
Respuesta corta, a fecha del 18 de marzo de 2026: un 429 RESOURCE_EXHAUSTED en Gemini API suele significar problema de cuota, nivel de facturación o ritmo de solicitudes, y en muchos casos debe tratarse con espera breve y reintento controlado; un 400 INVALID_ARGUMENT casi siempre significa que tu solicitud, la versión del endpoint, el modelo o la condición de facturación es incorrecta, así que lo normal es corregir antes de volver a llamar; un 500 INTERNAL suele apuntar a inestabilidad del lado de Google o a un contexto demasiado grande, por lo que la salida más rápida es recortar entrada, reintentar con backoff limitado y, si hace falta, pasar temporalmente de Pro a Flash.
El problema real no es "qué significa el código", sino "qué hago en el siguiente minuto". Esa es la parte que muchas páginas del SERP siguen explicando mal en 2026. El caso 429 ya no se limita a "enviaste demasiadas peticiones"; ahora hay que tener en cuenta el ajuste de cuotas del 7 de diciembre de 2025, los cambios de gasto y tier de marzo de 2026, y varios reportes de 429 en proyectos de pago con consumo muy bajo. El 400 tampoco es un bloque único: puede ser un JSON mal formado, una combinación modelo/endopoint no válida, o una FAILED_PRECONDITION porque tu región o tu plan no cumplen lo que exige Gemini. Y el 500 no siempre es una "caída misteriosa": la propia documentación oficial dice que un contexto demasiado largo también puede producirlo.
Resumen rápido
Si estás en modo incidente, empieza por esta tabla. Lo peor que puedes hacer es tratar 429, 400 y 500 como si fueran la misma clase de fallo.
| Error | Qué suele significar en 2026 | ¿Reintentar ahora? | Primera acción |
|---|---|---|---|
429 RESOURCE_EXHAUSTED | Límite real de RPM / TPM / RPD, propagación incompleta de facturación o desajuste de tier | Normalmente sí | Verifica el tier y los límites activos del proyecto, luego aplica backoff |
400 INVALID_ARGUMENT | Payload, parámetros, modelo o versión del endpoint incorrectos | Normalmente no | Revisa la forma de la solicitud y la compatibilidad |
400 FAILED_PRECONDITION | El proyecto no cumple una condición previa de región o facturación | No | Activa facturación o cambia a un uso soportado |
500 INTERNAL | Falla del lado de Google o contexto demasiado largo | Sí, con criterio | Reduce contexto, reintenta y prueba Flash si Pro falla |
Hay tres datos actuales que cambian el playbook de soporte. Primero, la FAQ de Firebase AI Logic ya indica que la cuota del Gemini Developer API para Free Tier y Paid Tier 1 se ajustó desde el 7 de diciembre de 2025, y que eso puede provocar 429 inesperados. Segundo, la documentación oficial de facturación de Gemini API dice que los fallos 400 y 500 no se facturan, pero sí consumen cuota. Tercero, Google introdujo más cambios en marzo de 2026 sobre spend caps y niveles de uso, y los tier spend caps empiezan a aplicarse el 1 de abril de 2026. Por eso una guía de errores escrita con lógica de 2025 se queda corta.
