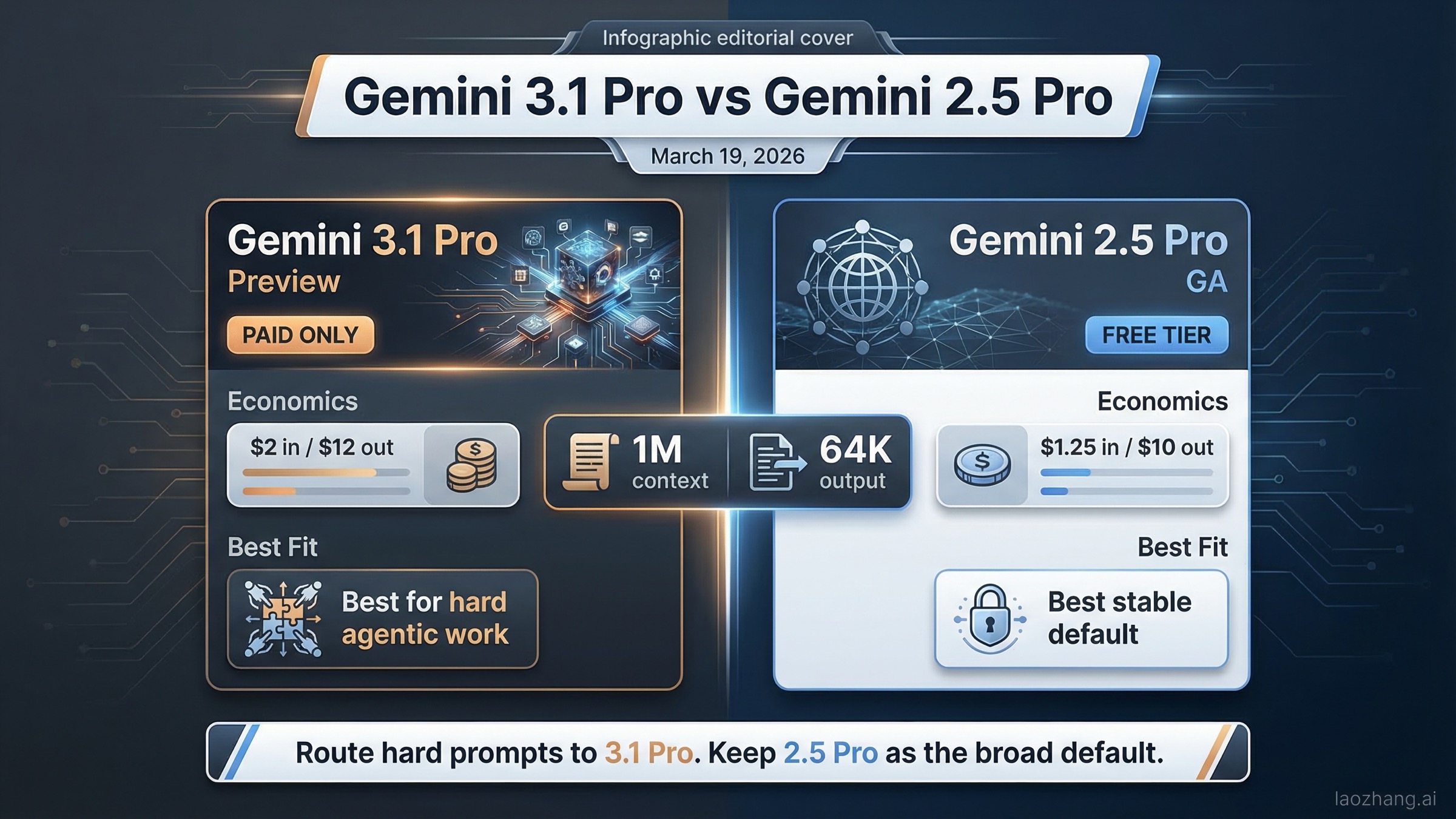
A 19 de marzo de 2026, Gemini 3.1 Pro es más potente en el extremo alto, pero Gemini 2.5 Pro sigue siendo la mejor opción base para más cargas de producción de las que parece. El matiz aparece cuando comparas lado a lado las páginas oficiales de Google, no solo los titulares de lanzamiento. Gemini 3.1 Pro es el modelo más nuevo, centrado en razonamiento y flujos agentic en estado preview; Gemini 2.5 Pro es GA, más barato, con nivel gratuito en Gemini Developer API y con menor incertidumbre operativa.
Por eso la pregunta correcta no es "¿qué modelo gana sobre el papel?", sino "¿sustituyo 2.5 Pro en todo o lo mantengo como vía estable y escalo a 3.1 Pro solo en tareas realmente difíciles?". Muchas páginas posicionadas no resuelven esa decisión: repiten benchmarks o fichas técnicas sin convertirlas en una política de enrutamiento. Esta guía hace justo lo contrario: arranca con la decisión y luego la respalda con datos oficiales verificables.
