
Los errores de Gemini API se dividen en dos categorías que requieren estrategias de manejo completamente diferentes: errores reintentables (429, 500, 503, 504) donde esperar y reintentar eventualmente tendrá éxito, y errores no reintentables (400, 403, 404) donde tu código o configuración necesita cambiar antes de que la solicitud pueda funcionar. Comprender esta distinción es el concepto más importante en el manejo de errores de API, y equivocarse significa desperdiciar tiempo reintentando solicitudes que nunca tendrán éxito o abandonar solicitudes que habrían funcionado con una breve espera. Esta guía cubre cada error que encontrarás, con código funcional que puedes copiar en tu proyecto hoy mismo.
Resumen rápido
Cada error de Gemini API corresponde a una de dos estrategias: reintentar con retroceso exponencial (para 429, 500, 503, 504) o corregir y redesplegar (para 400, 403, 404). El error 429 RESOURCE_EXHAUSTED representa aproximadamente el 90% de las quejas de los desarrolladores en 2026, en gran parte porque Google redujo silenciosamente los límites de la capa gratuita entre un 50-80% en diciembre de 2025. Si estás recibiendo errores 429 en la capa gratuita, tu camino más rápido hacia la resolución es activar la facturación para desbloquear los límites del Tier 1, lo cual generalmente surte efecto de inmediato. Para errores del servidor (500/503), consulta la página de estado de Google AI antes de depurar tu propio código. La tabla siguiente te ofrece una referencia rápida para cada código de error.
| Código HTTP | Estado gRPC | ¿Reintentable? | Primera acción |
|---|---|---|---|
| 400 | INVALID_ARGUMENT | No | Verifica el formato del cuerpo de la solicitud |
| 400 | FAILED_PRECONDITION | No | Activa la facturación o cambia la región |
| 403 | PERMISSION_DENIED | No | Verifica la clave API y los permisos |
| 404 | NOT_FOUND | No | Verifica el nombre del modelo y las rutas de recursos |
| 429 | RESOURCE_EXHAUSTED | Sí | Espera y reintenta con retroceso |
| 500 | INTERNAL | Sí | Reintenta después de 5-10 segundos |
| 503 | UNAVAILABLE | Sí | Reintenta después de 30-60 segundos |
| 504 | DEADLINE_EXCEEDED | Sí | Aumenta el timeout, reduce la entrada |
El árbol de decisión para la resolución de problemas
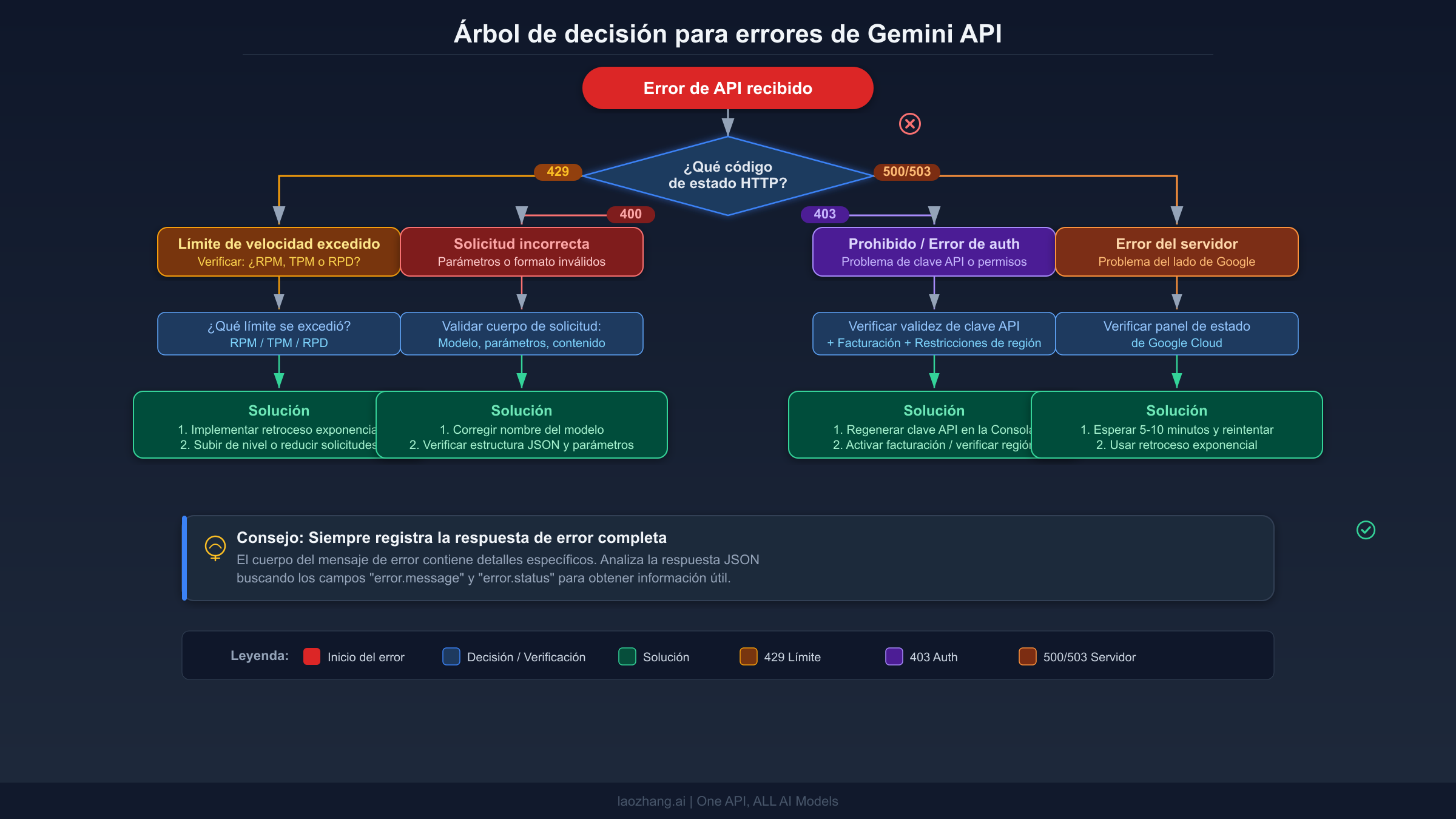
Cuando una solicitud a Gemini API falla, el código de estado HTTP te indica exactamente qué ruta de diagnóstico seguir. El primer paso crítico es leer el cuerpo completo de la respuesta de error, no solo el código de estado. Cada error de Gemini API devuelve un objeto JSON que contiene un campo status con el nombre del error gRPC y un campo message con detalles legibles que frecuentemente apuntan directamente al problema. Muchos desarrolladores cometen el error de capturar excepciones a nivel HTTP y descartar este detalle, lo que convierte una corrección de cinco minutos en una hora de suposiciones.
La secuencia de diagnóstico funciona así. Primero, verifica si el código de estado está en el rango 4xx o en el rango 5xx. Si es 4xx, el problema está de tu lado y reintentar no ayudará. Necesitas examinar el mensaje de error, identificar qué está mal con tu solicitud, corregirlo e intentar de nuevo. Si es 5xx, el problema probablemente está del lado de Google. Consulta la página de estado y, si el servicio parece saludable, implementa lógica de reintentos con retroceso exponencial. La única excepción a esta división limpia es el error 429, que técnicamente es un código 4xx pero se comporta como un error transitorio que se resuelve por sí solo cuando esperas lo suficiente o reduces tu tasa de solicitudes.