Diagnostica 429, 400 y 500 de Gemini API en 30 segundos
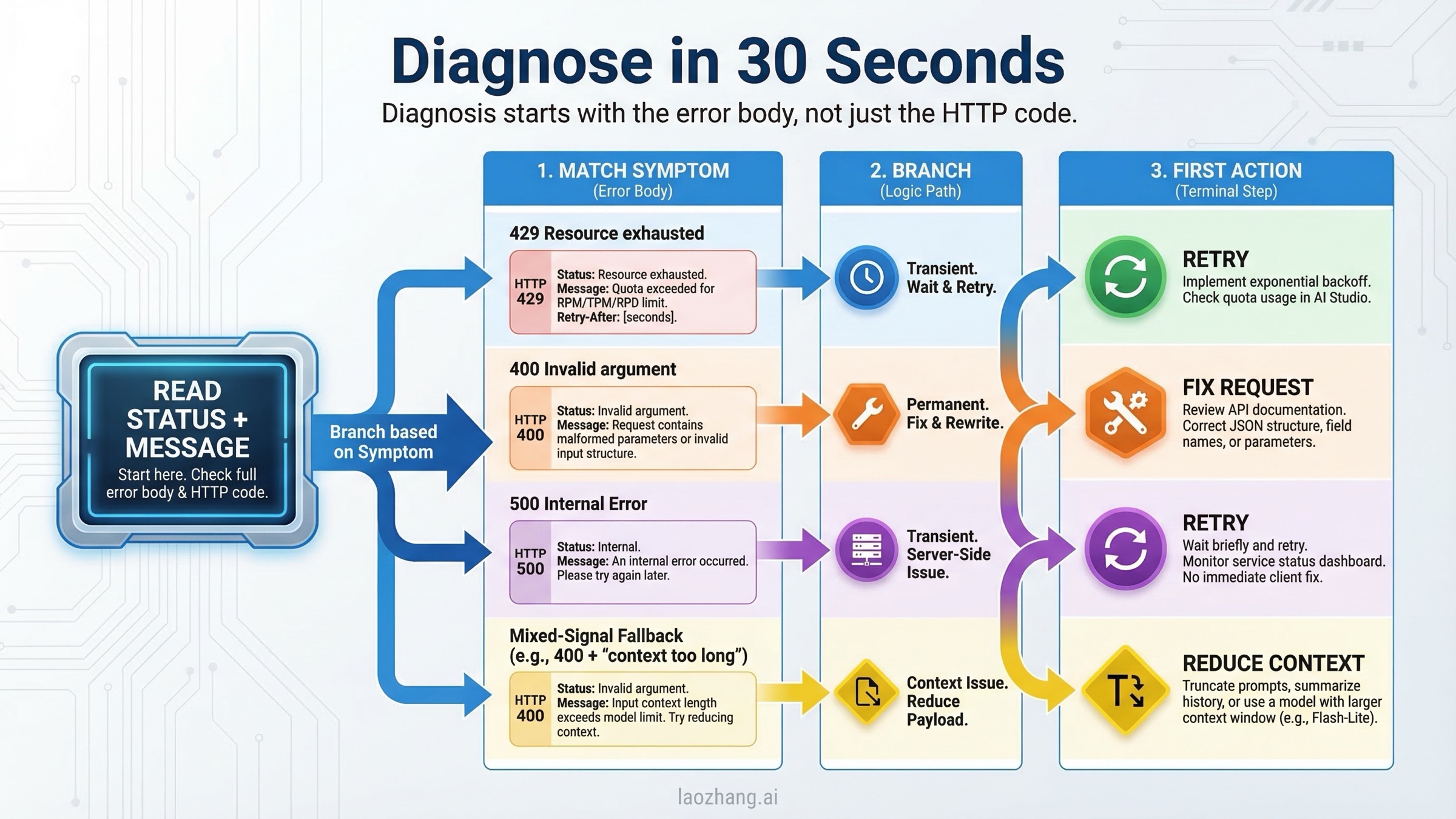
La mejor costumbre de depuración aquí es dejar de mirar solo el HTTP status y leer el cuerpo completo del error. Lo que realmente decide la acción es la combinación de status, message, detalles como QuotaFailure o RetryInfo, el modelo que usaste y si llamaste a /v1 o /v1beta.
La guía oficial de troubleshooting de Gemini sigue siendo el punto de partida más fiable, pero en producción conviene traducirla a una lógica operativa más simple. Un 429 significa que el backend cree que debes bajar ritmo o que tu estado de quota/tier no coincide con lo que esperabas. Un 400 INVALID_ARGUMENT significa que la solicitud fue rechazada como solicitud. Un 400 FAILED_PRECONDITION significa que quizás la forma del payload sea correcta, pero tu región o tu plan no cumplen una condición previa. Y un 500 significa que pasaste autenticación y validación, pero el fallo ocurrió en el procesamiento del lado de Google.