Resumen rápido
Si solo necesitas la respuesta práctica, aquí va: elige Gemini 3.1 Pro cuando tu cuello de botella sea razonamiento difícil, coding agentic o flujos con herramientas donde el rendimiento premium compense el riesgo de preview y la ausencia de free tier. Elige Gemini 2.5 Pro cuando priorices estabilidad GA, menor coste por token, vía gratuita para pruebas y menos sorpresas en producción.
La foto oficial al 19 de marzo de 2026 es esta:
| Área | Gemini 3.1 Pro | Gemini 2.5 Pro | Qué implica |
|---|---|---|---|
| Estado actual | Preview | Generally Available (GA) | 3.1 es más nuevo, pero no siempre el default más seguro |
| Model ID | gemini-3.1-pro-preview | gemini-2.5-pro | Migrar exige enrutamiento explícito, no reemplazo ciego |
| Nivel gratuito | No | Sí | 2.5 Pro facilita pruebas, staging y experimentación de bajo riesgo |
| Precio input estándar | $2.00 / 1M tokens hasta 200k | $1.25 / 1M tokens hasta 200k | 3.1 cuesta 60% más en input estándar |
| Precio output estándar | $12.00 / 1M tokens hasta 200k | $10.00 / 1M tokens hasta 200k | 3.1 cuesta 20% más en output estándar |
| Precio prompt largo | $4.00 in / $18.00 out por encima de 200k | $2.50 in / $15.00 out por encima de 200k | La brecha de precio también existe en prompts grandes |
| Ventana de contexto | 1M tokens | 1M tokens | 3.1 no gana por tamaño de contexto |
| Salida máxima | 64K tokens | 64K tokens | 3.1 tampoco gana por límite de salida |
| Mejor encaje | Razonamiento agentic más exigente, coding avanzado, tareas frontier | Default estable en producción, despliegues sensibles a coste, pruebas con free tier | Úsalo como carril premium, no como único carril por defecto |
Estas filas salen directamente de Gemini Developer API pricing, Gemini API models, catálogo de modelos de Vertex AI, model card de Gemini 3.1 Pro y el PDF oficial del model card de Gemini 2.5 Pro. La clave es esta: Google no está pidiendo cambiar 2.5 por 3.1 por límites brutos. Ambos modelos ya están en 1M de contexto y 64K de salida. La decisión real es calidad, coste y madurez de producto.
Por eso la recomendación práctica es simple:
- Usa Gemini 3.1 Pro cuando la tarea sea lo bastante difícil como para que un mejor razonamiento te ahorre revisión humana.
- Mantén Gemini 2.5 Pro como default para coding cotidiano, tráfico amplio y escenarios donde GA + free tier importan.
- Si puedes enrutar por tipo de tarea, no elijas solo uno: deja 2.5 como base y escala a 3.1 en prompts duros.
Ese también es el motivo de la confusión habitual: "modelo nuevo" suena a mejora universal, pero los precios y estados oficiales dicen otra cosa. En la práctica, Gemini 3.1 Pro es mejor entendido como carril premium que como sustituto universal.
Qué cambió realmente de 2.5 Pro a 3.1 Pro
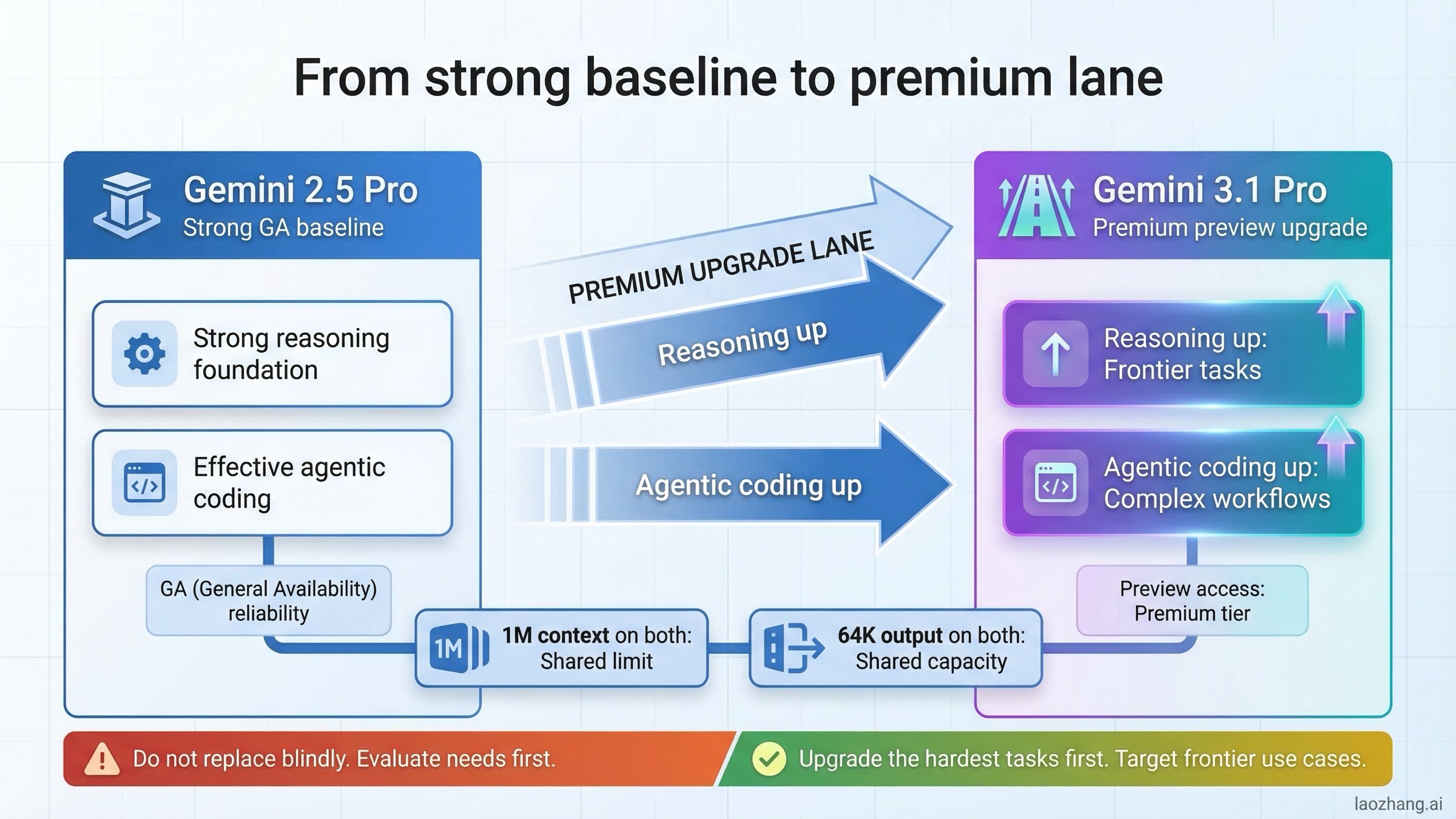
