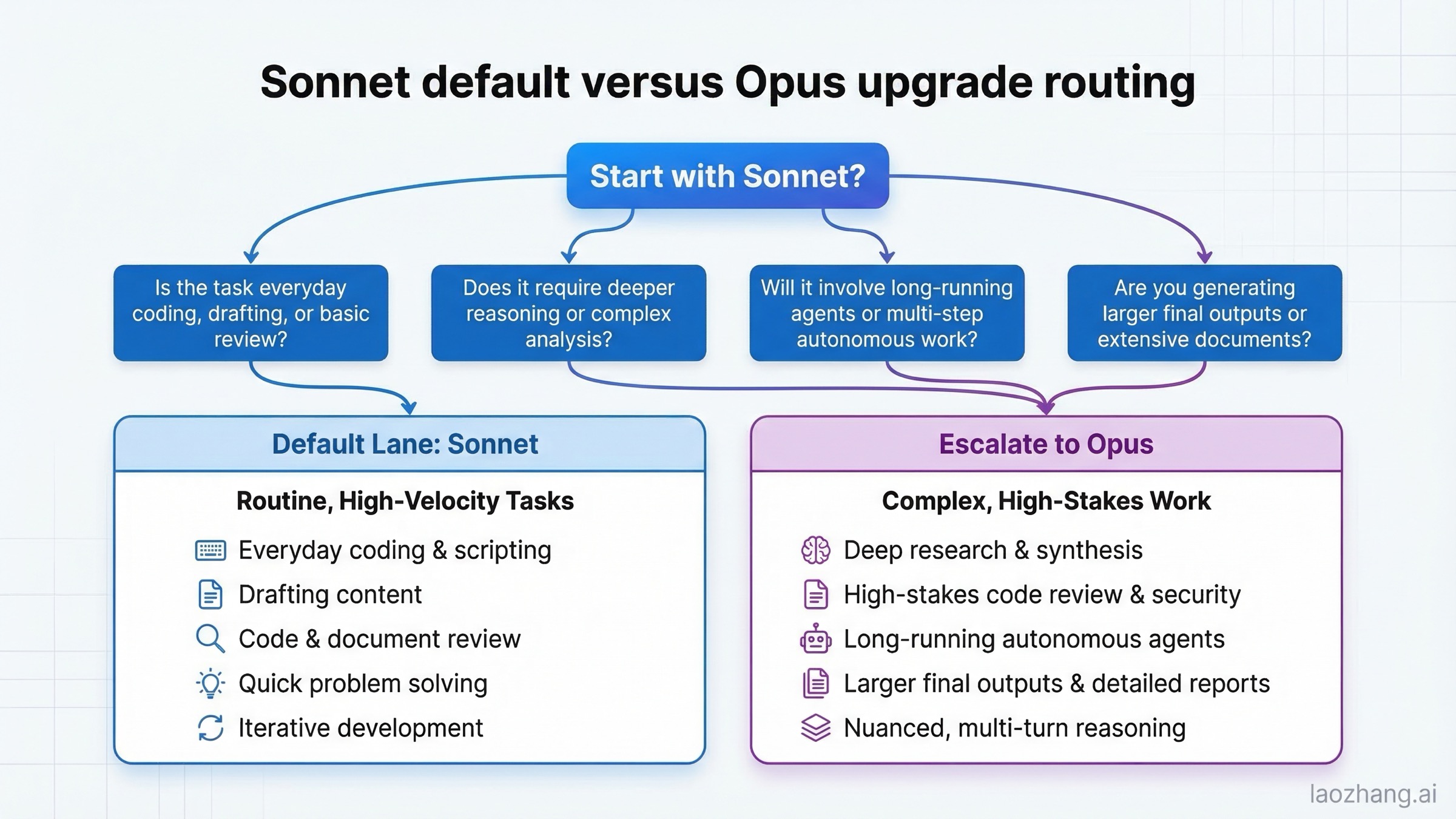
Anthropic da una heurística inicial clara en su guía para elegir modelo: Sonnet para el día a día y Opus para tareas que realmente exigen razonamiento sostenido. Esa regla mejora cuando la traduces a lenguaje operativo.
Sonnet 4.6 es suficiente para la mayor parte del coding diario, redacción, análisis y revisión rutinaria. Conviene cuando la tarea se repite mucho, cuando importa el throughput o cuando ejecutar el modelo premium en todo el tráfico encarece sin retorno claro.
Opus 4.6 sí compensa cuando fallar sale caro o recuperar el error consume mucho tiempo. Ahí entran investigación profunda, code review complejo, migraciones de codebase grandes, planificación multi-paso con ramas y trabajos donde el modelo debe mantener coherencia durante cadenas más largas.
