
Febrero de 2026 trajo una oleada sin precedentes de modelos frontera de IA en cuestión de semanas, y el panorama comparativo ya está repleto de precios desactualizados y tablas superficiales de benchmarks. Después de verificar cada dato directamente desde las páginas oficiales de precios, podemos afirmar con confianza que no existe un único ganador entre Gemini 3.1 Pro, Claude Opus 4.6 y GPT-5.3-Codex. Cada modelo domina dominios distintos: Gemini lidera en razonamiento científico y eficiencia de costos a $2 por millón de tokens de entrada, Opus sobresale en codificación agéntica con su arquitectura única de Agent Teams, y Codex ofrece una velocidad de ejecución autónoma inigualable a través de su entorno aislado. Lo que sigue es la comparación más exhaustivamente verificada disponible a marzo de 2026.
Resumen rápido
Antes de profundizar en los detalles, aquí está la comparación esencial en las dimensiones que más importan a los desarrolladores que toman decisiones de producción en este momento. Cada cifra de precio en esta tabla fue verificada directamente desde las páginas oficiales de precios utilizando automatización de navegador el 2 de marzo de 2026, y descubrimos que varios artículos de la competencia citan datos de precios incorrectos, particularmente para Opus 4.6. Esto importa porque los desarrolladores que toman decisiones de infraestructura basándose en números de precios erróneos pueden fácilmente sobreestimar o subestimar su presupuesto en miles de dólares al mes, lo que lleva a recursos desperdiciados o a sobrecostos inesperados que obligan a cambiar de modelo a mitad de proyecto.
| Característica | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.3-Codex |
|---|---|---|---|
| Lanzamiento | 19 feb 2026 | 5 feb 2026 | Feb 2026 |
| Precio entrada | $2/MTok | $5/MTok | No en API |
| Precio salida | $12/MTok | $25/MTok | No en API |
| Ventana de contexto | 1M (GA) | 200K / 1M (beta) | 400K |
| Salida máxima | 64K | 128K | 128K |
| Mejor benchmark | ARC-AGI-2: 77,1% | SWE-Bench: 80,8% | Terminal-Bench: 77,3% |
| Punto fuerte | Investigación, Ciencia, Contexto largo | Codificación compleja, Agentes | Ejecución autónoma |
| Acceso API | API estándar | API estándar | Solo productos Codex |
La conclusión más crítica es que GPT-5.3-Codex no tiene precios de API independientes en la página de precios de OpenAI. Está disponible exclusivamente a través de la aplicación Codex, la CLI, extensiones de IDE y GitHub Copilot, lo que lo hace fundamentalmente diferente de los otros dos modelos en términos de cómo se integra en tu flujo de trabajo. Si necesitas una llamada API directa con facturación por token, tu elección real está entre Gemini 3.1 Pro y Claude Opus 4.6, y la decisión se reduce a si priorizas la eficiencia de costos y la amplitud de razonamiento o la profundidad de codificación agéntica y la fiabilidad. Exploramos cada una de estas dimensiones en detalle exhaustivo a continuación, comenzando con los números de benchmarks que definen el territorio competitivo de cada modelo, luego pasando a la realidad de precios que la mayoría de artículos interpreta erróneamente, y finalmente llegando a un marco de decisión práctico que mapea tu flujo de trabajo específico al modelo correcto.
Comparación directa de benchmarks: ¿quién gana qué?
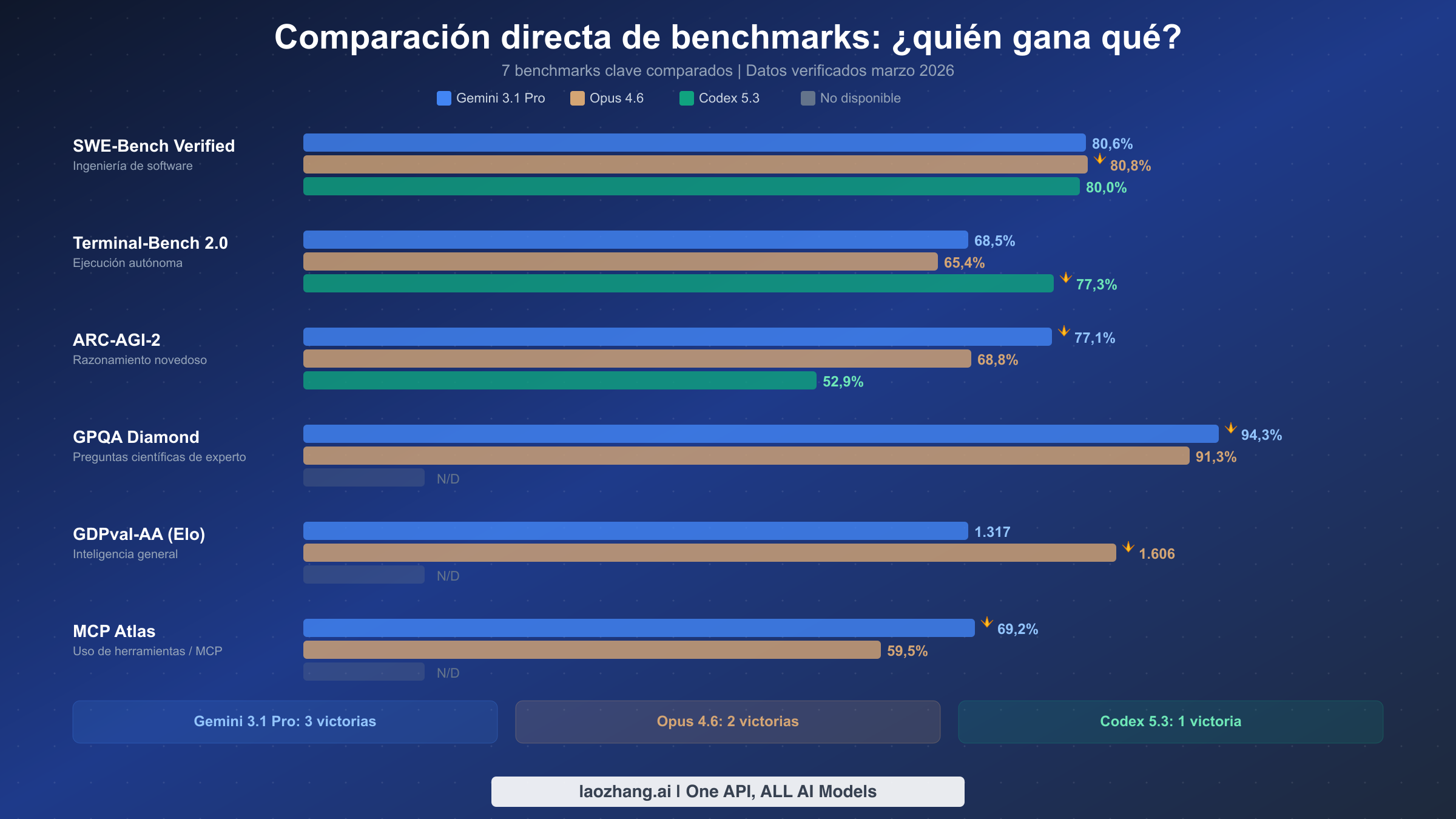