El error más común en esta comparación es asumir que el salto de 2.5 Pro a 3.1 Pro va sobre todo de "más contexto", "más output" o "más velocidad". No es así. El cambio importante está en cómo Google posiciona la familia.
En la página actual de modelos de Vertex AI, Gemini 3.1 Pro aparece en la sección preview, descrito como el modelo más reciente orientado a razonamiento para flujos agentic complejos y coding. En esa misma página, Gemini 2.5 Pro aparece en la sección GA como modelo de alta capacidad para razonamiento y coding complejos. Ese lenguaje importa: Google está marcando 3.1 como paso frontier y 2.5 como estándar estable actual.
El model card de Gemini 3.1 Pro refuerza ese mensaje. Publicado el 19 de febrero de 2026, define 3.1 Pro como el modelo más avanzado de Google para tareas complejas en la fecha de publicación. También confirma 1M de contexto, 64K de salida y despliegue amplio en Gemini app, Vertex AI, AI Studio, Gemini API, Google Antigravity y NotebookLM.
Pero el model card de Gemini 2.5 Pro, actualizado el 27 de junio de 2025, explica por qué 2.5 sigue siendo difícil de retirar: declara estado GA y confirma el mismo formato de 1M/64K. Es decir, cambiar a 3.1 no te da "más espacio"; pagas por un modelo potencialmente más capaz, no por límites más amplios.
Se ve aún más claro si miras el último encuadre público de 2.5 antes del lanzamiento de 3.1. En el post de Google del 6 de mayo de 2025, "Build rich, interactive web apps with an updated Gemini 2.5 Pro", se destacaron mejoras en coding y generación web, con liderazgo en WebDev Arena. Eso consolidó 2.5 Pro como baseline práctico para muchos equipos.
Ese es el modelo mental correcto para todo lo que sigue:
- Gemini 2.5 Pro no es "el viejo flojo".
- Gemini 3.1 Pro no es "lo mismo, pero gratis y más rápido".
- La comparación real es preview premium vs GA estable.
Con ese marco, los datos de precio, calidad y operación empiezan a encajar.
Precio, nivel gratuito y estado del modelo a 19 de marzo de 2026

El precio es donde la decisión deja de ser teórica. Muchas comparativas esconden esta parte detrás de lenguaje de benchmark, pero la página oficial de precios de Gemini Developer API lo deja claro.
Para Gemini 3.1 Pro Preview, Google lista:
- Sin free tier
\$2.00input por 1M tokens hasta 200k tokens de prompt\$12.00output por 1M tokens hasta 200k tokens de prompt\$4.00input y\$18.00output por encima de 200k tokens de prompt- Precio batch al 50% del precio estándar
Para Gemini 2.5 Pro, Google lista:
- Free tier disponible
\$1.25input por 1M tokens hasta 200k tokens de prompt\$10.00output por 1M tokens hasta 200k tokens de prompt\$2.50input y\$15.00output por encima de 200k tokens de prompt- Precio batch al 50% del precio estándar
La diferencia de pago estándar no es menor:
- Coste de input: 3.1 Pro es 60% más caro.
- Coste de output: 3.1 Pro es 20% más caro.
- Acceso gratuito: 3.1 Pro lo elimina.
