La API de Gemini de Google sigue siendo una de las ofertas gratuitas de API de inteligencia artificial más generosas en 2026, proporcionando a los desarrolladores acceso a modelos de frontera como Gemini 2.5 Pro con una ventana de contexto de 1 millón de tokens sin absolutamente ningún costo. Tras las reducciones de cuota de diciembre de 2025 que tomaron por sorpresa a miles de desarrolladores, comprender exactamente qué obtienes gratis y cuándo tiene sentido pagar se ha convertido en un conocimiento esencial para cualquier desarrollador que construya con IA. Esta guía proporciona datos verificados por Chrome desde la documentación oficial de Google, cálculos prácticos de costos y un marco de decisión que puedes aplicar a tu situación específica hoy mismo.
Resumen rápido
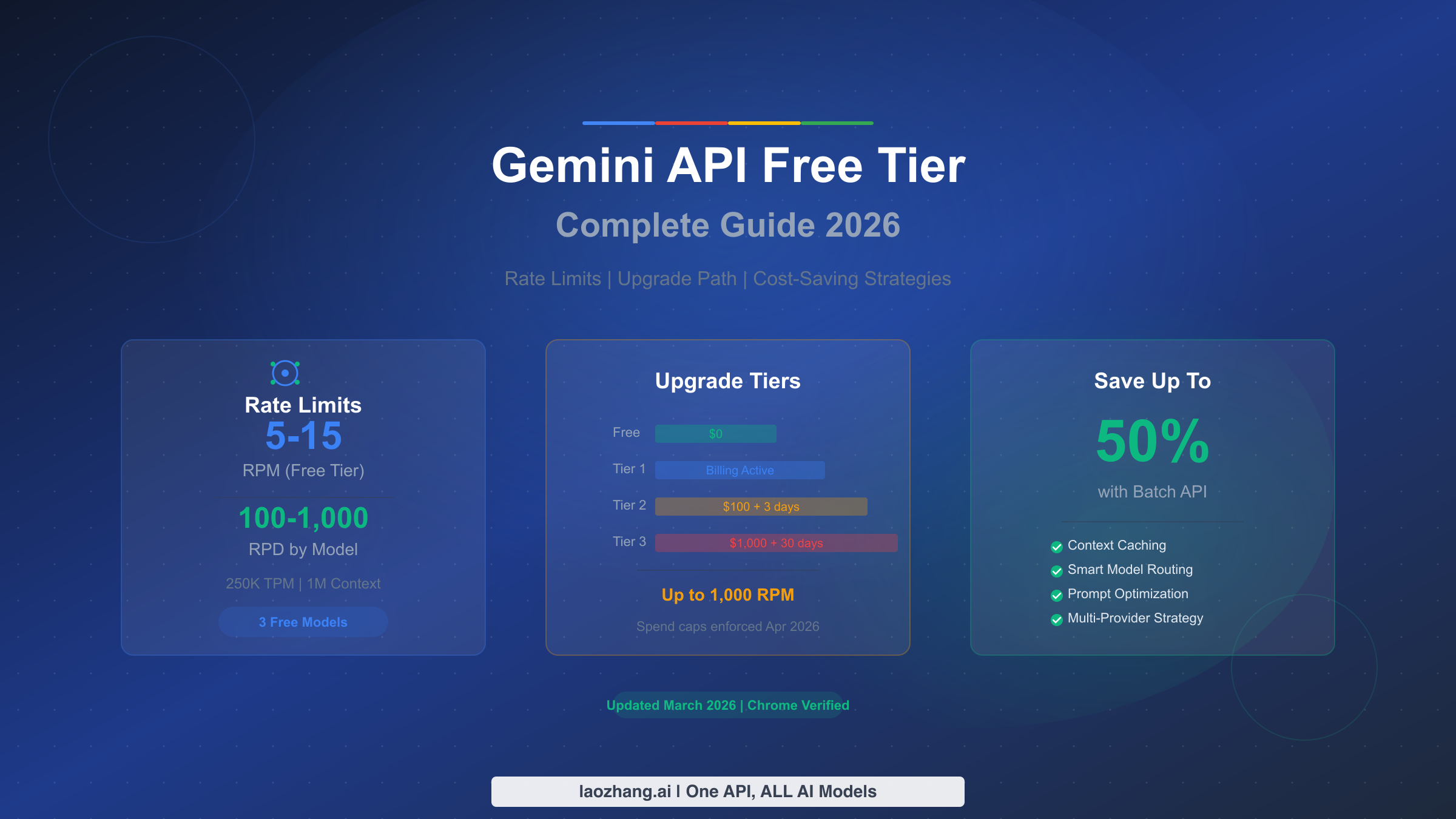
El nivel gratuito de Gemini API actualmente ofrece tres modelos estables con límites de velocidad que van desde 5 hasta 15 solicitudes por minuto, dependiendo del modelo que elijas. Aquí tienes el desglose esencial que todo desarrollador necesita conocer antes de escribir una sola línea de código.