El panorama de benchmarks de estos tres modelos revela un patrón que desafía la narrativa simplista de "un modelo para gobernarlos a todos". Cada modelo ha conquistado territorio diferenciado, y comprender dónde sobresale cada uno requiere mirar más allá de los números brutos para entender lo que los benchmarks realmente miden.
SWE-Bench Verified, el estándar de oro para la evaluación de ingeniería de software, muestra una carrera increíblemente reñida. Opus 4.6 se adelanta ligeramente con un 80,8%, seguido por Gemini 3.1 Pro con un 80,6% y Codex 5.3 con un 80,0%. Las diferencias aquí están dentro del margen de variación para la mayoría de propósitos prácticos, lo que significa que los tres modelos son aproximadamente equivalentes para resolver issues reales de GitHub. Esto es notable porque no era el caso hace apenas seis meses, cuando había una brecha clara entre el modelo líder y el resto. Para un análisis más profundo de cómo se comparan específicamente Opus y Codex en tareas de codificación, consulta nuestra comparación detallada de Opus 4.6 vs GPT-5.3.
Terminal-Bench 2.0 cuenta una historia muy diferente y es donde Codex 5.3 realmente brilla con un 77,3%, muy por delante del 68,5% de Gemini y el 65,4% de Opus. Este benchmark mide la capacidad de ejecución autónoma, es decir, la habilidad del modelo para operar un terminal, ejecutar comandos, depurar fallos y completar tareas de múltiples pasos sin intervención humana. La ventaja de Codex aquí tiene sentido dado que fue diseñado específicamente en torno a entornos de ejecución aislados donde el modelo puede ejecutar código libremente, verificar salidas e iterar sobre soluciones. Este es el benchmark que más importa si tu caso de uso implica delegar tareas completas a un agente de IA y esperar trabajo completado de vuelta.
ARC-AGI-2 mide la capacidad de razonamiento novedoso, y Gemini 3.1 Pro domina con un 77,1% en comparación con el 68,8% de Opus y el 52,9% de Codex. Esta es la mayor brecha entre dos modelos cualesquiera en cualquier benchmark, y refleja la inversión de Google en capacidades de razonamiento a través de su arquitectura Mixture-of-Experts. El benchmark ARC-AGI-2 prueba específicamente la capacidad de resolver problemas que el modelo nunca ha visto antes, convirtiéndolo en un indicador de inteligencia general más que de coincidencia de patrones contra datos de entrenamiento.
GPQA Diamond, que evalúa respuestas a preguntas científicas de nivel experto, muestra a Gemini 3.1 Pro con un 94,3% frente al 91,3% de Opus 4.6. Codex 5.3 no tiene una puntuación publicada para este benchmark. La brecha de tres puntos aquí es significativa porque las preguntas de GPQA Diamond están diseñadas para ser desafiantes incluso para expertos de nivel doctoral en su dominio. Si tu flujo de trabajo involucra investigación científica, razonamiento médico o tareas analíticas complejas, Gemini tiene una ventaja medible.
GDPval-AA, medido en puntuación Elo, muestra a Opus 4.6 liderando con 1.606 en comparación con los 1.317 de Gemini. Este benchmark evalúa el seguimiento general de instrucciones y la coherencia en el diálogo, un área donde el enfoque de entrenamiento de IA Constitucional de Anthropic parece rendir dividendos. La brecha de 289 puntos Elo es sustancial y sugiere que Opus produce respuestas más consistentemente de alta calidad y matizadas en entornos conversacionales. Para una comparación centrada en cómo se comparan estos dos modelos, consulta nuestro análisis directo de Gemini 3.1 Pro vs Opus 4.6.