En una app de producción, ese sobrecoste puede tener sentido si reduce reintentos, borradores malos o revisión humana. Pero en coding rutinario, tráfico amplio o staging, la diferencia sí pesa; y la pérdida de free tier pesa todavía más.
Ejemplo simple: pipeline mensual con 50 millones de tokens de input y 10 millones de output, mayormente por debajo de 200k tokens por prompt.
Con Gemini 2.5 Pro:
- Input: 50 x $1.25 =
\$62.50 - Output: 10 x $10 =
\$100 - Total:
\$162.50
Con Gemini 3.1 Pro:
- Input: 50 x $2.00 =
\$100 - Output: 10 x $12 =
\$120 - Total:
\$220
No es un salto catastrófico, pero tampoco marginal: el incremento ronda 35% en este escenario, antes de considerar que 2.5 conserva la vía gratuita y 3.1 no.
El estado del producto importa tanto como el precio. Tanto Gemini API models como Vertex AI models sostienen el mismo reparto: 3.1 sigue en preview y 2.5 ya es GA. "Preview" no significa "inutilizable", pero sí implica mayor riesgo de cambios.
Por eso la pregunta correcta no es "¿puedo pagar 3.1?", sino "¿necesito 3.1 lo suficiente como para pagar más por un modelo preview cuando 2.5 cubre bien el uso mainstream?" Para mucho tráfico, la respuesta sigue siendo no; para los casos más difíciles, puede ser sí.
Por qué los equipos de API y los usuarios de Gemini App no toman la misma decisión
Esta keyword mezcla dos compradores diferentes. Una parte está decidiendo qué modelo API usar en producción; otra parte quiere saber qué expone la Gemini app en planes de usuario. Son preguntas relacionadas, pero no iguales.
El propio SERP de Google refleja esa división. Para API, pesan más precios de Gemini Developer API, catálogo de modelos de Gemini API, catálogo de Vertex AI y model cards. Para app, Google también posiciona soporte como Gemini Apps limits and upgrades, porque la duda real suele ser de plan y disponibilidad.
Si eres un equipo API, la decisión 3.1 vs 2.5 depende de:
- calidad real en tareas difíciles
- coste por token
- acceso a free tier
- madurez operativa
- economía de herramientas (caching, batch, grounding)
Si eres usuario de Gemini app, suele importar más:
- qué modelo aparece en el selector
- qué plan lo desbloquea
- qué límites de uso aplica
- cómo se siente en tu flujo real
Y justo ahí aparece el matiz económico que se suele omitir.
En la página de precios, Gemini 3.1 Pro Preview no solo es de pago: también encarece funciones adyacentes críticas para equipos API. Hasta 200k tokens de prompt:
- Context caching 3.1 Pro Preview:
\$0.20por 1M tokens - Context caching 2.5 Pro:
\$0.125por 1M tokens - Mismo coste de almacenamiento en ambos:
\$4.50 / 1,000,000 tokens por hora
Por encima de 200k tokens:
- Context caching 3.1 Pro Preview sube a
\$0.40 - Context caching 2.5 Pro sube a
\$0.25
Si solo comparas input/output estándar, este coste se te escapa. En sistemas reales, la prima de 3.1 también aparece en el "alrededor" del modelo.
Batch es otro ejemplo. La parte superior de la página indica Batch API con reducción del 50%. En tablas por modelo, ambos siguen esa lógica. Para prompts hasta 200k:
- Batch en 3.1 Pro Preview:
\$1.00input y\$6.00output - Batch en 2.5 Pro:
\$0.625input y\$5.00output
Conclusión: incluso con batch, 3.1 sigue siendo el carril más caro.
Grounding también cambia la economía si dependes de Search o Maps. Aquí hay que leer con cuidado porque las unidades no son idénticas. En 3.1 Pro Preview se muestran 5,000 prompts/mes gratis para grounding con Search/Maps y luego \$14 / 1,000 search queries. En 2.5 Pro aparecen 1,500 RPD gratis para prompts con grounding y luego \$35 / 1,000 grounded prompts (Search) y \$25 / 1,000 grounded prompts (Maps). No conviene forzar una equivalencia exacta cuando la unidad difiere, pero sí entender la consecuencia: elegir modelo también es elegir estructura de facturación de herramientas.
Por eso el free tier importa más de lo que parece. Para muchos equipos no es "ahorro hobby", sino carril barato para:
- pruebas de staging
- experimentos de prompt templates
- checks de regresión de bajo riesgo
- smoke tests del enrutador
Gemini 2.5 Pro mantiene ese carril. Gemini 3.1 Pro Preview no.
Y eso cambia la adopción sensata del modelo nuevo. Los equipos maduros no arrancan con "3.1 es mejor, migramos todo". Arrancan con "2.5 se queda como carril base de validación y 3.1 se justifica donde su ventaja paga el coste extra".
La parte de soporte del SERP lo confirma desde otro ángulo. Cuando Google posiciona páginas de límites de Gemini app, está admitiendo que gran parte del mercado no busca solo benchmarks: busca claridad sobre superficies de acceso. En app, la pregunta dominante es plan + disponibilidad; en API, es flujo + economía.