Los tres modelos disponibles en el nivel gratuito a marzo de 2026 son Gemini 2.5 Pro con 5 RPM y 100 solicitudes por día, Gemini 2.5 Flash con 10 RPM y 250 solicitudes diarias, y Gemini 2.5 Flash-Lite que lidera con 15 RPM y 1,000 solicitudes diarias. Los tres modelos comparten un límite de 250,000 tokens por minuto y acceso completo a la ventana de contexto de 1 millón de tokens. Dos modelos adicionales en versión preliminar, Gemini 3 Flash y Gemini 3.1 Flash-Lite, también están disponibles de forma gratuita con límites más restrictivos. No se requiere tarjeta de crédito para comenzar, pero ten en cuenta que tus prompts y respuestas en el nivel gratuito pueden utilizarse para mejorar los productos de Google. Actualizar al Nivel 1 no cuesta nada por adelantado ya que solo pagas por lo que usas, y elimina inmediatamente la preocupación por el uso compartido de datos mientras aumenta tus límites de velocidad a 150-300 RPM.
Límites completos del nivel gratuito: cada modelo, cada número

Comprender los límites de velocidad es la base para trabajar eficazmente con la API de Gemini, y los números han cambiado significativamente desde finales de 2025. Google mide los límites de velocidad en tres dimensiones: solicitudes por minuto (RPM), tokens por minuto (TPM) y solicitudes por día (RPD). Tu uso se evalúa simultáneamente contra las tres métricas, y exceder cualquier límite individual provoca un error 429, incluso si estás muy por debajo de los otros dos límites. Estos límites se aplican por proyecto de Google Cloud en lugar de por clave API individual, y las cuotas diarias se reinician a medianoche hora del Pacífico.
La siguiente tabla presenta los límites de velocidad completos, verificados mediante Chrome, para cada modelo disponible en el nivel gratuito a marzo de 2026. Estos números fueron extraídos directamente de la documentación oficial de límites de velocidad de Google en ai.google.dev el día de publicación de este artículo.
| Modelo | RPM | RPD | TPM | Ventana de contexto | Estado |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 | 1M tokens | Estable |
| Gemini 2.5 Flash | 10 | 250 | 250,000 | 1M tokens | Estable |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 | 1M tokens | Estable |
| Gemini 3 Flash Preview | Limitado | Limitado | Limitado | 1M tokens | Preliminar |
| Gemini 3.1 Flash-Lite Preview | Limitado | Limitado | Limitado | 1M tokens | Preliminar |
Más allá de estos modelos de generación de texto, Google también proporciona acceso gratuito a modelos de embeddings. El modelo Gemini Embedding soporta 10 millones de tokens por minuto en el nivel gratuito, lo cual es notablemente generoso para construir sistemas de búsqueda y recuperación. El más reciente Gemini Embedding 2 Preview añade capacidades de embedding multimodal, soportando entradas de texto, imagen, audio y vídeo, todo sin costo alguno.
Vale la pena señalar que los límites de velocidad indicados representan el techo oficial, pero la capacidad real disponible puede variar. Múltiples desarrolladores en Reddit han reportado alcanzar los límites de velocidad muy por debajo de los números oficiales, particularmente durante horas pico. El subreddit r/GeminiAI documentó casos donde Gemini 2.5 Flash efectivamente entregó tan solo 20 solicitudes por día durante períodos de alto tráfico, a pesar del límite oficial de 250 RPD. La documentación de Google reconoce esto con la advertencia de que los límites de velocidad especificados no están garantizados y la capacidad real puede variar.
Comprender las limitaciones de los modelos preliminares
Los modelos preliminares como Gemini 3 Flash y Gemini 3.1 Flash-Lite tienen restricciones adicionales más allá de los límites de velocidad estándar. Estos modelos tienen cuotas más restrictivas que Google ajusta frecuentemente a medida que los modelos avanzan en su desarrollo. También carecen de funciones disponibles en los modelos estables, como el almacenamiento en caché de contexto y el soporte de API por lotes. Para cargas de trabajo en producción, la serie estable 2.5 sigue siendo la opción recomendada, mientras que los modelos preliminares se utilizan mejor para evaluación y experimentación.