Para cada tipo de error, sigue esta secuencia. Comienza registrando la respuesta de error completa incluyendo los encabezados, particularmente el encabezado Retry-After para errores 429. Luego verifica si has visto este error anteriormente en tus registros. Los errores 400 recurrentes en el mismo endpoint sugieren un problema sistemático con la forma en que estás construyendo las solicitudes. Los errores 429 esporádicos sugieren que necesitas limitación de velocidad en tu código cliente. Los errores 403 consistentes después de un despliegue sugieren un problema con variables de entorno o gestión de secretos. Comprender estos patrones ahorra un tiempo significativo de depuración. Si estás trabajando con Gemini CLI y encuentras errores 429 persistentes, ten en cuenta que el CLI tiene su propio comportamiento de limitación de velocidad separado de las llamadas directas a la API, como se documenta en el issue #10722 de gemini-cli en GitHub.
Análisis profundo — 429 RESOURCE_EXHAUSTED (El error más común)
El error 429 RESOURCE_EXHAUSTED es con diferencia el error de Gemini API que se encuentra con más frecuencia, y su prevalencia se disparó después de que Google redujera silenciosamente los límites de la capa gratuita entre un 50-80% el 6-7 de diciembre de 2025. Antes de esa fecha, Gemini 2.0 Flash ofrecía 10 RPM en la capa gratuita. Después del cambio, bajó a 5 RPM, y los límites diarios de solicitudes experimentaron reducciones similares en todos los modelos. Este cambio no fue anunciado a través de canales oficiales y tomó desprevenidos a miles de desarrolladores. Si tu aplicación funcionaba perfectamente en noviembre de 2025 pero comenzó a lanzar errores 429 en diciembre sin ningún cambio en el código, esta es casi con certeza la razón.
Gemini API mide tu uso en tres dimensiones independientes, y exceder cualquiera de ellas activa un error 429. Estas dimensiones son RPM (Solicitudes Por Minuto), TPM (Tokens Por Minuto de entrada) y RPD (Solicitudes Por Día). Esto significa que puedes estar bien dentro de tu límite de RPM pero aún así ser limitado porque unas pocas solicitudes grandes te empujaron por encima del umbral de TPM. Los límites actuales de la capa gratuita, verificados contra la documentación oficial el 17 de marzo de 2026, se muestran a continuación.
| Modelo | RPM Gratuito | RPD Gratuito | TPM Gratuito |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 |
Fuente: ai.google.dev/gemini-api/docs/rate-limits, verificado 2026-03-17
Los límites de velocidad se aplican por proyecto, no por clave API. Esta es una distinción crucial que confunde a muchos desarrolladores. Crear múltiples claves API dentro del mismo proyecto de Google Cloud no te otorga cuota adicional. Si necesitas más capacidad, necesitas un proyecto separado (lo cual va contra los términos de servicio de Google si se hace para eludir los límites) o una actualización a un nivel de pago.