Esto también explica parte de la fricción comunitaria: algunos usuarios están satisfechos con Sonnet porque es más rápido y más barato para su caso medio; otros pagan Opus porque priorizan tolerancia a fallo en casos difíciles. No son opiniones incompatibles: reflejan carriles de uso distintos.
Una regla práctica sólida:
- usa Sonnet 4.6 para borrador, implementación inicial y trabajo recurrente
- usa Opus 4.6 para pase difícil, revisión crítica y problema de horizonte largo
Es mejor que los dos extremos simplistas de la SERP ("usa Opus para todo" o "Sonnet hace innecesario Opus").
Si trabajas a diario en entorno Claude, también te conviene revisar Claude Code vs Codex, porque la elección de modelo y la elección de superficie de producto no son la misma decisión.
Claude app, Claude Code y API: por qué la respuesta cambia según la superficie
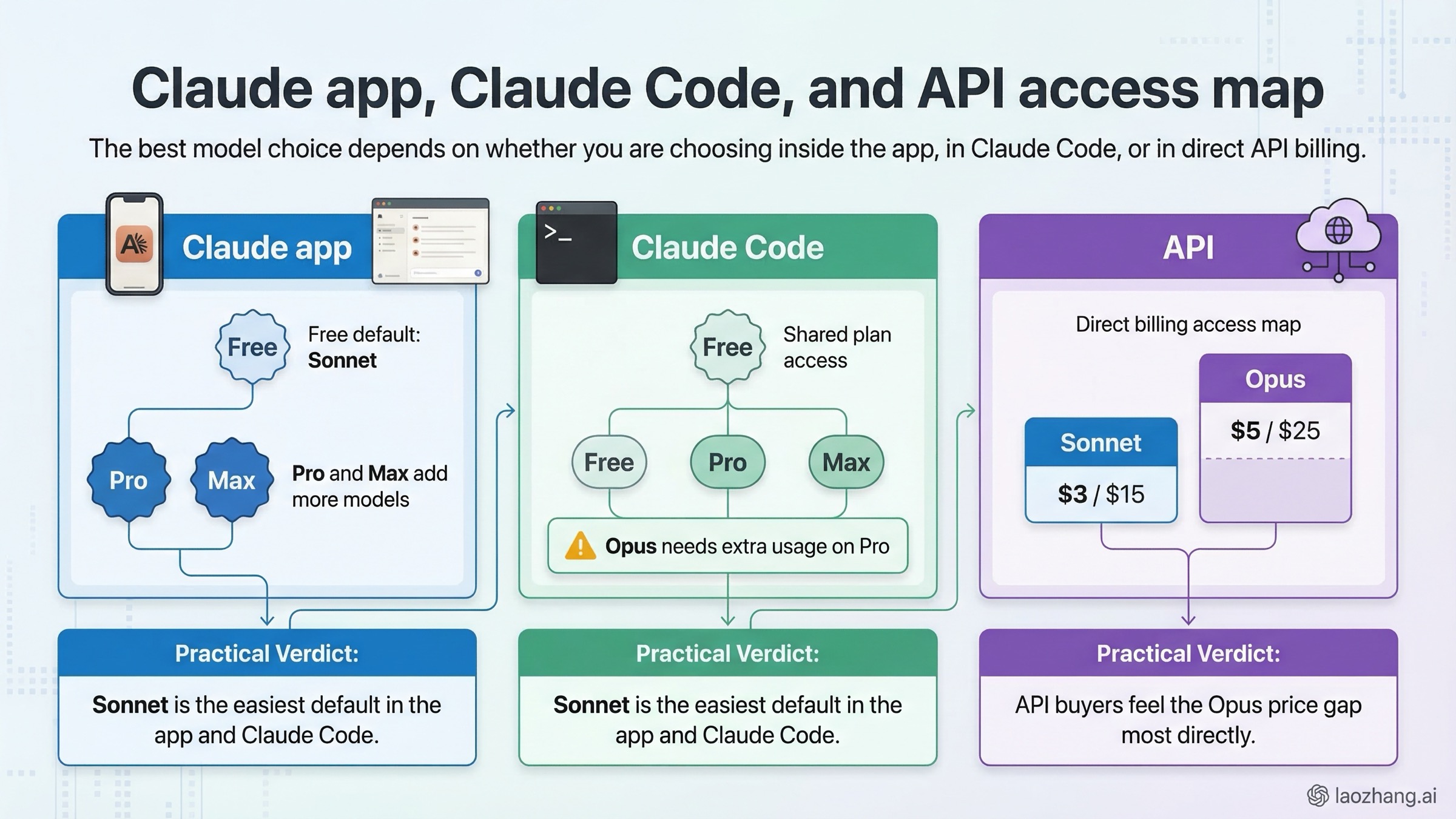
Muchas comparativas asumen que el lector decide solo en API. Es falso. Una gran parte de búsquedas de este tipo se resuelve dentro de claude.ai o Claude Code, y eso cambia la conclusión.