Cómo obtener tu clave API gratuita en 5 minutos
Configurar el acceso al nivel gratuito de la API de Gemini es sencillo y no requiere información de pago. Todo el proceso toma aproximadamente cinco minutos e involucra solo tres pasos. Primero, visita Google AI Studio en aistudio.google.com e inicia sesión con tu cuenta de Google. Si aún no tienes una cuenta de Google, necesitarás crear una, lo que añade aproximadamente dos minutos al proceso.
Una vez que hayas iniciado sesión, navega a la sección de claves API, que puedes encontrar en la barra lateral izquierda o en aistudio.google.com/api-keys. Haz clic en el botón "Create API Key". Google creará automáticamente un nuevo proyecto de Google Cloud o te permitirá seleccionar uno existente. Tu clave API se generará instantáneamente, y podrás comenzar a hacer llamadas a la API inmediatamente con los límites del nivel gratuito aplicados.
Puedes probar tu clave con un simple comando curl de la siguiente manera:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{"contents":[{"parts":[{"text":"Explain rate limits in one sentence"}]}]}'
Algunos detalles importantes sobre la gestión de claves API merecen atención. Cada proyecto de Google Cloud puede tener hasta cinco claves API, y una sola cuenta de facturación puede soportar hasta diez proyectos. Esto significa que teóricamente podrías gestionar hasta 50 claves API bajo una sola estructura de facturación, aunque los límites de velocidad se aplican a nivel de proyecto, no a nivel de clave. Crear múltiples claves dentro del mismo proyecto no multiplica tu cuota. Si necesitas un mayor rendimiento total en el nivel gratuito, necesitarías proyectos separados, pero ten en cuenta que Google monitorea el abuso de este enfoque. Para un recorrido detallado del proceso de generación de claves, incluyendo la solución de problemas comunes, consulta nuestra guía completa de claves API de Gemini.
Qué cambió realmente en diciembre de 2025
El fin de semana del 6 al 7 de diciembre de 2025 marcó un momento decisivo para el nivel gratuito de la API de Gemini. Sin aviso previo, Google redujo significativamente los límites de velocidad en todos los modelos del nivel gratuito, causando errores generalizados 429 "resource exhausted" que rompieron los flujos de trabajo de producción de miles de desarrolladores de la noche a la mañana. La respuesta de la comunidad en Reddit y Hacker News fue inmediata e intensa, con el hilo de r/GeminiAI sobre el tema acumulando más de 210 comentarios de desarrolladores frustrados.
Logan Kilpatrick, Director de Producto de Google para AI Studio, proporcionó contexto sobre la decisión. Explicó que los generosos límites del nivel gratuito habían sido "originalmente solo pensados para estar disponibles durante un solo fin de semana" pero "inadvertidamente permanecieron durante varios meses". Google citó "fraude y abuso a gran escala" como el principal motivo detrás de los recortes más amplios. Las reducciones no fueron uniformes en todos los modelos. Algunos modelos vieron sus límites recortados en un 50 por ciento mientras que otros experimentaron reducciones de hasta el 80 por ciento, con el impacto exacto dependiendo del modelo específico y el tipo de solicitud.
El impacto práctico fue significativo. Los desarrolladores que habían construido aplicaciones dependiendo de los límites anteriores de repente encontraron sus sistemas fallando. Los chatbots dejaron de responder, las canalizaciones de procesamiento por lotes se detuvieron y los flujos de trabajo automatizados se paralizaron. La situación se agravó por el hecho de que Google no proporcionó ningún período de migración ni aviso previo, dejando a los desarrolladores luchando por optimizar su uso o actualizar a niveles de pago durante un fin de semana.
Desde diciembre de 2025, la situación se ha estabilizado en los límites de velocidad actuales documentados en esta guía. Google también dejó de ofrecer Gemini 2.0 Flash en febrero de 2026, con el modelo retirándose oficialmente el 3 de marzo de 2026. Esto significa que los desarrolladores que usaban 2.0 Flash como opción gratuita de alto rendimiento necesitan migrar a los modelos 2.5 Flash o Flash-Lite. La lección de este episodio es clara: construir sistemas de producción enteramente sobre cuotas del nivel gratuito conlleva un riesgo inherente, independientemente de lo generosas que esas cuotas parezcan en un momento dado. Si encontraste errores 429 durante esta transición, nuestra guía detallada de solución de errores cubre las estrategias de recuperación.