Diagnosticando cuál límite alcanzaste
Cuando recibes un error 429, el mensaje de respuesta generalmente te indica qué límite específico fue excedido, pero no siempre de forma clara. A continuación te explicamos cómo identificar sistemáticamente el cuello de botella. Primero, verifica tu uso en la Consola de Google Cloud bajo APIs y Servicios > Gemini API > Cuotas. Si tu uso de RPM se dispara pero el TPM permanece bajo, estás realizando demasiadas solicitudes pequeñas y deberías agruparlas. Si el TPM se dispara pero el RPM es moderado, tus solicitudes contienen demasiados datos de entrada y deberías reducir la longitud del contexto o cambiar a un modelo más pequeño. Si el RPD es el factor limitante, has alcanzado el tope diario y necesitas esperar hasta la medianoche hora del Pacífico para el reinicio o actualizar tu nivel.
El problema del "429 fantasma"
A principios de 2026, múltiples desarrolladores con cuentas de pago Tier 1 reportaron recibir errores 429 RESOURCE_EXHAUSTED a pesar de que sus paneles de uso mostraban consumo cero o casi cero. Este fenómeno del "429 fantasma" parece ser un error del lado del servidor en el sistema de seguimiento de cuotas de Google. Si estás experimentando esto, primero verifica que tu panel esté mirando el proyecto correcto. Luego verifica si tienes algún trabajo de API por lotes en ejecución, ya que las operaciones por lotes consumen cuotas separadas que pueden no aparecer en el panel en tiempo real. Si ninguna de las dos opciones aplica, el consenso de la comunidad es esperar 15-30 minutos, ya que el problema típicamente se resuelve solo. Si persiste más de una hora, presenta un ticket de soporte a través del Foro de Desarrolladores de Google AI. Puedes encontrar discusión en curso sobre este problema en hilos como este reporte en el Foro de Desarrolladores de Google AI, donde varios desarrolladores han compartido soluciones alternativas.
Pasos prácticos para reducir errores 429 sin actualizar
Si actualizar a un nivel de pago no es factible de inmediato, varias estrategias de optimización pueden reducir drásticamente tu tasa de errores 429 en la capa gratuita. El enfoque más efectivo es el agrupamiento de solicitudes, donde combinas múltiples solicitudes pequeñas en menos solicitudes más grandes. Dado que la capa gratuita limita el RPM más agresivamente que el TPM, enviar una solicitud con 10 preguntas es mucho más eficiente que enviar 10 solicitudes separadas. Gemini API soporta conversaciones multitono dentro de una sola solicitud, lo que hace que esta optimización sea sencilla de implementar.
Otra técnica poderosa es la limitación de velocidad del lado del cliente, donde tu aplicación impone límites más estrictos que los de la API para mantener un margen de seguridad. Si la capa gratuita permite 10 RPM para Gemini 2.5 Flash, configura tu cliente para enviar como máximo 8 solicitudes por minuto. Este margen absorbe las variaciones de tiempo y previene el patrón frustrante de alcanzar el límite con tu última solicitud en una ráfaga. Puedes implementar esto con un simple algoritmo de token bucket o ventana deslizante. Agregar incluso un retraso de 100-300 milisegundos entre solicitudes consecutivas es frecuentemente suficiente para prevenir errores 429 relacionados con ráfagas.
Para aplicaciones que pueden tolerar mayor latencia, la API por lotes ofrece un enfoque fundamentalmente diferente para la gestión de cuotas. Las solicitudes por lotes tienen sus propios límites de velocidad separados (100 solicitudes concurrentes, límite de archivo de entrada de 2GB) y se procesan de forma asíncrona, lo que significa que no compiten con tus llamadas API en tiempo real por cuota. Google recomienda explícitamente la API por lotes para cargas de trabajo que no requieren respuestas inmediatas, como pipelines de procesamiento de datos, colas de generación de contenido y tareas de evaluación. Esta es una solución frecuentemente ignorada que puede eliminar los errores 429 por completo para casos de uso adecuados.
Para una guía más detallada enfocada específicamente en errores 429 incluyendo técnicas avanzadas de optimización, consulta nuestra guía detallada para corregir el error 429 RESOURCE_EXHAUSTED. Para un desglose completo de los límites de velocidad en todos los niveles y modelos, consulta nuestro desglose completo de límites de velocidad por nivel.
Corrigiendo errores 400 y 403 (No reintentables)
A diferencia de los errores 429, los errores 400 y 403 indican un problema fundamental con tu solicitud o autenticación que no se resolverá esperando. Reintentar estos errores sin cambiar nada es inútil y desperdicia tanto tu tiempo como la cuota de API.
400 INVALID_ARGUMENT — Tu solicitud está mal formada
El error 400 con estado INVALID_ARGUMENT significa que Gemini API recibió tu solicitud pero no pudo procesarla porque algo en el cuerpo de la solicitud está mal. Las causas más comunes son enviar un valor de parámetro no soportado, exceder el límite máximo de tokens de salida para un modelo dado, pasar un valor de temperatura o topP inválido, o referenciar un nombre de modelo que no existe o ha sido descontinuado.