Un benchmark adicional que vale la pena mencionar es MCP Atlas, que mide cuán efectivamente los modelos utilizan herramientas externas a través del Model Context Protocol. Gemini 3.1 Pro obtiene un 69,2% en comparación con el 59,5% de Opus 4.6, y Codex 5.3 no reporta una puntuación. Esto es particularmente relevante para desarrolladores que construyen aplicaciones agénticas donde el modelo necesita orquestar llamadas a bases de datos, APIs y sistemas de archivos. La ventaja de Gemini aquí sugiere que su arquitectura MoE enruta consultas de uso de herramientas a expertos especializados que manejan la comprensión de esquemas de API y la generación de parámetros de manera más efectiva.
La conclusión es que ningún modelo gana en todos los benchmarks. Gemini 3.1 Pro lidera en razonamiento y ciencia (3 victorias en benchmarks incluyendo los cruciales ARC-AGI-2 y MCP Atlas), Opus 4.6 lidera en calidad de codificación e inteligencia general (2 victorias en SWE-Bench y GDPval-AA), y Codex 5.3 domina la ejecución autónoma (1 victoria en Terminal-Bench, pero con un margen decisivo de 12 puntos). Tu elección debería estar guiada por qué categoría de benchmark se alinea más estrechamente con tu carga de trabajo real, y para la mayoría de equipos, eso significa evaluar honestamente si tu cuello de botella es la calidad de razonamiento, la corrección del código o la automatización de la ejecución.
Precios reales: ¿cuánto cuestan realmente estos modelos en 2026?
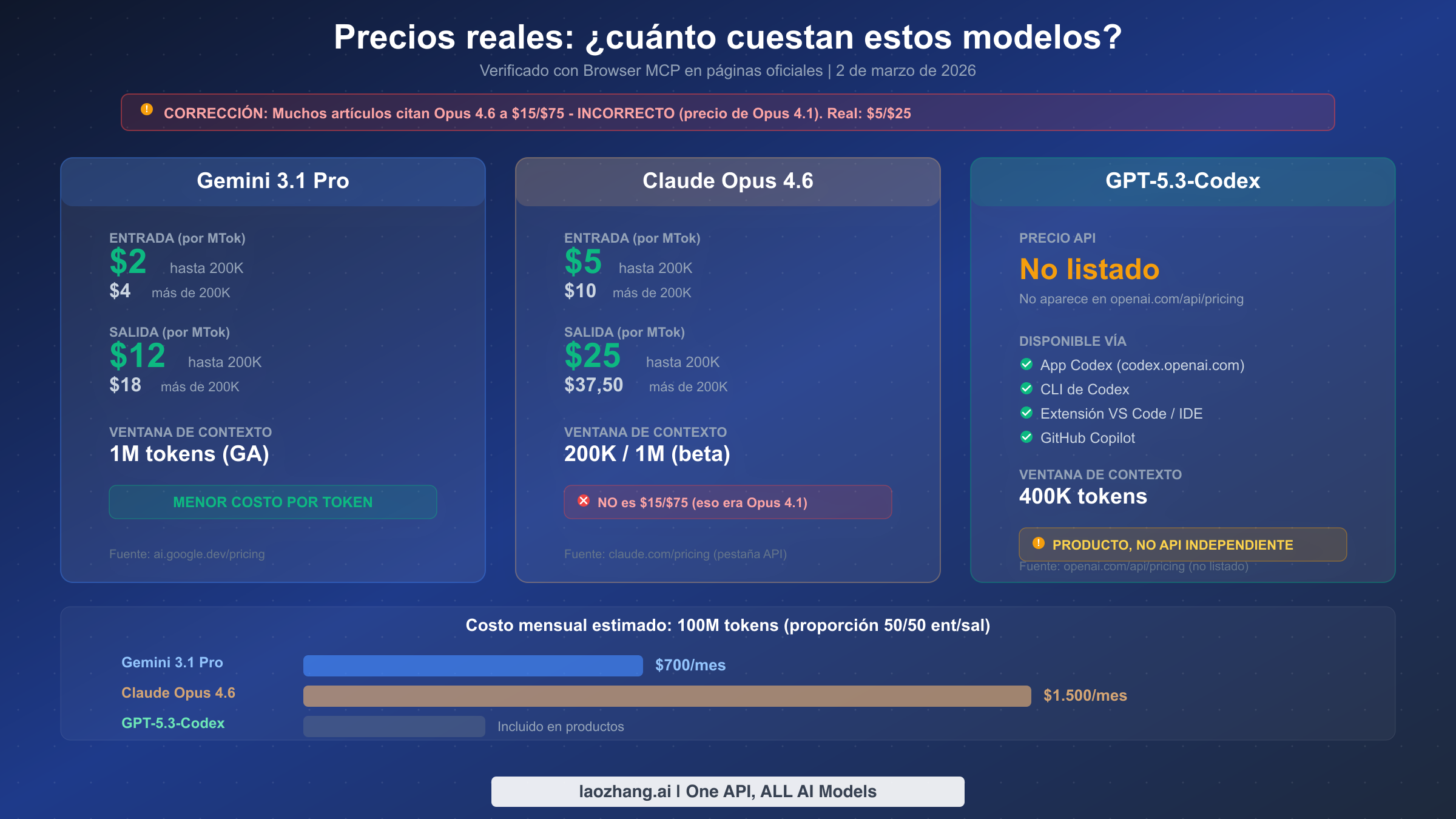
Los precios son donde encontramos la desinformación más peligrosa en los artículos de comparación existentes. Múltiples artículos con posiciones altas en buscadores citan los precios de Claude Opus 4.6 como $15 por millón de tokens de entrada y $75 por millón de tokens de salida. Esto es incorrecto. Esos son los precios heredados de Opus 4.1 y 4.0. El precio real de Opus 4.6, verificado directamente desde claude.com/pricing el 2 de marzo de 2026, es de $5 por millón de tokens de entrada y $25 por millón de tokens de salida para prompts de hasta 200K de contexto. Para prompts más largos que excedan los 200K tokens, el precio aumenta a $10 de entrada y $37,50 de salida por millón de tokens.