Gemini vs OpenAI vs Claude: comparación del nivel gratuito

Ninguna discusión sobre el nivel gratuito de Gemini está completa sin comprender cómo se compara con la competencia. Esta comparación revela por qué Gemini sigue siendo la opción gratuita más sólida para la mayoría de los desarrolladores en 2026, a pesar de los recortes de diciembre de 2025. Los tres principales proveedores de API de IA adoptan enfoques fundamentalmente diferentes para el acceso gratuito, y comprender estas diferencias puede ahorrarte dinero significativo y tiempo de desarrollo.
La API de Gemini de Google se distingue por ofrecer un nivel verdaderamente gratuito que no requiere tarjeta de crédito ni ningún pago inicial de ningún tipo. Te registras con una cuenta de Google y comienzas a hacer llamadas a la API inmediatamente. OpenAI y Anthropic, por el contrario, ambos requieren registro con tarjeta de crédito y ofrecen créditos iniciales que expiran. OpenAI proporciona un crédito de $5 que expira después de tres meses, mientras que la API de Claude de Anthropic ofrece un crédito similar de $5 con una ventana de expiración de 30 días. Una vez que estos créditos se agotan, pasas inmediatamente a un plan de pago.
| Característica | Gemini (Gratis) | OpenAI (Crédito $5) | Claude (Crédito $5) |
|---|---|---|---|
| Tarjeta de crédito requerida | No | Sí | Sí |
| RPM | 5-15 | 500 (Nivel 1) | 50 (Nivel 1) |
| RPD | 100-1,000 | 10,000 | 1,000 |
| TPM | 250,000 | 200,000 | 40,000 |
| Ventana de contexto | 1M tokens | 128K (GPT-4o) | 200K (Claude) |
| Modelos gratuitos | 5 (3 estables + 2 preliminares) | GPT-4o, GPT-4o mini | Sonnet, Haiku |
| Duración | Ilimitada | 3 meses | 30 días |
| Privacidad de datos | Usados para entrenamiento | No se usan | No se usan |
| Grounding/Búsqueda | Gratis (500 RPD) | No disponible gratis | No disponible |
La ventaja de la ventana de contexto es el diferenciador más destacado de Gemini. Con 1 millón de tokens de contexto en el nivel gratuito, puedes procesar bases de código completas, documentos extensos u horas de historial de conversación en una sola solicitud. GPT-4o de OpenAI tiene un máximo de 128K tokens, e incluso la generosa ventana de contexto de 200K de Claude representa solo una quinta parte de lo que Gemini ofrece gratis.
Sin embargo, el nivel gratuito de Gemini viene con una contrapartida significativa que los desarrolladores deben considerar cuidadosamente: la privacidad de datos. En el nivel gratuito, tus prompts y respuestas pueden utilizarse para mejorar los productos de Google. Esto hace que el nivel gratuito sea inapropiado para aplicaciones que manejan datos sensibles de usuarios, información empresarial propietaria o cualquier contenido sujeto a regulaciones de privacidad. OpenAI y Claude no utilizan datos de la API para entrenamiento independientemente del nivel. Si la privacidad de datos es un requisito, actualizar al Nivel 1 de pago de Gemini elimina el uso compartido de datos mientras sigue ofreciendo precios competitivos. Para un análisis más profundo de cómo se comparan Gemini y OpenAI en precios en todos los niveles, consulta nuestra guía detallada de comparación de precios.
Para los desarrolladores que necesitan acceder a múltiples proveedores de IA sin gestionar claves API y cuentas de facturación separadas, plataformas de API unificadas como laozhang.ai proporcionan un único punto de acceso para Gemini, OpenAI, Claude y docenas de otros modelos, simplificando arquitecturas multiproveedor mientras a menudo ofrecen ventajas de costos a través de la agregación por volumen.
Desglose real de costos: lo que realmente pagarás al actualizar
Comprender el costo real de actualizar más allá del nivel gratuito requiere traducir los precios basados en tokens a escenarios de uso del mundo real. La página de precios muestra números como "$0.30 por millón de tokens de entrada" para Gemini 2.5 Flash, pero ¿qué significa eso para tu factura mensual? Calculemos los costos para tres casos de uso comunes utilizando precios verificados de ai.google.dev a marzo de 2026 (fuente: precios de Gemini API).