Aquí hay un ejemplo concreto que atrapa a muchos desarrolladores. Los modelos Gemini 3.x requieren que el parámetro de temperatura permanezca en su valor predeterminado de 1.0. Establecerlo en 0.2 o 0.7, lo cual funciona perfectamente con los modelos Gemini 2.5, puede causar bucles o rendimiento degradado con los modelos Gemini 3 y puede activar un error 400. Siempre verifica las restricciones de parámetros específicas del modelo en la documentación de referencia de la API. La corrección para los errores 400 sigue un patrón consistente: lee el mensaje de error cuidadosamente, compara los parámetros de tu solicitud con la documentación y corrige la discrepancia.
python# BAD - Gemini 3 Pro Preview was shut down March 9, 2026 model = "gemini-3-pro-preview" # GOOD - Use the current model model = "gemini-2.5-flash" # Common 400 error: invalid parameter for model # BAD - temperature < 1.0 can cause issues with Gemini 3.x config = {"temperature": 0.3} # GOOD - use default temperature for Gemini 3.x config = {"temperature": 1.0}
400 FAILED_PRECONDITION — Restricción regional o de facturación
Esta variante del error 400 significa que tu cuenta no cumple con un prerrequisito para usar la API. Las dos causas más comunes son operar desde una región no soportada sin facturación habilitada e intentar usar funciones que requieren un nivel de pago. Si ves este error, navega a Google AI Studio y verifica si la facturación está habilitada en tu proyecto. Habilitar la facturación frecuentemente resuelve esto de inmediato, incluso si no tienes intención de gastar dinero, porque actualiza tu proyecto de la capa gratuita al Tier 1.
403 PERMISSION_DENIED — Problemas de autenticación y acceso
El error 403 significa que el servidor entendió tu solicitud pero se niega a autorizarla. Esto es casi siempre un problema de clave API. Las causas comunes incluyen usar una clave API del proyecto incorrecto, usar una clave que ha sido revocada o filtrada (Google bloquea proactivamente las claves filtradas detectadas en repositorios públicos), no tener habilitada la API de Lenguaje Generativo en tu proyecto de Google Cloud, o intentar acceder a un modelo personalizado sin la autenticación adecuada.
Si estás recibiendo errores 403 específicamente al acceder a la API desde una aplicación basada en navegador, ten en cuenta que los inicios de sesión múltiples de Google pueden causar conflictos de autenticación. El navegador puede intentar autenticarse usando las credenciales de una cuenta de trabajo que no tiene acceso a la API, incluso si tu cuenta personal sí lo tiene. La solución es cerrar sesión en todas las cuentas de Google e iniciar sesión nuevamente solo con la cuenta que tiene acceso a la API habilitado. Este es un problema sorprendentemente común, como se señala en los foros de soporte de Google. Para más información sobre la resolución de problemas de autenticación, consulta nuestra guía de resolución de errores de autenticación 401 que cubre problemas relacionados con credenciales en profundidad.
Construyendo lógica de reintentos a prueba de balas

La lógica de reintentos es tu primera línea de defensa contra errores transitorios (429, 500, 503, 504). El principio clave es el retroceso exponencial: comienza con un retraso corto y duplícalo después de cada intento fallido, añadiendo un jitter aleatorio pequeño para evitar que todos los clientes reintenten simultáneamente. Aquí tienes una implementación lista para producción en Python que maneja todos los errores reintentables de Gemini API.
pythonimport time import random import google.generativeai as genai from google.api_core import exceptions def call_gemini_with_retry( model_name: str, prompt: str, max_retries: int = 5, base_delay: float = 1.0, max_delay: float = 60.0 ): """Call Gemini API with exponential backoff retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except exceptions.ResourceExhausted as e: # 429 - Rate limited delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) wait_time = delay + jitter print(f"Rate limited (attempt {attempt + 1}/{max_retries}). " f"Waiting {wait_time:.1f}s...") time.sleep(wait_time) except exceptions.InternalServerError: # 500 - Server error delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) print(f"Server error (attempt {attempt + 1}/{max_retries}). " f"Retrying in {delay + jitter:.1f}s...") time.sleep(delay + jitter) except exceptions.ServiceUnavailable: # 503 - Service unavailable wait_time = min(30 * (2 ** attempt), 300) print(f"Service unavailable. Waiting {wait_time}s...") time.sleep(wait_time) except exceptions.InvalidArgument as e: # 400 - Do NOT retry, fix the request raise RuntimeError(f"Invalid request (not retryable): {e}") except exceptions.PermissionDenied as e: # 403 - Do NOT retry, fix credentials raise RuntimeError(f"Permission denied (not retryable): {e}") raise RuntimeError(f"Failed after {max_retries} attempts")
La misma lógica en Node.js usando el SDK oficial de Google Generative AI tiene este aspecto.