Usa el fragmento del mensaje para decidir:
| Fragmento o señal | Rama probable | Significado real | Siguiente paso |
|---|---|---|---|
RESOURCE_EXHAUSTED, quota, per minute, RetryInfo | 429 | Límite real o estado extraño de cuota/facturación | Backoff, luego verificación de tier y proyecto |
Request contains an invalid argument | 400 INVALID_ARGUMENT | Payload, endpoint o combinación de parámetros errónea | Deja de reintentar y revisa la solicitud |
free tier is not available in your country o mensaje claro de billing | 400 FAILED_PRECONDITION | Restricción regional o plan no habilitado | Activa facturación o cambia el camino de uso |
An internal error has occurred | 500 | Inestabilidad de Google o contexto excesivo | Reduce contexto, reintenta y prueba otro modelo |
Si quieres ahorrar horas, guarda al menos cuatro piezas de contexto en tus logs: el modelo, la versión del endpoint, el tamaño de la solicitud y si el mismo payload funciona en otro modelo de Gemini. Esos cuatro datos suelen separar un bug local de un incidente del servicio mucho más rápido que leer stack traces durante una hora.
Cómo corregir 429 RESOURCE_EXHAUSTED: cuota real, propagación de facturación y "ghost 429"

La explicación oficial de 429 es correcta pero incompleta: has excedido un límite. El problema es que en 2026 ese límite no siempre se manifiesta de forma obvia. La página oficial de rate limits recuerda dos puntos importantes. El primero es que tus límites activos se consultan en AI Studio y pueden cambiar con el tiempo. El segundo es que Google indica expresamente que los límites publicados no están garantizados como capacidad fija. Si tu diagnóstico parte de una tabla vieja que viste hace meses, es fácil sacar conclusiones equivocadas.
El gran cambio reciente fue el ajuste de cuotas del 7 de diciembre de 2025. La documentación de Firebase AI Logic no solo confirma la fecha, sino que también avisa de que ese cambio puede provocar 429 inesperados tanto en Free Tier como en Paid Tier 1. Esa línea explica por qué muchas aplicaciones empezaron a fallar sin que hubiera un cambio visible en el tráfico o en el código.
Otra regla que sigue confundiendo a muchísimos equipos es que los límites operan a nivel de proyecto y cuenta de facturación, no a nivel de API key individual. La documentación oficial de billing deja claro que la key hereda el estado del proyecto y de la billing account. Crear otra key dentro del mismo proyecto no crea otra cuota. Si el proyecto está limitado, mal asociado a facturación o con un tier mal propagado, la nueva key repetirá el problema.
En la práctica, conviene separar 429 en estas tres situaciones:
| Escenario 429 | Cómo suele verse | Mejor primera acción |
|---|---|---|
| Límite real | Picos de tráfico, mucha concurrencia o prompts grandes | Backoff, cola, menos concurrencia y menos tokens |
| Facturación recién activada | Acabas de pasar a Tier 1, pero el comportamiento parece seguir siendo free tier | Verifica el proyecto correcto y espera unos minutos |
| "Ghost 429" | El panel muestra poco uso, pero el 429 aparece casi enseguida | Comprueba proyecto, billing account y detalles de quota en el error |
Los hilos del Google AI Developers Forum añaden una matización importante. Varios usuarios de pago reportaron 429 persistentes con consumo muy bajo y, en algunos casos, el error hacía referencia a métricas que parecían de free tier. Eso no significa que todos los 429 sean un bug del proveedor, pero sí significa que no debes responder automáticamente "simplemente estás enviando demasiado". Si un proyecto de bajo tráfico y con billing activado empieza a devolver 429 casi desde la primera tanda de llamadas, es razonable comprobar si el problema es de sincronización de tier o de estado de cuota.
Cuando el 429 sí es un límite real, la solución sigue siendo poco glamourosa pero efectiva: reducir ráfagas, recortar contexto, agrupar pequeñas llamadas, añadir backoff con jitter y, si el volumen lo justifica, subir de nivel. La documentación oficial de rate limits indica además que el salto de Free a Tier 1 suele aplicarse inmediatamente, mientras que los upgrades posteriores suelen tardar unos 10 minutos. Si has esperado más que eso y el proyecto sigue comportándose como free tier, piensa antes en configuración o propagación que en un error de cálculo de tráfico.