En resumen:
- Lectura app-first: si aparece el modelo nuevo, pruébalo y decide por calidad percibida.
- Lectura API-first: decide carril base vs carril premium con coste, caching, grounding y batch sobre la mesa.
En este artículo priorizamos la lectura API porque es la más exigente y la más útil para decisiones de producción.
Benchmarks: dónde 3.1 realmente saca ventaja y dónde la comparación es más ambigua
En IA es fácil sobrerrepresentar certeza con benchmarks. Aquí hay un riesgo claro: el model card oficial de Gemini 3.1 Pro y el de Gemini 2.5 Pro no vienen en una sola tabla unificada de mismo día y mismo protocolo. Los números son útiles, pero deben leerse con contexto.
Foto direccional según ambos model cards oficiales:
| Benchmark | Cifra oficial Gemini 3.1 Pro | Cifra oficial Gemini 2.5 Pro | Lectura segura |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | Señal fuerte de mejora en razonamiento frontier |
| GPQA Diamond | 94.3% | 86.4% | 3.1 parece claramente superior en razonamiento científico |
| SWE-Bench Verified | 80.6% | 59.6% | Ventaja direccional para 3.1, con caveat metodológico |
| Terminal-Bench 2.0 | 68.5% | No reportado en card GA de 2.5 | 3.1 se posiciona explícitamente para coding agentic más fuerte |
| APEX-Agents | 33.5% | No reportado en card GA de 2.5 | Refuerza mejor rendimiento en tareas agentic de largo horizonte |
| Contexto / salida | 1M / 64K | 1M / 64K | Sin victoria de límites para 3.1 |
La interpretación prudente es: Gemini 3.1 Pro mejora la narrativa frontier y agentic de Google, pero no conviene vender cada línea como comparación de laboratorio perfecta contra 2.5.
Aun con ese caveat, el patrón es claro. 3.1 Pro tiende a encajar mejor cuando la tarea es:
- multi-step y tool-heavy
- lo bastante compleja como para que mejor razonamiento cambie el resultado
- más cercana a coding agentic que a autocompletado rutinario
- cara en revisión humana si la primera respuesta falla
2.5 Pro sigue siendo fuerte cuando la tarea es:
- de alta calidad pero no frontier extrema
- repetitiva a escala
- sensible al coste
- amplia en operación, no solo elite
Por eso los benchmarks deben ayudarte a enrutar, no a reemplazar todo por impulso. Si el 5% de tareas más duras tiene alto impacto, 3.1 puede pagarse solo. Si el 95% es trabajo estable de coding, resumen con recuperación o prompts de negocio estructurados, 2.5 Pro conserva ventaja económica y operativa.
Además, como ambos modelos ya comparten 1M/64K, la diferencia de benchmark pesa más: no estás comprando más límite, estás comprando mejor "cerebro" en ciertas clases de tarea.
Latencia, contexto largo y fiabilidad en producción
Las páginas oficiales aclaran capacidades, pero no cierran la pregunta operativa: ¿qué tan predecible es el modelo nuevo bajo carga real?
Aquí el SERP añade una señal útil: hilos de fricción como "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame". Un hilo de foro no es especificación oficial, pero sí evidencia de ansiedad real del mercado: mucha gente no evalúa por diapositiva de lanzamiento, sino por comportamiento en prompts largos y difíciles.
Esto importa porque en papel ambos muestran 1M de contexto y 64K de salida. Igual límite no significa igual experiencia. Las preguntas correctas son:
- ¿qué modelo es más predecible en tu mezcla de prompts?
- ¿cuál produce menos falsos arranques caros?
- ¿cuál exige menos lógica de fallback?
- ¿cuál justifica su prima con menos reintentos y menos corrección humana?
Para muchos equipos, 2.5 Pro sigue siendo más "tranquilo" porque es GA y más barato. Preview no equivale automáticamente a inestable, pero sí es razón suficiente para no convertir 3.1 en default universal sin medir.
También conviene separar riesgo de capacidad y riesgo de producto. 3.1 probablemente gana en capacidad para carriles difíciles; 2.5 suele ganar en riesgo de producto para despliegue amplio porque:
- es GA, no preview
- conserva free tier
- cuesta menos
- su comportamiento ya está más conocido por muchos equipos
De ahí que el patrón más seguro sea enrutamiento progresivo, no reemplazo masivo: 2.5 en el carril ancho, 3.1 en solicitudes que realmente lo necesitan. Si 3.1 reduce fallos o revisión de forma consistente, amplías su cuota. Si no, no has comprometido todo el sistema por seguir una etiqueta más nueva.
Si ya operas fuerte en ecosistema Google, también te sirve revisar guías relacionadas como la guía en inglés sobre el límite de salida de Gemini 3.1 Pro, la guía en inglés sobre timeouts de Gemini 3.1 Pro y, en español, la resolución de errores de Gemini API. Esos puntos adyacentes suelen decidir la verdadera "preparación para producción".