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function callGeminiWithRetry(modelName, prompt, maxRetries = 5) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response.text(); } catch (error) { const status = error.status || error.httpStatusCode; // Non-retryable errors — fail immediately if ([400, 403, 404].includes(status)) { throw new Error(`Non-retryable error ${status}: ${error.message}`); } // Retryable errors — wait and retry if ([429, 500, 503, 504].includes(status)) { const delay = Math.min(1000 * Math.pow(2, attempt), 60000); const jitter = Math.random() * delay * 0.1; console.log(`Error ${status}, attempt ${attempt + 1}/${maxRetries}. ` + `Waiting ${((delay + jitter) / 1000).toFixed(1)}s...`); await new Promise(r => setTimeout(r, delay + jitter)); continue; } throw error; // Unknown error, don't retry } } throw new Error(`Failed after ${maxRetries} attempts`); }
Tres detalles críticos que muchas implementaciones de reintentos hacen mal. Primero, nunca reintentes errores 400 o 403. Estos indican un problema en tu código o configuración que no se resolverá con el tiempo. Reintentarlos desperdicia cuota y retrasa tu corrección real. Segundo, añade jitter aleatorio a tus retrasos. Sin jitter, todos los clientes que alcanzaron un límite de velocidad al mismo tiempo reintentarán al mismo tiempo, creando una "estampida" que desencadena otra ronda de errores 429. Tercero, establece un tope máximo de retraso. El retroceso exponencial sin un tope puede producir esperas absurdamente largas después de varios fallos. Sesenta segundos es generalmente un máximo razonable para aplicaciones interactivas.
Manejando errores 500 y 503 del servidor
Los errores del servidor (5xx) significan que algo salió mal en la infraestructura de Google, no en tu código. La respuesta correcta es casi siempre reintentar después de un retraso, pero hay matices importantes para cada tipo de error que afectan cómo deberías responder.
Los errores 500 INTERNAL pueden ser genuinamente transitorios o pueden indicar que tu entrada es demasiado grande para que el modelo la procese. Si obtienes errores 500 consistentemente en la misma solicitud pero otras solicitudes funcionan bien, intenta reducir la longitud del contexto de entrada. La documentación de Gemini API señala que contextos de entrada excesivamente largos son un desencadenante conocido de errores 500, particularmente con modelos que soportan la ventana de contexto de 1 millón de tokens. Si estás procesando documentos grandes, considera dividirlos en fragmentos más pequeños y hacer múltiples solicitudes en lugar de enviar todo en una sola llamada.
Los errores 503 UNAVAILABLE típicamente indican que el servicio de Gemini está bajo carga pesada. Estos son más probables durante periodos de uso pico y durante los lanzamientos de modelos. Cuando encuentres un 503, tu primera acción debería ser verificar el Panel de Estado de Google Cloud para ver si hay un incidente conocido. Si lo hay, no queda más que esperar. Si la página de estado muestra todos los servicios como saludables, implementa lógica de reintentos con retrasos iniciales más largos, comenzando en 30 segundos en lugar del retraso inicial de 1 segundo usado para errores 429.
Los errores 504 DEADLINE_EXCEEDED significan que tu solicitud tardó más en procesarse de lo que el timeout del servidor permite. Esto es más comúnmente causado por prompts muy grandes o solicitudes que desencadenan cómputo extenso del modelo (como tareas de razonamiento complejo con el modo de pensamiento de Gemini 2.5 Pro). La solución típicamente es aumentar la configuración de timeout del lado del cliente. Si estás usando el SDK de Python, puedes pasar un parámetro timeout. Si estás haciendo solicitudes HTTP directas, ajusta el timeout de tu cliente HTTP a al menos 120 segundos para solicitudes grandes. Si los errores 504 persisten incluso con timeouts aumentados, considera cambiar a la API por lotes, que no tiene restricciones de timeout por solicitud.
Construyendo un panel de monitoreo para patrones de errores
Comprender tus patrones de errores a lo largo del tiempo es mucho más valioso que depurar errores individuales. Una configuración de monitoreo simple que registre cada código de estado de respuesta API, latencia y conteo de tokens puede revelar patrones invisibles a la depuración puntual. Por ejemplo, si los errores 429 se agrupan en momentos específicos del día, puede que estés compitiendo con otros usuarios en tu región durante horas pico. Si los errores 500 se correlacionan con longitudes de prompt específicas, has identificado un problema de límite de ventana de contexto.
El enfoque más práctico es registrar las respuestas API en un formato estructurado que puedas consultar después. Incluye la marca de tiempo, código de estado HTTP, mensaje de error, nombre del modelo, conteo de tokens de entrada y latencia de respuesta en cada entrada de registro. Incluso un simple archivo CSV o base de datos SQLite proporciona suficiente estructura para detectar tendencias. Muchos desarrolladores descubren que sus errores 429 provienen de una sola función o endpoint que hace volúmenes de solicitudes inesperadamente altos, y corregir ese único cuello de botella elimina la mayoría de sus errores. Si prefieres una solución gestionada, Google Cloud Operations (anteriormente Stackdriver) puede monitorear automáticamente tu uso de Gemini API a través de la Consola de Cloud, aunque esto requiere que tu proyecto esté vinculado a una cuenta de facturación de Google Cloud.