Si el problema de fondo ya no es "esta llamada da 429", sino "la ruta oficial me interrumpe un flujo de producción", la conversación cambia. Para cargas de trabajo reales de API, no de pruebas puntuales, una capa de relay compatible con OpenAI como laozhang.ai puede tener sentido, pero solo cuando el problema ya es de estabilidad, routing o multi-proveedor, no cuando todavía estás corrigiendo un request mal formado.
Para ampliar el contexto, puedes revisar nuestra guía completa de errores Gemini API, la guía de nivel gratuito de Gemini API y la guía completa sobre el free tier de Gemini API.
Cómo corregir 400: separa INVALID_ARGUMENT de FAILED_PRECONDITION
El 400 es la familia de errores que más tiempo hace perder porque muchos equipos lo tratan como un bloque único. No lo es. La propia documentación oficial separa INVALID_ARGUMENT de FAILED_PRECONDITION, y esa distinción cambia completamente la acción correcta.
Empecemos por INVALID_ARGUMENT. Google dice que aparece cuando el cuerpo de la solicitud está mal formado, le falta un campo requerido o se usa una función de una versión más nueva en un endpoint más antiguo. Esta última parte es crítica. Tu JSON puede parecer impecable, pero si llamas a /v1 con una característica que solo existe en /v1beta, o si combinas parámetros con un modelo que no los soporta, el backend seguirá respondiendo con INVALID_ARGUMENT.
Las causas más comunes en integraciones reales de Gemini son bastante repetidas: nombre de modelo desactualizado o ya retirado, parámetros fuera del rango soportado, endpoint equivocado para la capacidad elegida, payload demasiado complejo o flujo de archivos mal resuelto. Por eso el orden correcto para arreglar 400 no es "probar una vez más". El orden correcto es: revisar el modelo, revisar el endpoint, revisar la estructura del payload y recién ahí volver a llamar.
| Tipo de 400 | Causa más común | Primer arreglo |
|---|---|---|
INVALID_ARGUMENT genérico | JSON o nesting incorrecto | Comparar con el ejemplo oficial más reciente |
INVALID_ARGUMENT tras activar una capacidad nueva | Endpoint o modelo no soportan esa función | Alinear /v1 o /v1beta con la capacidad real |
INVALID_ARGUMENT con archivos o payload grande | Flujo de carga o forma del request no válida | Mover el archivo al flujo correcto y reducir complejidad |
FAILED_PRECONDITION | Región o facturación no cumplen el requisito | Activar billing o cambiar la ruta de uso |
FAILED_PRECONDITION merece una lectura aparte porque no es un problema de "sintaxis". Google indica expresamente que puede aparecer cuando la free tier no está disponible en tu país y no tienes facturación habilitada. Si sigues tocando campos del JSON en ese escenario, estás intentando arreglar la capa equivocada. El formato no es el problema; la condición previa es el problema.
También conviene mantener un poco de criterio antes de culparte al cien por cien por cualquier 400. Existen reportes comunitarios donde flujos que llevaban semanas funcionando empezaron a devolver 400 INVALID_ARGUMENT sin cambios de código y luego se recuperaron. La lectura correcta no es "400 ahora también es reintentable", sino "si el payload no cambió y solo un modelo empieza a fallar, conviene validar la solicitud, probar con un modelo hermano y luego decidir si el problema es tuyo o del servicio".
Cómo corregir 500 INTERNAL: contexto largo, inestabilidad del modelo y reintentos seguros
Google no es ambiguo en este punto: un 500 INTERNAL puede ser un fallo inesperado del lado de Google, pero también puede aparecer cuando el contexto de entrada es demasiado largo. La recomendación oficial es reducir el contexto o cambiar temporalmente a otro modelo, por ejemplo de Gemini 2.5 Pro a Gemini 2.5 Flash.