Qué modelo elegir para código, agentes, investigación y control de costes
La forma más útil de decidir es dejar de buscar "ganador absoluto" y mapear modelo por carga de trabajo.
| Carga de trabajo | Mejor default | Por qué |
|---|---|---|
| Asistencia diaria de coding | Gemini 2.5 Pro | Más barato, GA y suficientemente sólido para tareas comunes |
| Coding agentic complejo | Gemini 3.1 Pro | Posicionamiento oficial y señales de benchmark favorecen su carril agentic |
| Análisis de investigación exigente | Gemini 3.1 Pro | Mejores señales oficiales de razonamiento frontier |
| Trabajo de contexto largo a escala | Gemini 2.5 Pro primero, 3.1 de forma selectiva | Mismo 1M de contexto, pero 2.5 es más barato y estable como base |
| Experimentación con free tier | Gemini 2.5 Pro | 3.1 no tiene nivel gratuito |
| Tráfico amplio de producción | Gemini 2.5 Pro | GA + coste menor reducen fricción operativa |
| Carril premium de fallback | Gemini 3.1 Pro | Mejor uso del modelo nuevo cuando no todo prompt necesita inteligencia máxima |
Para equipos pequeños y perfiles solistas, la respuesta simple suele ser: empieza con 2.5, añade ruta 3.1 para los casos más difíciles y no complejices hasta que el carril premium demuestre retorno.
Para equipos de ingeniería más grandes, la respuesta es arquitectónica. Si ya tienes enrutador, 3.1 encaja como carril de alta inteligencia y 2.5 como carril de volumen. Lo peor no suele ser "seguir con el modelo viejo", sino "enviar todo al preview caro aunque no haga falta".
Para equipos de research/evaluación, 3.1 merece mayor cuota: su model card trae narrativa frontier más fuerte. Aun así, sin perder de vista economía.
Para producción sensible a coste, 2.5 es muy difícil de superar por combinación de GA + free tier + tarifa menor.
Aquí también tiene sentido un gateway multi-modelo. Si tu problema real es enrutar entre generaciones en una sola base de código, una capa como laozhang.ai puede ser útil por gestión de tráfico, coste y fallback. Se menciona porque esta comparación es operacional, no de marketing.
Qué debes medir antes de promocionar 3.1 Pro
El error típico tras leer una comparativa así es probar dos o tres prompts llamativos con 3.1, concluir "se nota mejor" y cambiar el default global. Ese proceso no es serio para producción.
Empieza separando tu carga en buckets que reflejen valor de negocio real:
| Bucket de evaluación | Ejemplos típicos | Pregunta de modelo que realmente estás respondiendo |
|---|---|---|
| Edición y coding rutinario | refactors, tests pequeños, fixes directos | ¿3.1 mejora lo suficiente como para pagar más en trabajo común? |
| Coding agentic complejo | cambios multi-repo, bucles de herramientas, cadenas largas | ¿3.1 reduce fallos de primera pasada de forma material? |
| Análisis de contexto largo | documentos grandes, transcripciones, razonamiento multiarchivo | ¿3.1 mantiene ventaja cuando el prompt se vuelve pesado? |
| Investigación con grounding / tools | respuestas con Search, orquestación externa | ¿la mejora compensa prima y coste de grounding? |
| Tráfico masivo sensible a coste | solicitudes de alto volumen | ¿hay razón real para no dejar 2.5 como carril por defecto? |
Si pruebas un solo bucket, casi seguro leerás mal la migración. 3.1 puede merecerse en "hard agentic" y ser mala idea como default para "bulk traffic".
La segunda regla: mide trabajo aceptado, no solo calidad percibida. La métrica útil no es "qué respuesta sonó mejor", sino "qué modelo entrega resultado aceptable más barato tras reintentos y correcciones".
Como mínimo, mide:
- tasa de aceptación en primera respuesta
- minutos de corrección humana
- tasa de reintento
- p95 de latencia
- coste de tokens
- coste de caching (si aplica)
- coste de grounding (si aplica)
- tasa de fallback a otro modelo o flujo
Sin eso, no sabes si 3.1 te sale más caro o más barato en términos de negocio.
Para comparar bien, mantén condiciones estables:
- Congela plantillas de prompt durante la prueba.
- Usa el mismo set de herramientas en ambos modelos.
- Mantén configuración de temperatura/razonamiento comparable donde la API lo permita.
- Evalúa con prompts reales de producción, no tareas públicas de juguete.
- Separa tareas fáciles de difíciles antes de promediar.
Este último punto es crítico: si mezclas todo, la ganancia en tareas duras se diluye; si sobremuestras "hero tasks", sobreestimas la ventaja premium.
Tercera regla: prueba comportamiento operativo, no solo corrección. Con 1M/64K en ambos, la diferencia real suele salir en:
- cuántas veces hace falta "un reintento más"
- estabilidad en cadenas largas de herramientas
- coherencia en contexto largo
- facilidad de postprocesado
- predictibilidad semana a semana
Aquí pesa el estado preview: puede ser suficientemente bueno para producción, sí, pero moverlo al carril masivo exige un listón mayor.
Una prueba de promoción razonable para Gemini 3.1 Pro:
- Recolecta prompts representativos de las últimas 2-4 semanas.