Cuándo actualizar — Análisis de capa gratuita vs nivel de pago
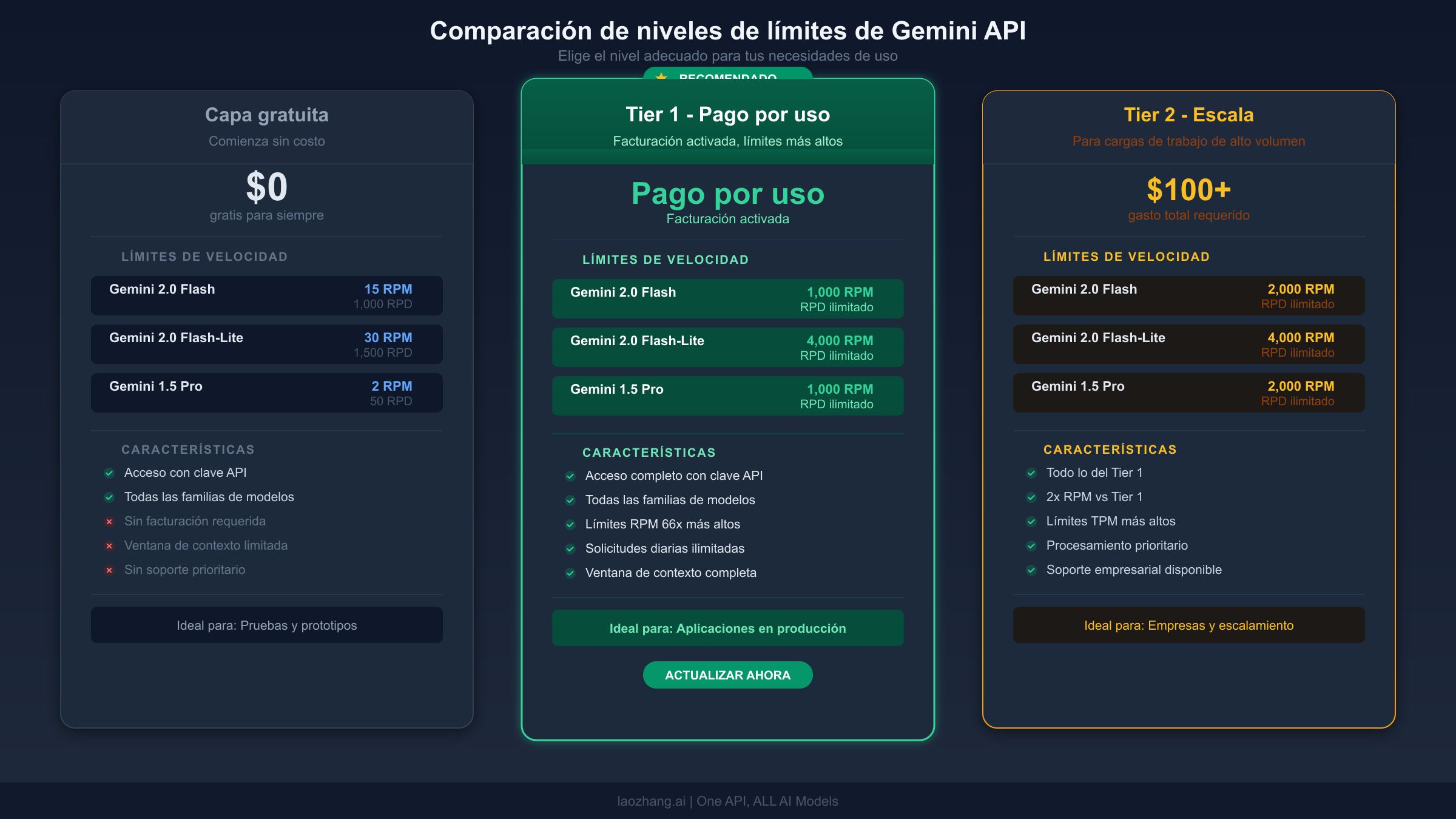
La decisión de actualizar de la capa gratuita a un nivel de pago es sencilla una vez que comprendes la estructura de costos. Gemini API utiliza un sistema escalonado donde tus límites de velocidad aumentan automáticamente a medida que crece tu gasto acumulado. Así funcionan los niveles, verificado contra la documentación oficial el 17 de marzo de 2026.
| Nivel | Cómo calificar | Beneficio clave |
|---|---|---|
| Gratuito | Registrarse con cuenta de Google | Limitado pero funcional para pruebas |
| Tier 1 | Activar una cuenta de facturación | Aumento inmediato de RPM/RPD (frecuentemente 10-20x) |
| Tier 2 | $100+ de gasto acumulado + 3 días | Capacidad sustancial para producción |
| Tier 3 | $1,000+ de gasto acumulado + 30 días | Límites de nivel empresarial |
Fuente: ai.google.dev/gemini-api/docs/rate-limits, verificado 2026-03-17
La actualización de Gratuito a Tier 1 es el cambio de mayor impacto que puedes hacer. Simplemente activar una cuenta de facturación, incluso antes de gastar dinero, desbloquea los límites del Tier 1 que son típicamente 10-20x superiores a los de la capa gratuita. La actualización surte efecto de inmediato. Si estás recibiendo errores 429 regularmente, este único paso resolverá la mayoría de los casos. Ten en cuenta que a partir del 1 de abril de 2026, Google comenzará a aplicar topes de gasto por nivel, así que revisa la documentación de facturación para comprender cualquier nuevo límite que pueda aplicarse a tu cuenta.