Gemini 3.1 Pro ofrece los precios por token más competitivos de cualquier modelo frontera actualmente disponible a través de una API estándar. A $2 por millón de tokens de entrada y $12 por millón de tokens de salida (verificado desde ai.google.dev/pricing el 2 de marzo de 2026), es un 60% más barato que Opus 4.6 en entrada y un 52% más barato en salida. Para prompts que excedan los 200K tokens, los precios de Gemini se duplican a $4 de entrada y $18 de salida, lo cual sigue siendo sustancialmente más barato que las tarifas de contexto extendido de Opus. Si estás ejecutando cargas de trabajo de inferencia de alto volumen y el costo es una preocupación principal, esta ventaja de precio se acumula rápidamente. Para detalles completos sobre los niveles de precios y descuentos de Gemini, consulta nuestros detalles de precios de la API de Gemini para 2026.
GPT-5.3-Codex presenta un modelo de precios completamente diferente porque no aparece en la página de precios de API de OpenAI en absoluto. Verificamos esto navegando a openai.com/api/pricing el 2 de marzo de 2026 y encontramos GPT-5.2 listado a $1,75/$14 por millón de tokens, pero GPT-5.3-Codex estaba ausente. Esto significa que no puedes llamarlo a través de un endpoint de API estándar con facturación por token. En su lugar, accedes a él a través de los productos Codex: la aplicación web en codex.openai.com, la CLI de Codex, extensiones de IDE o GitHub Copilot. El costo está incluido en tu suscripción existente de OpenAI o GitHub en lugar de facturarse por token, lo que hace difícil la comparación directa de costos con los otros dos modelos.
Costo total de propiedad: tres escenarios del mundo real
Para hacer los precios prácticos, considera estos tres escenarios de uso con costos mensuales estimados:
Escenario 1: Desarrollador individual (10M tokens/mes, proporción 60/40 entrada/salida). Para un desarrollador que usa un asistente de codificación de IA durante toda su jornada laboral, Gemini 3.1 Pro costaría aproximadamente $60 al mes, mientras que Opus 4.6 costaría aproximadamente $130. Codex 5.3 está efectivamente incluido en una suscripción de ChatGPT Pro a $200/mes o una suscripción empresarial de GitHub Copilot, lo que lo hace rentable solo si ya pagas por esos servicios.
Escenario 2: Pipeline de revisión de código de equipo pequeño (100M tokens/mes, proporción 70/30 entrada/salida). Un equipo de 5 a 10 desarrolladores ejecutando revisión de código automatizada gastaría aproximadamente $500 al mes en Gemini 3.1 Pro versus aproximadamente $1.100 en Opus 4.6. A esta escala, la brecha de precios se vuelve significativa, y los equipos deberían considerar seriamente si las mejoras de calidad de codificación de Opus justifican un premium de costo de 2,2 veces. Para equipos que ya utilizan servicios de agregación de API como laozhang.ai, la facturación unificada en múltiples modelos puede simplificar la gestión de costos manteniendo tarifas competitivas.
Escenario 3: Pipeline de agentes empresarial (1B tokens/mes, proporción 50/50). A escala empresarial, Gemini 3.1 Pro cuesta aproximadamente $7.000 al mes mientras que Opus 4.6 ronda los $15.000. Sin embargo, Anthropic ofrece descuentos significativos en procesamiento por lotes (50% de descuento) y descuentos por caché de prompts que pueden reducir considerablemente esta brecha. Para un desglose completo de los niveles de precios de Claude, consulta nuestro análisis completo de precios de la API de Claude.
La decisión de precios depende en última instancia de si la diferencia de calidad entre modelos justifica el premium de costo para tu caso de uso específico. Para cargas de trabajo intensivas en razonamiento, Gemini ofrece la mejor relación calidad-precio. Para tareas de codificación complejas donde las diferencias de calidad se traducen en menos errores y menos retrabajo, el premium de Opus puede pagarse por sí mismo.
Cómo acceder a cada modelo: API, CLI y más allá
Uno de los aspectos más malinterpretados de esta comparación a tres bandas es cómo realmente accedes a cada modelo. Mientras que Gemini 3.1 Pro y Claude Opus 4.6 siguen el patrón familiar de "obtener una clave API y hacer solicitudes HTTP", GPT-5.3-Codex rompe completamente con este modelo, y comprender esta distinción es esencial antes de comprometer a tu equipo con un flujo de trabajo particular.
Gemini 3.1 Pro es accesible a través de AI Studio de Google y la plataforma Vertex AI. Generas una clave API en ai.google.dev, y las llamadas siguen el patrón REST estándar con el identificador de modelo gemini-3.1-pro-preview. Google también ofrece bibliotecas cliente para Python, JavaScript, Go y otros lenguajes. El modelo está actualmente en estado "Preview", lo que significa que Google podría hacer cambios incompatibles antes de la disponibilidad general, pero en la práctica la API ha sido estable desde su lanzamiento. Una ventaja notable es que Gemini ofrece un nivel gratuito con límites de velocidad generosos, haciéndolo accesible para experimentación sin necesidad de tarjeta de crédito.