- Etiqueta cada prompt por tipo de tarea e impacto.
- Ejecuta el mismo set en Gemini 2.5 Pro y Gemini 3.1 Pro.
- Evalúa salidas con revisión ciega cuando sea viable.
- Registra latencia y reintentos junto a calidad.
- Compara coste por respuesta aceptada, no solo coste por token.
- Mantén la prueba el tiempo suficiente para detectar variación operativa.
Si tienes volumen, no te quedes en benchmark offline: haz experimento controlado en vivo.
- Mantén Gemini 2.5 Pro como default.
- Envía una fracción de tareas duras a Gemini 3.1 Pro.
- Mide impacto de negocio en ese slice.
- Escala solo si la mejora se sostiene.
Cuarta regla: mide economía tool-side, no solo respuesta del modelo. Si dependes de prompts largos, caching, batch o grounding, la decisión también es de infraestructura:
- ¿3.1 sigue cuadrando con caching más caro?
- ¿batch preserva margen en trabajos asíncronos?
- ¿el coste por unidad de grounding aguanta tu volumen?
- ¿la ausencia de free tier frena experimentación?
Quinta regla: define la puerta de promoción antes de ver resultados.
- 3.1 debe superar 2.5 con margen significativo en bucket duro.
- El aumento de latencia debe caber en tu SLO.
- El coste por respuesta aceptada debe quedar dentro de la banda premium acordada.
- El comportamiento preview debe ser estable en ventana multi-día o multi-semana.
- El bucket masivo debe mantenerse en 2.5, salvo evidencia clara de negocio.
Si 3.1 supera esa puerta, promuévelo donde ganó. Si no, se queda como carril especializado. Eso no es fracaso: es una decisión de routing mejor.
Patrón operativo que suele funcionar:
- clasificar solicitudes en dificultad baja, media, alta
- mantener
gemini-2.5-proen baja y gran parte de media - enrutar alta dificultad o alto coste de revisión a
gemini-3.1-pro-preview - monitorizar bucket duro semanalmente y recalibrar reglas de promoción cada mes
Te llevas buena parte de la mejora sin forzar todo el negocio al preview caro.
Si necesitas una frase para recordar esta sección: evalúa el carril premium contra tu presupuesto de corrección, no contra tu curiosidad.
Estrategia de migración: reemplazar, enrutar en paralelo o quedarse en 2.5 Pro
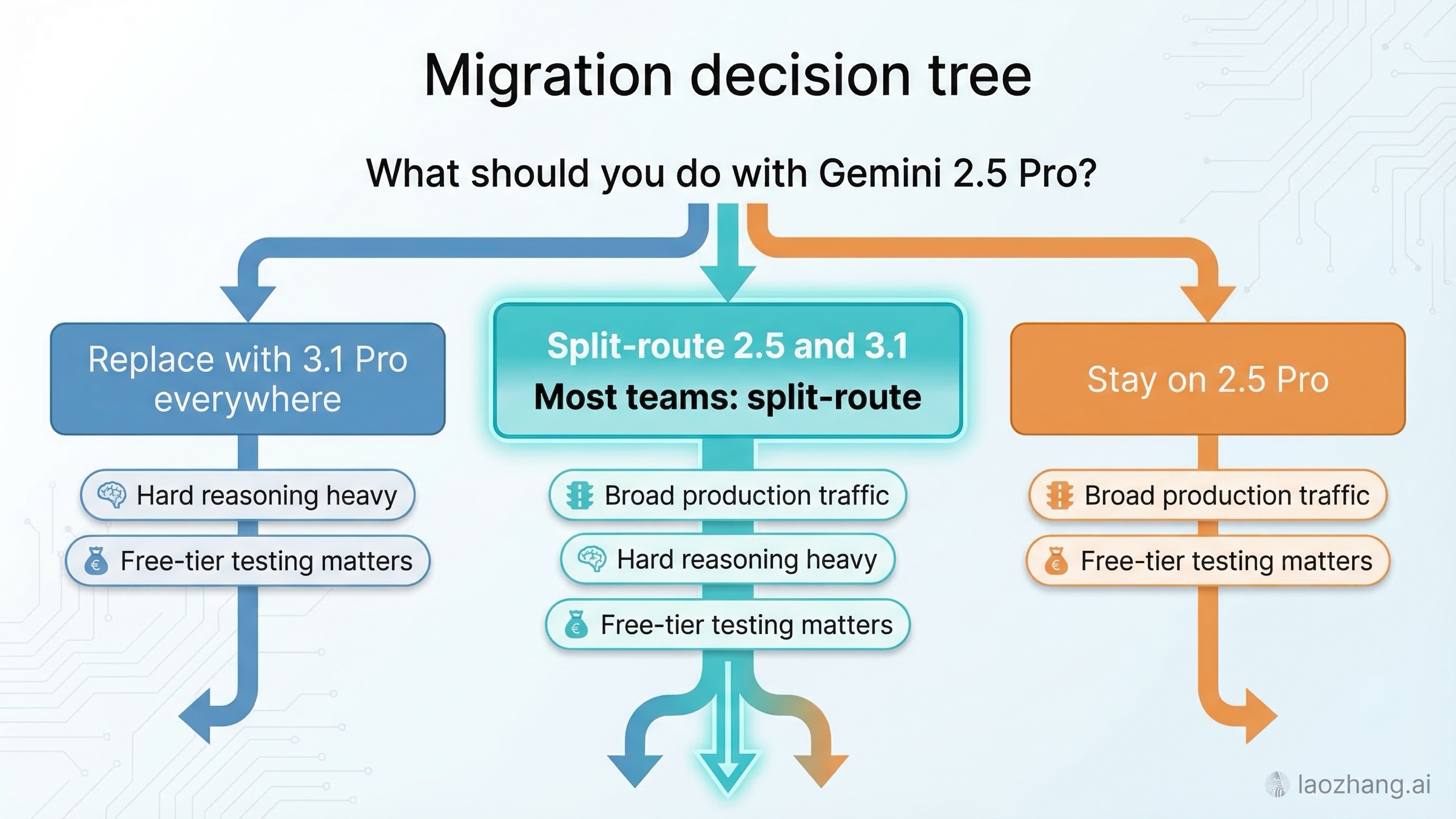
La mayoría de equipos deberían elegir uno de estos tres patrones.