Esa recomendación encaja con la ficha oficial de modelos. Gemini 2.5 Pro tiene un límite de entrada de 1.048.576 tokens, lo cual es una fortaleza para trabajo complejo con código, documentos y datasets, pero también lleva a muchos desarrolladores a suponer que "si cabe en teoría, debería ir perfecto". En la práctica no funciona así. Cuando mezclas contextos largos, muchos archivos, instrucciones repetidas y prompts grandes, el 500 deja de ser sorprendente.
Por eso la primera regla para 500 es muy simple: antes de analizar más, recorta entrada. Elimina instrucciones duplicadas, reduce historial, acota chunks de recuperación y deja fuera lo que no sea esencial. Muchas veces no necesitas rehacer el sistema; necesitas dejar de enviar contexto inflado.
La segunda cara del 500 es la inestabilidad del propio modelo. Hay reportes en el foro de Google AI Developers donde Gemini 2.5 Pro devolvía 500 de forma amplia mientras Flash seguía funcionando. Ahí el test más útil no es "revisar otro archivo de configuración", sino lanzar el mismo payload sobre Flash. Si Flash responde y Pro no, la salida más rápida suele ser degradar temporalmente el modelo y recuperar servicio.
Yo usaría este orden:
- Ver si la solicitud que falla es especialmente grande o lenta.
- Aplicar backoff con jitter.
- Si estabas en Pro, probar el mismo payload en Flash.
- Si el error persiste incluso con input más pequeño y ocurre en varios casos, tratarlo como incidente del proveedor y dejar de perseguir fantasmas locales.
Para un caso específico de sobrecarga del lado del servicio, puedes ver nuestra guía sobre Gemini 3 Pro Image 503 overloaded si todavía no existe una versión localizada para tu flujo.
Troubleshooting para fallos repetidos en Gemini API
Cuando el mismo tipo de error vuelve una y otra vez, deja de depurarlo llamada por llamada y conviértelo en un proceso. Esa es la diferencia entre un equipo que reacciona y un equipo que aprende.
Empieza por congelar un payload que falla y, si puedes, otro que funciona. Compáralos por modelo, endpoint, tamaño del contexto, parámetros y presencia de archivos. Si la diferencia es principalmente de volumen o concurrencia, piensa en 429. Si la diferencia es de forma, piensa en 400. Si el mismo payload falla en un modelo y funciona en otro, piensa en estado del modelo o incidente antes que en JSON roto.
La pregunta clave es esta: ¿el tiempo ayuda? En 429 y en bastantes 500, sí. En un 400 determinista, normalmente no. Si ya reintentaste varias veces un INVALID_ARGUMENT idéntico, ya no estás "siendo persistente": estás consumiendo cuota para nada.
| Paso | Qué verificar | Para qué sirve |
|---|---|---|
| 1 | Error completo y modelo | Evita depurar como bug local un problema del proveedor |
| 2 | /v1 o /v1beta | Descubre rápido muchos 400 por versión |
| 3 | Tamaño del prompt y archivos | Aclara muchos 500 y algunos 400 |
| 4 | Proyecto y billing account | Aclara una gran parte de los 429 confusos |
| 5 | Mismo payload en otro modelo | Separa fallo de request de fallo del modelo |
Si esto corre en producción, añade otra disciplina: nunca guardes solo "la API devolvió error". Guarda también modelo, versión del endpoint, tamaño aproximado y categoría normalizada del fallo. A medio plazo, eso te ahorra mucho más tiempo que memorizar listas de códigos.
Plantilla de reintentos para producción: qué reintentar y qué fallar rápido
Lo importante de la lógica de retry no es la fórmula exacta de espera, sino la frontera entre errores reintentables y errores que deben fallar de inmediato. En Gemini la regla práctica es clara: reintenta 429, 500, 503 y 504 con backoff limitado; no reintentes 400, 401, 403 y 404 salvo que hayas cambiado algo real entre intentos.