Claude Opus 4.6 está disponible a través de la API de Anthropic con el identificador de modelo claude-opus-4-6. El acceso requiere una clave API de console.anthropic.com. Anthropic proporciona SDKs oficiales para Python y TypeScript, y la API sigue un formato limpio y bien documentado. Opus 4.6 ya tiene Disponibilidad General (GA), lo que significa que la API es estable y lista para producción. El modelo también es accesible a través de Claude.ai, Claude Code (la herramienta CLI de Anthropic) y varias integraciones de IDE. Para casos de uso agéntico, Opus 4.6 soporta la función Agent Teams a través de Claude Code, permitiéndole generar subagentes que trabajan en paralelo en tareas complejas.
GPT-5.3-Codex requiere un enfoque fundamentalmente diferente. No existe un endpoint de modelo gpt-5.3-codex en la API de OpenAI. En su lugar, accedes a él a través de cuatro canales: la aplicación web Codex en codex.openai.com donde asignas tareas que el modelo trabaja de forma asíncrona en entornos aislados; la CLI de Codex que se integra en tu flujo de trabajo de terminal; extensiones de IDE para VS Code y JetBrains; y GitHub Copilot donde el modelo Codex impulsa el asistente de codificación. Este enfoque orientado al producto significa que Codex sobresale en la ejecución completa de tareas (escribir una funcionalidad, corregir un error, crear un PR) en lugar de transmitir respuestas token por token. Si tu flujo de trabajo ya se centra en GitHub y quieres una IA que pueda completar pull requests de forma autónoma, Codex está diseñado específicamente para eso. Pero si necesitas incrustar llamadas de modelo en aplicaciones personalizadas con control granular por token, Codex no es la elección correcta.
La implicación práctica de estos diferentes patrones de acceso es significativa para las decisiones de arquitectura. Si estás construyendo un producto que necesita llamar modelos de IA de forma programática con control detallado sobre el uso de tokens, parámetros del modelo y streaming de respuestas, entonces Gemini 3.1 Pro y Claude Opus 4.6 son tus opciones. Si quieres una IA que opere más como un desarrollador junior que recibe descripciones de tareas y devuelve trabajo completado, Codex 5.3 está diseñado precisamente para ese caso de uso. Muchos equipos sofisticados usan ambos patrones: modelos basados en API para funciones orientadas al usuario en tiempo real y Codex para tareas de automatización en segundo plano como generación de tests y actualización de documentación.
Para equipos que necesitan flexibilidad en múltiples modelos, las plataformas de agregación de API pueden simplificar los flujos de trabajo multimodelo. Un servicio como laozhang.ai proporciona un endpoint de API unificado que soporta tanto modelos de Gemini como de Claude, permitiendo a los equipos enrutar solicitudes al modelo óptimo sin gestionar múltiples claves API y sistemas de facturación. Esto es particularmente valioso durante el período actual de lanzamientos rápidos de modelos, donde el modelo óptimo para un tipo de tarea dado puede cambiar de trimestre a trimestre, y quieres la flexibilidad de cambiar sin reescribir el código de integración.
Bajo el capó: por qué cada modelo sobresale donde lo hace

Comprender la arquitectura explica el "por qué" detrás de los números de benchmarks, y aquí es donde la mayoría de artículos comparativos se quedan cortos. Te dicen qué puntúa cada modelo pero no por qué obtiene esa puntuación. Las diferencias arquitectónicas entre estos tres modelos no son meras curiosidades académicas; predicen directamente qué cargas de trabajo manejará mejor cada modelo.
La arquitectura Mixture-of-Experts (MoE) de Gemini 3.1 Pro es la clave tanto de su superioridad en razonamiento como de su eficiencia de costos. En lugar de activar toda la red neuronal para cada consulta, MoE enruta selectivamente cada entrada a un número reducido de subredes "expertas" especializadas. Piénsalo como tener un equipo de especialistas donde solo los relevantes participan para cada tarea. Por esto Gemini puede mantener un conteo de parámetros totales masivo (habilitando un rendimiento fuerte en tareas diversas) mientras mantiene bajos los costos de inferencia (porque solo una fracción de los parámetros se activa por consulta). El diseño MoE beneficia particularmente al razonamiento científico y matemático porque el modelo puede enrutar consultas analíticas complejas a expertos específicamente entrenados en esos dominios. También explica por qué Gemini ofrece la ventana de contexto de producción más grande con 1 millón de tokens en Disponibilidad General: el enrutamiento eficiente de expertos hace que el procesamiento de contexto largo sea computacionalmente viable a escala.
La arquitectura de transformador denso con IA Constitucional de Claude Opus 4.6 representa una filosofía diferente. En lugar de enrutar a especialistas, cada parámetro participa en cada cómputo, lo que produce salidas más consistentes y matizadas a costa de un mayor gasto de inferencia. La innovación revolucionaria en Opus 4.6 es el bucle GVR (Generate-Verify-Reflect) para tareas de codificación: el modelo genera código, ejecuta verificaciones y luego reflexiona sobre los resultados antes de iterar, un proceso que refleja cómo trabajan los desarrolladores experimentados. Este bucle autocorrectivo es la razón por la que Opus lidera en SWE-Bench y produce menos errores en la práctica. La arquitectura Agent Teams extiende esto aún más permitiendo a Opus generar subagentes que trabajan en diferentes partes de un problema simultáneamente, algo que Anthropic reporta ha llevado a más de 500 descubrimientos de vulnerabilidades de día cero en proyectos principales de código abierto. La firma de comportamiento de Opus, confirmada por testimonios de desarrolladores de ingenieros de JetBrains y Databricks, es que hace preguntas aclaratorias antes de implementar, resultando en soluciones que coinciden más precisamente con la intención del desarrollador.