Escenario 1: Chatbot de atención al cliente (pequeña empresa)
Un chatbot que maneja 200 conversaciones por día, cada una con un promedio de 3 intercambios con 500 tokens de entrada y 300 tokens de salida por intercambio. Uso mensual: 200 conversaciones x 30 días x 3 intercambios = 18,000 solicitudes. Tokens de entrada: 18,000 x 500 = 9M tokens. Tokens de salida: 18,000 x 300 = 5.4M tokens. Usando Gemini 2.5 Flash a $0.30/$2.50 por millón de tokens: costo de entrada es $2.70, costo de salida es $13.50, totalizando aproximadamente $16.20 por mes. La misma carga de trabajo en GPT-4o de OpenAI a $2.50/$10.00 por millón de tokens costaría $22.50 de entrada más $54.00 de salida, totalizando $76.50 por mes. Eso representa un ahorro del 79% con Gemini.
Escenario 2: Búsqueda de documentos basada en RAG (startup)
Un sistema de generación aumentada por recuperación que procesa 500 consultas por día, cada una con un contexto de 10,000 tokens de documentos recuperados y una respuesta de 1,000 tokens. Uso mensual: 500 x 30 = 15,000 solicitudes. Entrada: 150M tokens. Salida: 15M tokens. Costo con Gemini 2.5 Flash: $45.00 de entrada + $37.50 de salida = $82.50 por mes. Con la API por lotes (50% de descuento en solicitudes elegibles): aproximadamente $41.25 por mes si las consultas se pueden agrupar. La misma carga de trabajo en GPT-4o: $375 de entrada + $150 de salida = $525 por mes. Gemini te ahorra $442.50 mensuales, o un 84%.
Escenario 3: Procesamiento de contenido de alto volumen (empresa)
Procesando 2,000 documentos por día, con un promedio de 50,000 tokens de entrada y 2,000 tokens de salida cada uno. Uso mensual: 60,000 solicitudes. Entrada: 3B tokens. Salida: 120M tokens. Aquí, Gemini 2.5 Flash-Lite a $0.10/$0.40 por millón de tokens se convierte en la opción inteligente: $300 de entrada + $48 de salida = $348 por mes. Con la API por lotes: aproximadamente $174 por mes. Compara con GPT-4o mini a $0.15/$0.60: $450 + $72 = $522 por mes. La diferencia crece aún más en el nivel 2.5 Pro, donde el almacenamiento en caché de contexto puede reducir los costos de entrada repetidos hasta en un 75 por ciento. Para precios completos de todos los modelos y niveles, nuestra guía de precios y cuotas de Gemini API proporciona tablas exhaustivas.
| Escenario | Gemini 2.5 Flash | GPT-4o | Ahorro |
|---|---|---|---|
| Chatbot (200/día) | $16.20/mes | $76.50/mes | 79% |
| Búsqueda RAG (500/día) | $82.50/mes | $525/mes | 84% |
| Procesamiento de contenido (2K/día) | $348/mes* | $522/mes** | 33% |