Python
pythonimport random import time from google import genai from google.genai import errors client = genai.Client(api_key="YOUR_GEMINI_API_KEY") RETRYABLE = {429, 500, 503, 504} FAIL_FAST = {400, 401, 403, 404} def generate_with_retry(model: str, contents, max_retries: int = 5): for attempt in range(max_retries): try: return client.models.generate_content(model=model, contents=contents) except errors.ClientError as exc: status = getattr(exc, "code", None) message = str(exc) if status in FAIL_FAST: raise RuntimeError( f"Non-retryable Gemini error {status}: {message}" ) from exc if status in RETRYABLE and attempt < max_retries - 1: delay = min(2 ** attempt, 30) jitter = random.uniform(0, delay * 0.2) time.sleep(delay + jitter) continue raise RuntimeError( f"Retry budget exhausted after Gemini error {status}: {message}" ) from exc
Node.js
tsimport { GoogleGenAI } from "@google/genai"; const client = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY! }); const retryable = new Set([429, 500, 503, 504]); const failFast = new Set([400, 401, 403, 404]); export async function generateWithRetry(model: string, contents: string) { for (let attempt = 0; attempt < 5; attempt += 1) { try { return await client.models.generateContent({ model, contents }); } catch (error: any) { const status = error?.status ?? error?.code ?? 0; if (failFast.has(status)) { throw new Error(`Non-retryable Gemini error ${status}: ${error.message}`); } if (retryable.has(status) && attempt < 4) { const delayMs = Math.min(1000 * 2 ** attempt, 30000); const jitterMs = Math.random() * delayMs * 0.2; await new Promise((resolve) => setTimeout(resolve, delayMs + jitterMs)); continue; } throw error; } } }
La parte crítica de este código no es el número exacto de segundos. La parte crítica es la decisión. Si sigues reintentando INVALID_ARGUMENT, conviertes un error determinista en cinco errores inútiles. Si nunca reintentas 429 o 500, abandonas llamadas que muchas veces habrían funcionado con unos segundos de espera.
Los cambios de 2026 que dejan obsoletas muchas guías antiguas
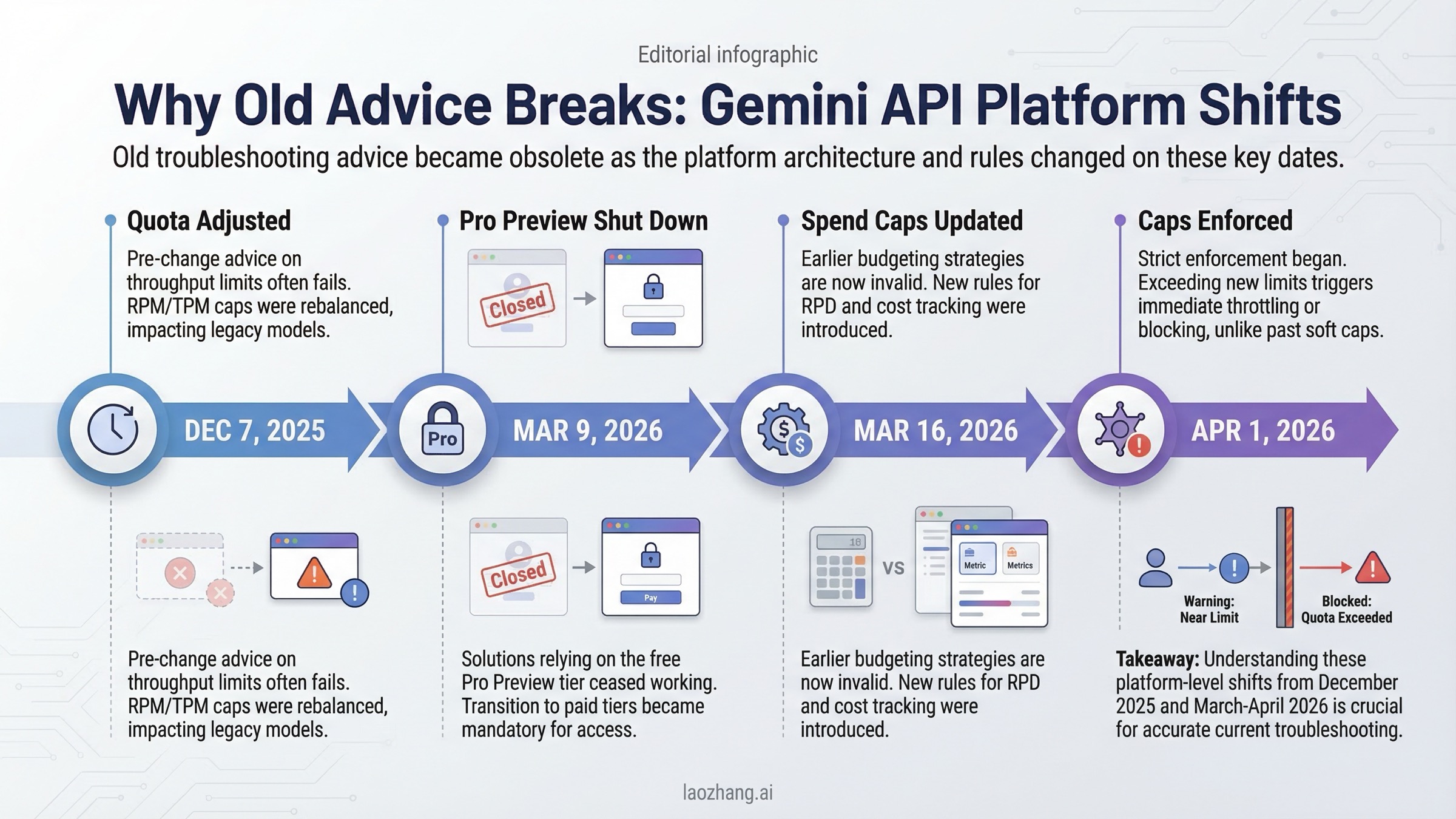