La variante optimizada de GPT-5 de GPT-5.3-Codex está diseñada específicamente para velocidad y ejecución autónoma. Dos innovaciones la definen: primero, el modo Spark que alcanza más de 1.000 tokens por segundo, haciéndolo aproximadamente un 25% más rápido que GPT-5.2 y sustancialmente más rápido que tanto Gemini como Opus en velocidad bruta de generación. Segundo, el modelo de ejecución aislada donde Codex opera en entornos cloud aislados con acceso completo a git, comandos de terminal y frameworks de testing. Por esto Codex domina Terminal-Bench: no solo genera código que debería funcionar, sino que realmente ejecuta el código, observa la salida, depura fallos e itera hasta que la tarea pasa todas las pruebas. El patrón de comportamiento aquí es el opuesto al de Opus: Codex implementa primero y hace preguntas después, prototipando soluciones rápidamente e iterando sobre fallos en lugar de planificar extensamente de antemano. Para una comparación más detallada de cómo GPT-5.3 Codex y Opus 4.6 se comparan en la práctica, exploramos escenarios de codificación específicos en nuestro artículo dedicado.
Las diferencias en metodología de entrenamiento son igualmente importantes. El enfoque de Google con Gemini involucra entrenar de forma nativa en múltiples modalidades de datos incluyendo texto, código, imágenes, audio y vídeo desde el inicio, en lugar de ajustar finamente un modelo de texto para manejar otras modalidades después. Este entrenamiento multimodal nativo es la razón por la que Gemini maneja entradas de modalidad mixta de forma más natural, como comprender una captura de pantalla de una interfaz junto con una descripción textual de los cambios deseados. El entrenamiento de Anthropic para Opus enfatiza la IA Constitucional, donde el modelo aprende a evaluar y mejorar sus propias salidas contra un conjunto de principios, creando el comportamiento cuidadoso y autocorrectivo que los desarrolladores notan en la práctica. El entrenamiento de OpenAI para Codex se centró específicamente en la ejecución de código y el uso de herramientas, con un amplio aprendizaje por refuerzo a partir de retroalimentación humana sobre la calidad de generación de código y la completación de tareas autónomas.
Estas diferencias arquitectónicas y de entrenamiento crean implicaciones claras para la selección de modelos. Si necesitas la mayor cantidad de tokens procesados por dólar con razonamiento sólido en todas las modalidades, Gemini basado en MoE es óptimo. Si necesitas la generación de código de mayor calidad con planificación cuidadosa y autocorrección, Opus basado en transformador denso es la elección. Si necesitas la completación de tareas autónomas más rápida con la capacidad de ejecutar, probar e iterar de forma independiente, el enfoque de ejecución primero de Codex gana.
¿Qué modelo deberías elegir? Marco de decisión para desarrolladores
En lugar de ofrecer una respuesta genérica de "depende", aquí hay un marco de decisión concreto basado en cinco perfiles de desarrollador que se mapean a escenarios comunes del mundo real. Identifica qué perfil coincide más con tu flujo de trabajo, y la recomendación de modelo se sigue naturalmente.
Perfil 1: El desarrollador full-stack independiente que construye un producto SaaS necesita un modelo que pueda manejar tareas diversas desde componentes frontend en React hasta diseño de API backend y consultas de base de datos, y el costo importa porque cada dólar proviene de ahorros personales o una pequeña ronda semilla. La recomendación aquí es Gemini 3.1 Pro como modelo principal. La amplitud de razonamiento de su arquitectura MoE maneja bien las tareas diversas de full-stack, la ventana de contexto de 1M permite cargar bases de código completas para contexto, y el precio de $2/MTok de entrada significa que la factura mensual se mantiene manejable. Usa Opus 4.6 selectivamente para decisiones arquitectónicas complejas o sesiones de depuración difíciles donde la calidad extra vale el premium.
Perfil 2: El ingeniero de infraestructura backend que trabaja en sistemas distribuidos, microservicios y pipelines de DevOps necesita precisión técnica profunda y análisis cuidadoso por encima de la velocidad. La recomendación es Claude Opus 4.6. El bucle GVR detecta errores sutiles de concurrencia y casos extremos que otros modelos pasan por alto, el patrón de comportamiento de "preguntar primero" es ideal para trabajo de infraestructura donde equivocarse puede causar interrupciones del servicio, y la función Agent Teams es transformadora para tareas de refactorización que tocan múltiples servicios simultáneamente. El premium de costo de 2,5 veces sobre Gemini se paga solo cuando un único error en producción le cuesta a tu empresa miles en respuesta a incidentes.
Perfil 3: El gerente de ingeniería que supervisa un equipo de más de 10 desarrolladores quiere una IA que pueda manejar de forma autónoma tareas rutinarias como revisiones de PR, correcciones de errores y generación de tests, liberando a los ingenieros humanos para trabajo creativo. La recomendación es GPT-5.3-Codex a través de GitHub Copilot o la CLI de Codex. El modelo de ejecución aislada significa que puedes asignar tareas y recibir PRs completados, la puntuación de 77,3% en Terminal-Bench refleja una capacidad real de completación de tareas autónomas, y el precio basado en producto es predecible independientemente del consumo de tokens. La limitación es que Codex es más fuerte dentro del ecosistema GitHub; si tu equipo usa GitLab o Bitbucket, la historia de integración es más débil.