*Usando Flash-Lite con la API por lotes se reduce a ~$174/mes. **Usando GPT-4o mini.
Cuándo actualizar: el marco de decisión
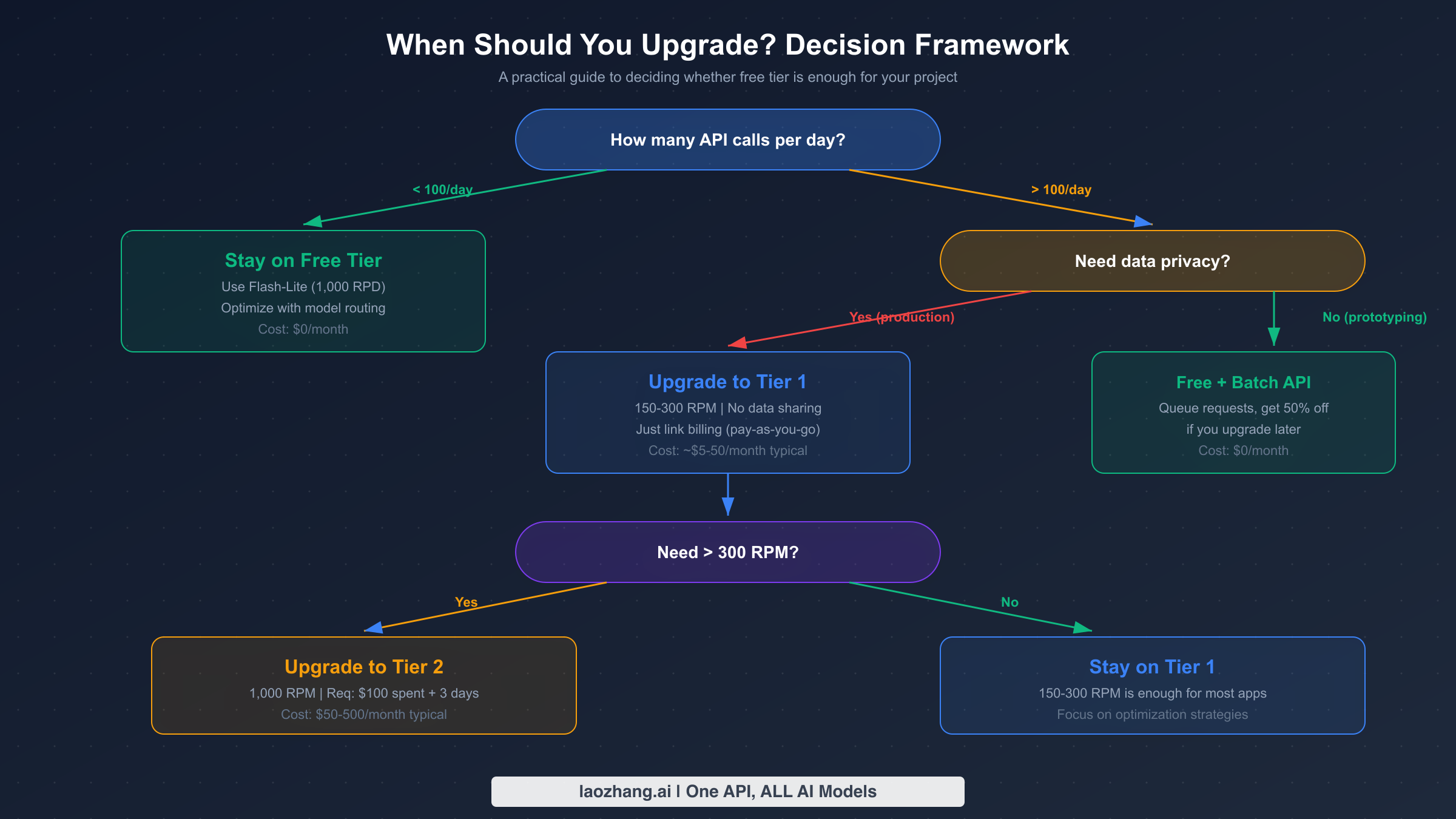
La decisión de actualizar desde el nivel gratuito debe basarse en métricas de uso concretas en lugar de especulaciones. Google ofrece cuatro niveles, cada uno con límites de velocidad, precios y requisitos de calificación distintos. El sistema de niveles se actualizó a principios de 2026, con topes de gasto programados para entrar en vigencia a partir del 1 de abril de 2026 (fuente: ai.google.dev/gemini-api/docs/billing, verificado en marzo de 2026).
Quédate en el nivel gratuito si tu aplicación realiza menos de 100 llamadas a la API por día y te sientes cómodo con que tus datos se utilicen para mejorar los productos de Google. El nivel gratuito es ideal para proyectos personales, creación de prototipos, investigación académica y herramientas internas de bajo volumen. Dirigiendo las solicitudes a Flash-Lite, obtienes hasta 1,000 solicitudes por día sin costo alguno, lo cual es más que suficiente para muchos casos de uso legítimos.
Actualiza al Nivel 1 si necesitas más de 100 solicitudes diarias, requieres garantías de privacidad de datos o necesitas límites de velocidad consistentes para cargas de trabajo de producción. La activación del Nivel 1 solo requiere vincular una cuenta de facturación sin gasto mínimo. Inmediatamente obtienes 150-300 RPM dependiendo del modelo, lo que representa una mejora de 30 veces sobre el nivel gratuito. El tope de gasto mensual es de $250, proporcionando una red de seguridad natural contra costos inesperados. La mayoría de las aplicaciones pequeñas y medianas encontrarán el Nivel 1 suficiente.
Actualiza al Nivel 2 si consistentemente necesitas más de 300 RPM o tu uso mensual excede los $250. Calificar requiere $100 en gasto acumulado y al menos 3 días desde tu primer pago. El Nivel 2 desbloquea hasta 1,000 RPM y eleva el tope de gasto a $2,000 por mes. Este nivel es apropiado para aplicaciones de producción que sirven a cientos de usuarios simultáneos.
Actualiza al Nivel 3 si estás ejecutando cargas de trabajo a escala empresarial que requieren el mayor rendimiento. Calificar requiere $1,000 en gasto acumulado y 30 días desde tu primer pago. El Nivel 3 ofrece los límites de velocidad más altos y topes de gasto que van desde $20,000 hasta más de $100,000 por mes. Para un recorrido paso a paso del proceso de actualización, consulta nuestro tutorial detallado de actualización de nivel.