Para cargas de trabajo de producción donde incluso los límites del Tier 1 son insuficientes, considera una pasarela API unificada como laozhang.ai que agrega solicitudes a través de múltiples proveedores y ofrece límites de velocidad más altos sin limitación por proveedor. Este enfoque es particularmente valioso cuando tu aplicación necesita soportar patrones de tráfico en ráfagas que exceden los límites de cualquier proveedor individual. Puedes explorar la documentación en docs.laozhang.ai para ver cómo maneja la limitación de velocidad entre proveedores de forma transparente. Para un desglose completo de los precios de Gemini API en todos los niveles y modelos, consulta nuestra guía de precios y cuotas de Gemini API. También puedes comparar las limitaciones de la capa gratuita en detalle en nuestra guía de límites de velocidad de la capa gratuita.
Verificación de costos reales para desarrolladores individuales. Gemini 2.5 Flash, el modelo más popular para aplicaciones sensibles al costo, tiene un precio de $0.30 por millón de tokens de entrada y $2.50 por millón de tokens de salida en el nivel de pago (ai.google.dev/gemini-api/docs/pricing, verificado 2026-03-17). Para una aplicación típica que hace 1,000 solicitudes por día con tamaños de prompt promedio, el costo mensual resulta en aproximadamente $5-15 dependiendo de la longitud de la salida. Este es un costo trivial para cualquier aplicación que genera valor real, y la mejora en fiabilidad al eliminar errores 429 justifica con creces el gasto. La variante Gemini 2.5 Flash-Lite ofrece una opción aún más económica a $0.10 por millón de tokens de entrada para aplicaciones donde la calidad máxima no es crítica.
Para equipos que construyen aplicaciones de producción que necesitan acceder a múltiples proveedores de IA (Gemini, OpenAI, Anthropic y otros) a través de un único endpoint, una pasarela API unificada como laozhang.ai puede simplificar tu infraestructura mientras proporciona limitación de velocidad incorporada, balanceo de carga y conmutación por error automática entre proveedores. Esto es particularmente útil cuando quieres hacer failover de un proveedor a otro al alcanzar límites de velocidad, en lugar de simplemente reintentar contra el mismo endpoint limitado.
Cambios de modelos en 2026 que afectan el manejo de errores
El panorama de modelos de Gemini ha cambiado significativamente a principios de 2026, y varios de estos cambios impactan directamente el manejo de errores. Si estás encontrando errores que comenzaron recientemente sin cambios de código de tu parte, una de estas transiciones de modelos puede ser la causa.
Gemini 3 Pro Preview fue descontinuado y cerrado el 9 de marzo de 2026. Si tu código referencia gemini-3-pro-preview o nombres de modelos preview similares, recibirás errores 400 INVALID_ARGUMENT o 404 NOT_FOUND. La ruta de migración recomendada es usar gemini-3.1-pro-preview o gemini-2.5-pro como alternativa estable. Los modelos preview inherentemente conllevan este riesgo, y las aplicaciones de producción siempre deberían apuntar a versiones estables de modelos cuando estén disponibles.
Gemini 2.0 Flash está descontinuado y programado para cerrarse el 1 de junio de 2026. Si actualmente estás usando gemini-2.0-flash o gemini-2.0-flash-lite, planifica tu migración a gemini-2.5-flash o gemini-2.5-flash-lite antes de la fecha límite. Los modelos más nuevos ofrecen mejor rendimiento al mismo costo o menor, pero pueden tener comportamientos de parámetros ligeramente diferentes que podrían activar errores 400 si tu configuración dependía de valores predeterminados específicos del modelo.
Gemini Embedding 2 fue anunciado como el primer modelo de embeddings completamente multimodal. Si estás construyendo aplicaciones RAG, este nuevo modelo puede reducir errores relacionados con incompatibilidades de formato de entrada al generar embeddings de diferentes tipos de contenido. La línea actual de modelos incluye Gemini 3.1 Pro Preview, 3.1 Flash-Lite Preview, 3 Flash Preview y la familia completa de Gemini 2.5 (Pro, Flash, Flash-Lite) junto con sus variantes TTS. Siempre verifica la cadena exacta del nombre del modelo contra la lista oficial de modelos antes de usarlo en código de producción, ya que incluso pequeños errores tipográficos en los nombres de modelos causarán errores 404.
FAQ — Preguntas frecuentes sobre errores de Gemini API
¿Cómo corrijo el error 429 Too Many Requests de Gemini API?
La corrección más rápida es agregar un retraso entre solicitudes, incluso 100-300 milisegundos es frecuentemente suficiente para prevenir ráfagas de alta frecuencia. Para una solución a largo plazo, implementa lógica de reintentos con retroceso exponencial (consulta los ejemplos de código en Python y Node.js en la sección de reintentos anterior). Si estás en la capa gratuita y recibes errores 429 regularmente, actualizar al Tier 1 habilitando la facturación incrementará inmediatamente tus límites de velocidad en 10-20x.