Perfil 4: El investigador de IA o científico de datos que trabaja en problemas novedosos que requieren razonamiento científico, demostraciones matemáticas o análisis de grandes conjuntos de datos necesita las capacidades de razonamiento más fuertes independientemente de las funciones específicas de codificación. La recomendación es Gemini 3.1 Pro, de forma decisiva. La puntuación de 77,1% en ARC-AGI-2 (24 puntos por delante del competidor más cercano) y el rendimiento de 94,3% en GPQA Diamond lo convierten en la elección clara para trabajo de investigación. La ventana de contexto de 1M tokens en GA también es únicamente valiosa para analizar artículos extensos, conjuntos de datos o resultados experimentales en un solo prompt.
Perfil 5: El arquitecto empresarial que evalúa modelos para despliegue en toda la organización a través de equipos diversos necesita fiabilidad, seguridad y flexibilidad más que cualquier capacidad individual. La recomendación es una estrategia multimodelo. Usa Gemini 3.1 Pro como modelo predeterminado para consultas generales y eficiencia de costos, Opus 4.6 para codificación compleja y tareas sensibles a la seguridad donde su entrenamiento de IA Constitucional proporciona garantías adicionales de seguridad, y Codex 5.3 a través de GitHub Copilot para productividad de desarrolladores. Este enfoque también proporciona diversificación natural de proveedores, protegiendo contra interrupciones del servicio, cambios de precios o anuncios de deprecación de cualquier proveedor individual. Una empresa que ejecuta exclusivamente en un proveedor de modelos lleva un riesgo de concentración que es cada vez más injustificable dado lo fácil que se ha vuelto integrar múltiples modelos a través de patrones de API estandarizados. Este es el enfoque que exploramos con más profundidad en la siguiente sección.
Construyendo una estrategia multimodelo para producción
Los equipos de ingeniería más sofisticados en 2026 no están eligiendo un solo modelo. Están construyendo arquitecturas de enrutamiento que dirigen cada solicitud al modelo óptimo basándose en el tipo de tarea, el nivel de calidad requerido y las restricciones de costos. Este enfoque captura lo mejor de los tres modelos mientras gestiona los costos de forma inteligente.
El patrón central es un enrutador de modelos que clasifica las solicitudes entrantes y las enruta en consecuencia. A un nivel alto, la lógica de enrutamiento funciona así: las consultas intensivas en razonamiento (investigación, análisis, preguntas científicas) se enrutan a Gemini 3.1 Pro por su rendimiento superior en ARC-AGI-2 y GPQA Diamond al costo más bajo; las tareas de codificación complejas (refactorización, arquitectura, auditorías de seguridad) se enrutan a Opus 4.6 por su calidad líder en SWE-Bench y su bucle de autocorrección GVR; las tareas de ejecución autónoma (creación de PR, generación de tests, correcciones de errores rutinarias) se enrutan a Codex 5.3 a través de sus integraciones de producto por su capacidad dominante en Terminal-Bench.
La implementación práctica típicamente involucra tres capas. Primero, una capa de clasificación que determina el tipo de tarea a partir de la solicitud del usuario o el contexto de la aplicación. Segundo, una capa de enrutamiento que mapea tipos de tareas a modelos basándose en reglas configurables. Tercero, una capa de respaldo que maneja la indisponibilidad del modelo, límites de velocidad o errores inesperados enrutando a un modelo alternativo. Muchos equipos implementan esto a través de servicios de agregación de API que abstraen las APIs individuales de los modelos en un único endpoint, haciendo la lógica de enrutamiento más limpia y la facturación consolidada.
La optimización de costos en una configuración multimodelo va más allá de simplemente elegir el modelo más barato. El caché de contexto de Gemini puede reducir los costos hasta un 75% para prompts repetidos con prefijos compartidos. Anthropic ofrece descuentos del 50% en solicitudes de API por lotes para Opus, lo cual es ideal para pipelines de revisión de código fuera de línea. Y el precio basado en producto de Codex significa que su costo es fijo independientemente del volumen de uso, convirtiéndolo en la opción más predecible para presupuestar.
La métrica clave para evaluar una estrategia multimodelo no es el rendimiento de ningún modelo individual sino la calidad por dólar agregada en toda tu mezcla de solicitudes. Un enrutador bien ajustado puede alcanzar más del 90% de la calidad de usar siempre el mejor modelo para cada tipo de tarea mientras reduce los costos entre un 40% y un 60% en comparación con usar un único modelo premium para todo. La inversión en ingeniería para construir un enrutador se recupera rápidamente a escala: incluso un enrutador simple basado en reglas que envía consultas de razonamiento a Gemini y consultas de codificación a Opus puede reducir costos un 30% en comparación con usar Opus para todo, manteniendo calidad equivalente o mejor en las tareas de razonamiento.
Los equipos que no están listos para construir infraestructura de enrutamiento personalizada pueden lograr resultados similares a través de plataformas de agregación de API que manejan la selección de modelos y la lógica de respaldo. La idea clave es que el bloqueo de modelo es el mayor riesgo en el panorama actual. Con tres opciones sólidas de tres proveedores diferentes, mantener la flexibilidad para desplazar el tráfico entre modelos a medida que las capacidades evolucionan y los precios cambian es más valioso que exprimir el último punto porcentual de rendimiento de cualquier modelo individual.
Preguntas frecuentes
¿Cuál es el mejor modelo para codificación en marzo de 2026?