La información clave que muchos desarrolladores pasan por alto es que el Nivel 1 es funcionalmente gratuito para entrar. Solo pagas por los tokens que realmente consumes, no hay tarifa de suscripción ni compromiso mínimo. Si tu uso se mantiene bajo, tu factura mensual podría ser de solo unos pocos dólares mientras obtienes límites de velocidad significativamente más altos y protección completa de privacidad de datos.
7 estrategias para maximizar tu nivel gratuito
Ya sea que te quedes en el nivel gratuito o actualices a un plan de pago, estas estrategias de optimización te ayudarán a extraer el máximo valor de cada llamada a la API. Estas técnicas son acumulativas, y combinar múltiples estrategias puede reducir tu costo efectivo entre un 60 y un 80 por ciento en comparación con patrones de uso sin optimizar.
Estrategia 1: Enrutamiento inteligente de modelos
La optimización más simple es enrutar las solicitudes al modelo más económico que pueda manejarlas adecuadamente. No todas las consultas necesitan la potencia de razonamiento de Gemini 2.5 Pro. Para tareas de clasificación, respuesta a preguntas simples y extracción de datos estructurados, Flash-Lite ofrece resultados comparables a una fracción del costo. Construye una capa de enrutamiento que evalúe la complejidad de la consulta y dirija las solicitudes simples a Flash-Lite (15 RPM, 1,000 RPD en el nivel gratuito) mientras reserva Pro para tareas que genuinamente requieren razonamiento avanzado.
Estrategia 2: Aprovecha la API por lotes
Para cargas de trabajo que no requieren respuestas en tiempo real, la API por lotes de Google ofrece un descuento fijo del 50 por ciento en todos los precios de modelos. Las solicitudes por lotes se ponen en cola y se procesan dentro de 24 horas, lo que la hace ideal para generación de contenido, análisis de documentos, canalizaciones de extracción de datos y cualquier tarea donde unas pocas horas de latencia sean aceptables. En el nivel gratuito, las solicitudes por lotes tienen sus propios límites de velocidad separados, duplicando efectivamente tu rendimiento disponible. Esta única estrategia puede reducir a la mitad tus costos cuando eventualmente actualices a un nivel de pago.
Estrategia 3: Almacenamiento en caché de contexto para contextos repetidos
Si tu aplicación envía repetidamente el mismo contexto grande, como un prompt de sistema, documentos de referencia o ejemplos few-shot, el almacenamiento en caché de contexto puede reducir drásticamente los costos de tokens de entrada. El contexto almacenado en caché se cobra aproximadamente un 75 por ciento menos que los tokens de entrada estándar, con una tarifa de almacenamiento adicional por hora. El punto de equilibrio es aproximadamente cuando reutilizas el mismo contexto más de 4-5 veces dentro de una hora. Para aplicaciones RAG y chatbots con prompts de sistema fijos, esta optimización por sí sola puede reducir los costos de entrada entre un 50 y un 75 por ciento. Nuestra guía de reducción de costos con almacenamiento en caché de contexto proporciona detalles de implementación y ejemplos de código.
Estrategia 4: Compresión y optimización de prompts
Reducir el conteo de tokens de entrada sin sacrificar la calidad de salida es una optimización de alto impacto. Elimina la verbosidad innecesaria de los prompts de sistema, usa instrucciones de formato concisas y aprovecha los esquemas de salida estructurada que le indican al modelo exactamente qué formato devolver. Un prompt bien optimizado puede ser entre un 40 y un 60 por ciento más corto que uno sin optimizar mientras produce resultados idénticos. En el nivel gratuito, donde el TPM está limitado a 250,000, los prompts eficientes significan más solicitudes útiles por minuto.
Estrategia 5: Implementa retroceso exponencial con variación aleatoria
Cuando alcanzas los límites de velocidad, la lógica de reintento ingenua puede empeorar las cosas al crear tormentas de reintentos sincronizados. Implementa retroceso exponencial con variación aleatoria (jitter) para distribuir los reintentos a lo largo del tiempo. Comienza con un retraso de 1 segundo, duplícalo en cada reintento y añade una variación aleatoria de hasta el 50 por ciento. Limita el retraso máximo a 60 segundos y los reintentos totales a 5 intentos. Este enfoque maximiza tu rendimiento real al evitar reintentos desperdiciados mientras respeta la limitación de velocidad de Google.