¿Qué causa el error 403 PERMISSION_DENIED en Gemini API?
El error 403 casi siempre indica un problema de clave API. Las causas más comunes son: usar una clave API de un proyecto de Google Cloud diferente al que tiene habilitada Gemini API, usar una clave que Google ha bloqueado porque fue detectada en un repositorio público, no tener habilitada la API de Lenguaje Generativo en tu proyecto, o conflictos de autenticación del navegador cuando hay múltiples cuentas de Google iniciadas. Verifica tu clave en Google AI Studio y regénérala si es necesario.
¿Por qué recibo errores 429 aunque mi panel de uso muestra cero?
Este es el problema del "429 fantasma" reportado por múltiples desarrolladores a principios de 2026. Parece ser un error del lado del servidor en el seguimiento de cuotas de Google. Primero verifica que estés mirando el proyecto correcto en el panel. Verifica si hay trabajos de API por lotes en ejecución que consumen cuotas separadas. Si ninguno aplica, espera 15-30 minutos ya que el problema típicamente se resuelve solo. Si persiste, repórtalo a través del Foro de Desarrolladores de Google AI.
¿El error 500 es culpa mía o de Google?
El error 500 INTERNAL es casi siempre un problema del lado de Google, pero hay una excepción importante. Si tu contexto de entrada es extremadamente grande, acercándose o excediendo la ventana de contexto del modelo, el servidor puede fallar al procesarlo y devolver un error 500 en lugar de un código de error más descriptivo. Comienza verificando el Panel de Estado de Google Cloud para ver si hay un incidente conocido. Si el servicio parece saludable pero obtienes errores 500 consistentemente en la misma solicitud mientras otras solicitudes funcionan bien, intenta reducir el tamaño de tu entrada. Corta tu prompt a la mitad y observa si el error desaparece. Si desaparece, has encontrado el límite. Para errores 500 esporádicos que afectan solicitudes aleatorias, simplemente implementa lógica de reintentos con retroceso exponencial. Los servidores de Google experimentan fallos transitorios como cualquier sistema distribuido, y la mayoría de los errores 500 se resuelven en segundos.
¿Cuál es la diferencia entre 503 UNAVAILABLE y 504 DEADLINE_EXCEEDED?
El error 503 significa que el servicio de Gemini está temporalmente sobrecargado y no puede aceptar tu solicitud en este momento. Este es un problema de capacidad del lado de Google, similar a recibir una señal de ocupado al llamar a una línea telefónica. Generalmente se resuelve en minutos y es más común durante periodos de uso pico o inmediatamente después de que Google anuncia una nueva función de modelo. El error 504, por otro lado, significa que el servidor aceptó tu solicitud y comenzó a procesarla, pero no pudo terminar dentro del tiempo asignado. Esto es típicamente causado por prompts muy grandes o tareas de razonamiento complejas, especialmente con modelos como Gemini 2.5 Pro en modo de pensamiento. Para el 503, espera 30-60 segundos y reintenta. Para el 504, aumenta la configuración de timeout de tu cliente a al menos 120 segundos para solicitudes grandes, o considera dividir tu entrada en fragmentos más pequeños.
¿Cómo evito que los errores de API afecten a mis usuarios?
La mejor estrategia es la defensa en profundidad. Primero, implementa lógica de reintentos con retroceso exponencial para todos los errores reintentables, de modo que los fallos transitorios sean invisibles para tus usuarios. Segundo, añade un patrón de circuit breaker que deje de enviar solicitudes después de múltiples fallos consecutivos, previniendo errores en cascada. Tercero, configura un comportamiento de respaldo, como devolver respuestas en caché o cambiar a un modelo diferente cuando tu modelo principal no esté disponible. Cuarto, configura monitoreo y alertas para que sepas sobre picos de errores antes de que tus usuarios se quejen. Incluso un simple correo electrónico diario mostrando tu tasa de errores por código de estado puede detectar problemas tempranamente. Para aplicaciones de producción, considera mantener acceso API a través de múltiples proveedores para que un límite de velocidad o una interrupción en un proveedor no tumbe toda tu aplicación.
¿Puedo ser baneado de Gemini API por recibir demasiados errores 429?
Google no banea cuentas simplemente por alcanzar límites de velocidad, ya que los errores 429 son una parte esperada del uso normal de la API. Sin embargo, Google bloquea proactivamente las claves API que se detectan en repositorios públicos, ya que estas representan un riesgo de seguridad. Si tu clave API aparece en un repositorio público de GitHub, Google la bloqueará y recibirás un mensaje de error específico indicando que tu clave fue reportada como filtrada. La solución es generar una nueva clave API a través de Google AI Studio y asegurarte de que se almacene de forma segura usando variables de entorno en lugar de codificarla directamente en tu código fuente. Además, crear múltiples proyectos de Google Cloud para eludir los límites de velocidad va contra los términos de servicio de Google y podría resultar en restricciones a nivel de cuenta.