Depende de tu flujo de trabajo de codificación. Para revisión de código y refactorización compleja, Claude Opus 4.6 lidera con un 80,8% en SWE-Bench y su bucle de autocorrección GVR. Para ejecución autónoma de tareas donde el modelo escribe, prueba y hace commit del código de forma independiente, GPT-5.3-Codex domina con un 77,3% en Terminal-Bench. Para codificación general con sensibilidad al costo, Gemini 3.1 Pro con un 80,6% en SWE-Bench y $2/MTok de entrada ofrece la mejor relación calidad-precio. Los tres modelos están dentro de 1 punto porcentual en SWE-Bench, así que la diferencia práctica se reduce al tipo de asistencia de codificación que necesitas y tu flujo de trabajo preferido.
¿Opus 4.6 realmente cuesta $5/$25 por millón de tokens? Muchos artículos dicen $15/$75.
Sí, $5/$25 es correcto. Lo verificamos directamente en claude.com/pricing haciendo clic en la pestaña de API el 2 de marzo de 2026. El precio de $15/$75 citado por muchos artículos comparativos se refiere a la generación anterior de modelos Claude Opus 4.1 y 4.0. Anthropic redujo significativamente los precios de Opus con el lanzamiento 4.6, haciéndolo mucho más competitivo para uso en producción.
¿Puedo llamar a GPT-5.3-Codex vía API como GPT-4o o GPT-5.2?
No. A fecha del 2 de marzo de 2026, GPT-5.3-Codex no aparece en la página de precios de API de OpenAI y no existe un endpoint de modelo independiente. Accedes a él a través de la aplicación web Codex (codex.openai.com), la CLI de Codex, extensiones de IDE o GitHub Copilot. Si necesitas una API estándar con facturación por token de OpenAI, GPT-5.2 a $1,75/$14 por millón de tokens es la última opción, pero carece de las capacidades de ejecución autónoma que hacen especial a Codex.
¿Cuál modelo tiene la mayor ventana de contexto?
Gemini 3.1 Pro ofrece la mayor ventana de contexto con 1 millón de tokens en Disponibilidad General, lo que significa que es estable y lista para producción en esa longitud. Claude Opus 4.6 soporta 200K tokens por defecto con una beta de 1M tokens disponible bajo solicitud. GPT-5.3-Codex soporta 400K tokens. Si procesar documentos extremadamente largos es central para tu caso de uso, Gemini tiene una ventaja clara con su ventana de contexto de 1M en GA.
¿Cuál modelo es más seguro para uso empresarial?
Claude Opus 4.6 fue diseñado con IA Constitucional y entrenamiento de seguridad extensivo que lo hacen particularmente adecuado para entornos empresariales con requisitos estrictos de cumplimiento. Anthropic publica tarjetas de modelo detalladas y tiene un historial sólido en evaluaciones de seguridad. Gemini 3.1 Pro se integra con la infraestructura de seguridad empresarial existente de Google a través de Vertex AI, lo que significa que obtienes los mismos controles de acceso, registros de auditoría y certificaciones de cumplimiento en las que las empresas ya confían para sus cargas de trabajo en Google Cloud. Codex 5.3 opera en entornos aislados que limitan su capacidad de causar efectos secundarios no deseados, y su enfoque basado en producto significa que no puede acceder a sistemas más allá de lo que explícitamente le concedas. Los tres proveedores ofrecen acuerdos empresariales, cumplimiento SOC 2 y acuerdos de procesamiento de datos, por lo que la decisión de seguridad debería basarse en tu marco de cumplimiento específico en lugar de una recomendación genérica.
¿Cómo afectan los descuentos por procesamiento por lotes a la comparación de costos?
El procesamiento por lotes cambia significativamente las matemáticas de costos para usuarios de alto volumen. Anthropic ofrece un descuento del 50% en solicitudes de API por lotes de Opus 4.6, lo que reduce el precio efectivo de entrada a $2,50 por millón de tokens, casi igualando el precio estándar de Gemini de $2. Google ofrece caché de contexto para Gemini que puede reducir los costos hasta un 75% para prompts con prefijos compartidos, lo cual es extremadamente valioso para pipelines de revisión de código donde el prompt del sistema y el contexto del repositorio permanecen constantes a través de muchas solicitudes. El precio de Codex de OpenAI ya está incluido en las suscripciones de producto, así que no hay descuento adicional por lotes, pero el costo efectivo por token puede ser muy bajo para usuarios intensivos. La conclusión clave es que las tarifas publicadas por token son el punto de partida, no el costo final. Los equipos que procesan más de 100 millones de tokens al mes deberían negociar directamente con los proveedores y tener en cuenta el caché, los lotes y los descuentos por uso comprometido.
¿Estos modelos serán superados pronto? ¿Debería esperar?
El ritmo de lanzamientos de modelos a principios de 2026 ha sido extraordinario, y es natural preocuparse por construir sobre un modelo que podría quedar obsoleto en meses. Sin embargo, estos tres modelos representan avances arquitectónicos significativos (no solo incrementos de escala) sobre sus predecesores, sugiriendo que se mantendrán competitivos durante más tiempo que las generaciones típicas de modelos. La arquitectura MoE de Gemini, los Agent Teams de Opus y la ejecución aislada de Codex son todas capacidades novedosas en lugar de mejoras incrementales. El enfoque pragmático es construir tus aplicaciones con abstracción de modelo, de modo que cambiar de modelo requiera solo un cambio de configuración, y luego elegir el mejor modelo disponible hoy en lugar de esperar un lanzamiento futuro incierto. La estrategia multimodelo descrita en este artículo proporciona inherentemente esta flexibilidad.