Estrategia 6: Deduplicación de solicitudes y almacenamiento en caché
Antes de enviar cualquier solicitud a la API, verifica si ya has recibido una respuesta idéntica o suficientemente similar. Implementa una caché local, ya sea en memoria para aplicaciones simples o respaldada por Redis para sistemas de producción, que almacene respuestas indexadas por un hash de la entrada. Para muchas aplicaciones, entre el 20 y el 40 por ciento de las solicitudes son duplicadas o casi duplicadas que pueden servirse desde la caché, reduciendo drásticamente tanto el costo como la latencia.
Estrategia 7: Estrategia de conmutación por error multiproveedor
En lugar de depender enteramente de un solo proveedor de API, construye una cadena de conmutación por error que enrute a proveedores alternativos cuando alcances los límites de velocidad de Gemini. Cuando tu cuota de Gemini se agote, cambia automáticamente a OpenAI, Claude o alternativas de código abierto a través de plataformas como laozhang.ai que agregan múltiples proveedores bajo un solo punto de acceso a la API. Este enfoque maximiza tu cuota gratuita efectiva en todos los proveedores mientras asegura que tu aplicación nunca se caiga debido a la limitación de velocidad de un solo proveedor.
Preguntas frecuentes
¿Es realmente gratuita la API de Gemini?
Sí, la API de Gemini ofrece un nivel genuinamente gratuito que no requiere tarjeta de crédito y no tiene fecha de expiración. Obtienes acceso a modelos que incluyen Gemini 2.5 Pro, Flash y Flash-Lite con límites de velocidad de 5-15 RPM y 100-1,000 RPD. La principal contrapartida es que tus datos pueden utilizarse para mejorar los productos de Google en el nivel gratuito.
¿Cómo soluciono los errores 429 "resource exhausted"?
Un error 429 significa que has excedido uno de tus límites de velocidad (RPM, TPM o RPD). Primero, verifica qué límite estás alcanzando examinando los encabezados de respuesta del error. Si es RPD, espera hasta medianoche hora del Pacífico para el reinicio diario. Si es RPM o TPM, implementa retroceso exponencial con variación aleatoria. Considera cambiar a un modelo con límites más altos, como Flash-Lite con 1,000 RPD, o actualizar al Nivel 1 para obtener límites de velocidad 30 veces mayores.
¿Cuál es la diferencia entre el nivel gratuito y el Nivel 1?
El nivel gratuito solo requiere una cuenta de Google y proporciona RPM y RPD limitados. El Nivel 1 requiere vincular una cuenta de facturación pero no tiene gasto mínimo. Las diferencias clave son los límites de velocidad (150-300 RPM vs 5-15 RPM), la privacidad de datos (el Nivel 1 no usa tus datos para entrenamiento) y el acceso a funciones como el almacenamiento en caché de contexto y la API por lotes a precios de pago. Actualizar es esencialmente gratuito ya que solo pagas por los tokens consumidos.
¿Puedo usar el nivel gratuito para aplicaciones de producción?
Técnicamente sí, pero conlleva riesgos significativos. Los recortes de cuota de diciembre de 2025 demostraron que Google puede reducir los límites del nivel gratuito sin previo aviso. Los límites de velocidad del nivel gratuito de 5-15 RPM son demasiado bajos para la mayoría de las aplicaciones orientadas al usuario, y las implicaciones de privacidad de datos pueden violar las expectativas de tus usuarios o los requisitos regulatorios. Para cualquier aplicación que sirva a usuarios reales, el Nivel 1 es el mínimo recomendado.
¿Cómo se compara el nivel gratuito de Gemini con los LLM locales?
Los LLM locales eliminan los límites de velocidad y los costos de API por completo, pero requieren una inversión significativa en hardware. Ejecutar un modelo de código abierto capaz como Llama requiere al menos 12GB de VRAM para inferencia, y la calidad generalmente queda por detrás de Gemini 2.5 Pro para tareas complejas. El nivel gratuito de Gemini es mejor para la mayoría de los desarrolladores que necesitan calidad de modelo de frontera sin inversión en hardware, mientras que los modelos locales son adecuados para cargas de trabajo sensibles a la privacidad con requisitos más simples y recursos de GPU disponibles.
¿Reducirá Google los límites del nivel gratuito nuevamente?
Google no ha anunciado planes para más reducciones, pero el precedente de diciembre de 2025 muestra que los límites del nivel gratuito pueden cambiar sin previo aviso. El mejor enfoque es diseñar la arquitectura de tu aplicación para manejar cambios en los límites de velocidad de manera elegante, usar las estrategias de optimización de esta guía para minimizar la dependencia del nivel gratuito de cualquier proveedor individual, y tener un plan de actualización listo aunque no lo actives inmediatamente.