En la app de Claude, el esquema es claro. La página de pricing de Claude y la guía oficial de elección de modelo indican que Free incluye Sonnet, y que Pro y Max amplían acceso a más modelos, incluido Opus. Es decir, el default de entrada ya favorece a Sonnet.
En Claude Code, la diferencia operativa se vuelve más concreta. La página de ayuda de configuración de modelos en Claude Code enumera tanto claude-sonnet-4-6 como claude-opus-4-6, pero también aclara que en Pro el acceso a Opus requiere habilitar y comprar uso adicional. Este punto bloquea decisiones reales y casi nunca aparece en comparativas genéricas.
En API, la decisión se vuelve puramente económica. El salto entre $3 / $15 y $5 / $25 se nota desde el primer día si mueves volumen. En ese contexto, "usar Opus en todo" suele ser una mala política salvo que tu workload realmente lo necesite.
Por eso equipos igualmente sólidos pueden concluir cosas distintas:
- usuario de app Claude: "Opus merece la pena para trabajo difícil"
- equipo Claude Code: "Sonnet funciona mejor como default operativo"
- comprador API: "Sonnet para la mayoría, Opus para escalado selectivo"
Las tres respuestas pueden ser correctas porque optimizan superficies distintas.
Para equipos que operan sesiones largas o multiagente en Claude, también es útil Claude Code Agent Teams, ya que el coste y los límites se amplifican cuando pasas a trabajo concurrente.
Enrutado recomendado para equipos: carril default, premium e híbrido
La conclusión más útil no es "elige uno para siempre", sino diseñar un enrutado que ajuste coste y dificultad.
Para la mayoría de equipos, el patrón más robusto es:
- carril default: Sonnet 4.6 para coding diario, redacción, análisis documental e implementación inicial
- carril premium: Opus 4.6 para revisión compleja, planificación ambigua, salidas finales grandes y tareas con alto coste de error
- carril híbrido: Sonnet primero y Opus después cuando el primer pase se queda corto o necesitas una revisión final más fuerte
Ese enfoque híbrido encaja mejor con la escalera oficial de Anthropic que tratar Opus como default permanente. También escala mejor en coste, sobre todo en API o Claude Code, donde el uso intensivo hace que la diferencia de precio se note rápido.
Si además estás lidiando con presión de cuota, nuestro análisis de límites en Claude Code ayuda a entender por qué usar el modelo pesado como default adelanta esos cuellos de botella.
Recomendación final de esta guía:
Usa Sonnet 4.6 por defecto.
Escala a Opus 4.6 cuando se cumpla al menos una de estas condiciones:
- la tarea exige razonamiento profundo durante una cadena larga
- necesitas coherencia alta en trabajos multi-paso difíciles
- la salida final es lo bastante grande como para que 128k marque diferencia
- el coste de equivocarte justifica pagar por un pase final más fuerte
Es una respuesta mucho más útil que fingir que el modelo premium debe ser también el modelo estándar.
FAQ
¿Claude Opus 4.6 es mejor que Sonnet 4.6?
Sí en el techo, no como default universal. Opus 4.6 mantiene la posición superior de inteligencia y un límite de salida de 128k, pero Sonnet 4.6 es más barato, más rápido y comparte 1M de contexto a precio estándar. Por eso Opus es carril premium y Sonnet es carril base.
¿Empiezo con Sonnet 4.6 o con Opus 4.6?
Empieza con Sonnet 4.6, salvo que sepas de antemano que tu trabajo necesita razonamiento más profundo o salidas más grandes. La guía oficial de Anthropic también recomienda Sonnet como punto de partida por defecto.
¿Opus 4.6 sigue teniendo ventaja de contexto sobre Sonnet 4.6?
No en el sentido simple que repiten muchas páginas antiguas. Con documentación oficial revisada el 19 de marzo de 2026, ambos aparecen con 1M de contexto a precio estándar. Las diferencias reales son precio, latencia, salida máxima y techo de razonamiento.
¿Compensa pagar más por Opus 4.6 en API?
En algunos casos, sí: investigación de alto riesgo, code review difícil, agentes largos y salidas finales extensas. En tráfico diario, normalmente no compensa usar Opus para todo cuando Sonnet cubre la mayor parte con menor coste.
¿Puedo usar Opus 4.6 en Claude Code con plan Pro?
No de forma automática. La ayuda oficial de Claude Code indica que en Pro el acceso a modelos Opus requiere habilitar y comprar uso extra. Ese punto explica por qué muchos equipos se quedan en Sonnet como default práctico.