Gran parte de las guías antiguas asumen que la plataforma es estable en el tiempo. Ya no lo es. Estos hitos cambian de verdad cómo debes leer los errores actuales:
| Fecha | Cambio | Impacto en troubleshooting |
|---|---|---|
| 2025-12-07 | Ajuste de cuota para Free Tier y Paid Tier 1 | Explica aumentos de 429 sin cambios grandes en la app |
| 2026-03-09 | Cierre de Gemini 3 Pro Preview | Nombres y aliases viejos pasan a romper requests |
| 2026-03-12 | Spend caps por proyecto en AI Studio | La capa de presupuesto entra en la depuración |
| 2026-03-16 | Cambios en tiers y spend caps de cuenta | Supuestos viejos sobre cuota dejan de servir |
| 2026-04-01 | Comienza la aplicación real de tier spend caps | La suspensión por tope puede parecer una caída aleatoria |
Ese es el motivo por el que tantas páginas del SERP no son del todo inútiles, pero sí insuficientes: su lógica no está anclada a fechas concretas.
FAQ
¿Se facturan las solicitudes fallidas?
En general no, si fallan con 400 o 500. La documentación oficial de billing dice que no se cobran esos tokens, pero la llamada sí cuenta contra la cuota.
¿Los límites de Gemini se aplican por API key o por proyecto?
Debes pensar en proyecto y billing account, no en clave individual. La key hereda el estado del proyecto; crear otra dentro del mismo proyecto no multiplica la cuota.
¿Cuánto tarda en activarse la facturación?
Google indica que el paso de Free a Tier 1 suele ser inmediato y que los upgrades posteriores suelen aplicarse dentro de unos 10 minutos. Si has esperado más y sigues viendo comportamiento de free tier, revisa el proyecto y la cuenta de facturación usados por esa key.
¿Cuándo conviene cambiar de Gemini 2.5 Pro a Gemini 2.5 Flash?
Cuando el mismo payload funciona en Flash y falla en Pro, cuando el 500 coincide con contextos enormes, o cuando necesitas recuperar servicio antes que mantener el máximo nivel de razonamiento.
¿Existe una sola página oficial que resuelva todos los errores de Gemini?
No. La guía oficial de troubleshooting es el mejor punto de partida, pero para 2026 hay que combinarla con las páginas de rate limits, billing, pricing y release notes. Si quieres una referencia más amplia, revisa nuestra guía completa de errores Gemini API.