Patrón 1: reemplazar todo por Gemini 3.1 Pro. Solo tiene sentido cuando tu carga está muy concentrada en razonamiento/coding agentic difícil y aceptas un preview como default global. Es la vía más agresiva y también la más propensa a decepcionar si no mediste calidad, latencia y coste con tráfico real.
Patrón 2: enrutamiento paralelo entre 2.5 y 3.1. Es la mejor respuesta general. Deja 2.5 como carril base y escala a 3.1 cuando se cumpla uno o más criterios:
- Prompt de alto impacto y revisión humana cara.
- Tasa de fallo en primera pasada de 2.5 ya afecta throughput.
- Tarea claramente agentic o multi-step, no single-shot.
- La prioridad es calidad de razonamiento por encima de coste.
Una política simple puede ser suficiente:
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
Patrón 3: quedarse en 2.5 Pro por ahora. No es inmovilismo; es decisión racional cuando tu calidad actual ya cumple, dependes de free tier para pruebas o la mejora de 3.1 no cambia resultados de negocio de forma tangible.
Checklist de migración limpio:
- Benchmark en prompts propios, no en demos genéricas.
- Medir calidad y minutos de corrección humana juntos.
- Mantener 2.5 como fallback hasta que 3.1 se pruebe en tráfico productivo.
- No asumir que 3.1 es "mejor en todo" por tener model card más fuerte.
- Promocionar 3.1 solo donde la ganancia medida compense coste y riesgo preview.
Ese último punto resume toda la guía: Gemini 3.1 Pro se promueve con evidencia, no por novedad.
FAQ
¿Gemini 3.1 Pro es mejor que Gemini 2.5 Pro?
Sí para razonamiento de alto nivel y trabajo agentic, según posicionamiento oficial y model card de 3.1. No si "mejor" significa "mejor en todo": 2.5 Pro sigue siendo más barato, GA y con free tier, así que para muchos equipos sigue siendo mejor default.
¿Gemini 3.1 Pro te da más contexto o más salida máxima?
No. A fecha del 19 de marzo de 2026, ambos modelos figuran con 1M de contexto y 64K de salida en la documentación oficial. Las diferencias clave son calidad, precio y estado de producto.
¿Gemini 3.1 Pro es más caro?
Sí. En la página oficial de precios, 3.1 Pro cuesta \$2.00 de input y \$12.00 de output por 1M tokens (hasta 200k tokens de prompt). 2.5 Pro cuesta \$1.25 de input y \$10.00 de output en ese tramo, y además mantiene free tier.
¿Debo migrar todo el tráfico de Gemini 2.5 Pro a Gemini 3.1 Pro?
Normalmente no. La estrategia general ganadora es mantener 2.5 como carril amplio y enviar solo tareas duras a 3.1. Reemplazo total solo cuando la mejora de razonamiento cambia tus métricas de negocio lo suficiente como para justificar prima de coste y estado preview.
¿Los benchmarks son totalmente comparables entre sí?
No. Son cifras oficiales, pero no provienen de un único documento unificado de mismo día y mismo harness. Léelos de forma direccional y combínalos con precio, estado y ajuste por carga de trabajo.
¿Esta comparación aplica igual para usuarios de Gemini app y para equipos API?
No exactamente. En app pesa más acceso por plan y selector de modelo. En API pesan más free tier, tarifas por token, batch, grounding y lógica de routing. Por eso esta guía prioriza la decisión de producción API.
Conclusión
Si necesitas el Gemini más fuerte hoy para razonamiento exigente y flujos agentic, elige Gemini 3.1 Pro. Si necesitas el mejor default para producción amplia, estable y sensible a costes, elige Gemini 2.5 Pro. Si puedes enrutar por tarea, usa ambos y deja que tu carga de trabajo dicte la elección.