
짧게 답하면: Claude 529 overloaded_error는 보통 Anthropic이 일시적으로 과부하 상태이거나, 요청 경로 상의 업스트림 서비스가 포화되었다는 뜻입니다. 그래서 첫 번째 대응은 프롬프트를 다시 쓰거나 API 키를 바꾸는 것이 아니라, Claude의 현재 상태 페이지와 최근 incident를 확인하는 것입니다. API를 직접 호출하는 경우 두 번째 단계는 backoff를 둔 재시도이고, Claude chat이나 Claude Code를 쓰는 경우에는 실제로는 plan limit 또는 chat 쪽 capacity warning을 보고 있는 것은 아닌지도 먼저 구분해야 합니다.
이 차이는 2026년에는 더 중요해졌습니다. Anthropic release notes에 따르면 2025년 8월 11일 이후 일부 급격한 usage spike 시나리오는 예전처럼 529 overloaded_error가 아니라 429 rate_limit_error 를 반환합니다. 즉, 지금의 529 가이드는 “조금 기다렸다 다시 시도하세요”에서 끝나면 안 되고, 먼저 어떤 클래스의 실패인지 구분해줘야 합니다.
그리고 이건 이론만이 아닙니다. Anthropic의 공개 status feed는 2026년 3월 19일 00:28 UTC에 “Elevated errors across surfaces” incident를 열었고, claude.ai, platform.claude.com, Claude API, Claude Code를 모두 partial outage 로 표시했습니다. 이 글의 최종 재확인 시점인 01:21 UTC에는 그 incident가 이미 monitoring 으로 전환되었고, Anthropic은 사용자가 23:59-00:30 UTC 사이에 인증 오류 급증을 겪었다고 설명했습니다. 이런 순간에 사용자가 필요한 것은 장황한 정의가 아니라 진짜 진단 플로우입니다.
핵심 요약
Claude 529 overloaded_error는 대체로 Anthropic 측 과부하 신호이지, 요청 형식이 잘못되었다는 뜻이 아닙니다. 먼저 status.claude.com 과 incidents feed를 확인하세요. 이 글의 최종 점검 시점인 2026년 3월 19일에는 Anthropic summary가 여전히 Minor Service Outage 를 보여줬고, “Elevated errors across surfaces” incident는 이미 investigating에서 monitoring 으로 이동한 상태였으며, 원인 시간대는 23:59-00:30 UTC 로 설명되었습니다. 여러분이 확인하는 순간 플랫폼 상태가 건강하다면 그다음에 jitter를 포함한 retry와 burst traffic 감소를 시도하면 됩니다. 실제 오류가 429라면 rate limiting 문제로 처리해야 합니다. Claude chat에서 “Due to unexpected capacity constraints...” 같은 문구가 보인다면, Anthropic 공식 문서상 이것은 formal outage가 아니며 status page에 표시되지 않을 수도 있습니다.
| 신호 | 보통 무엇을 의미하는가 | 어디에서 보이는가 | 첫 번째 행동 |
|---|---|---|---|
529 overloaded_error | Anthropic 또는 업스트림 서비스의 일시적 과부하 | API, Workbench, Claude Code, Anthropic 연동 도구 | 상태 확인, backoff 재시도, request ID 저장 |
429 rate_limit_error | 조직 단위 RPM / ITPM / OTPM / acceleration limit 도달 | API 및 API 기반 도구 | retry-after 준수, burst 감소, /en/posts/claude-api-quota-tiers-limits 확인 |
| “Due to unexpected capacity constraints...” | Claude chat의 높은 수요 | claude.ai | 잠시 기다렸다 새로고침 |
| “5-hour limit reached” | 플랜 사용 창을 모두 소진 | Claude chat / Claude Code 구독 흐름 | 리셋 대기 또는 /ko/posts/claude-code-rate-limit 확인 |
Claude 529 Overloaded Error가 실제로 뜻하는 것
Anthropic이 529 overloaded_error를 반환할 때, 가장 흔한 해석은 “지금은 용량상 요청을 안정적으로 처리할 수 없다”입니다. 이것은 malformed request, 만료된 API 키, 권한 문제와는 전혀 다른 범주의 이슈입니다. 실제 현장에서는 플랫폼 전체가 바쁜 시간대, 특정 모델 백엔드가 혼잡한 시간, 또는 Claude Code / Workbench 뒤쪽 체인이 압박받는 시점에 529가 자주 보입니다.
이 키워드에 대한 검색 의도가 유난히 불안 중심인 이유도 여기에 있습니다. 사용자는 작업 도중 529를 보고 곧바로 에러 문자열을 검색하며 “이게 내 문제인가, Anthropic 문제인가?”를 알고 싶어합니다. 그런데 현재 1페이지 결과의 많은 글은 “다른 사람도 겪고 있다”는 확인만 줄 뿐, 무엇을 해야 하는지까지 연결하지 못합니다.
Anthropic의 help center, API 문서, release notes를 함께 보면 실용적인 진단은 훨씬 선명해집니다.
529는 보통 service overload 또는 temporary upstream saturation을 가리킨다429는 rate limiting을 가리킨다- chat capacity warning은 Claude chat 제품 레이어의 문제다
- 5-hour limit 메시지는 plan quota 문제다
핵심은 정의를 외우는 것이 아니라, 처음부터 문제 클래스를 잘못 잡지 않는 것입니다.
529 vs 429 vs capacity constraints vs usage limit

사용자들이 이 주제에서 시간을 가장 많이 낭비하는 이유는, Anthropic에 “지금은 못 씁니다”라는 상태가 여러 종류 있지만 그것들이 같은 레이어에 속하지 않기 때문입니다.
Anthropic의 공식 문서 understand Claude error messages는 chat-side capacity constraints가 일시적 고수요 상황이며, status page에는 나타나지 않는다고 설명합니다. 즉 Claude chat이 느리거나 막혔는데 상태 페이지가 녹색이라고 해서, 곧바로 로컬 환경 문제라고 결론내리면 안 됩니다.
반대로 API 쪽은 다릅니다. rate limits 문서는 조직 단위 제한이 더 짧은 시간 조각에서도 enforcement 된다고 설명합니다. 여기에 release notes의 중요한 변경점이 더해집니다. 2025년 8월 11일 이후 일부 급격한 사용량 증가 시나리오는 529 대신 429를 반환합니다.
그래서 예전 커뮤니티 글에서 보이던 “529와 429는 거의 같은 overload”라는 식의 기억은 2026년 진단 기준으로는 부정확합니다.
| 조건 | 레이어 | 전형적 원인 | 하지 말아야 할 일 |
|---|---|---|---|
529 overloaded_error | Anthropic 서비스 / 업스트림 용량 | 일시적 과부하, live incident, 백엔드 혼잡 | 정상 코드와 키를 바로 의심하기 |
429 rate_limit_error | 조직의 API 사용 패턴 | tier 한도, RPM/TPM 압력, burst | 플랫폼 outage로 취급하기 |
| capacity-constraint banner | Claude chat 제품 레이어 | 채팅 인터페이스의 높은 부하 | status page가 빨갛지 않다고 안심하기 |
| 5-hour limit message | 플랜 할당량 | 사용 창 소진 | login 또는 network 설정만 계속 만지기 |
Claude Code를 자주 쓴다면 구독 한도와 API 쪽 제한을 나눠서 보는 것이 특히 중요합니다. 더 깊은 설명은 /ko/posts/claude-code-rate-limit에서 볼 수 있습니다.
먼저 상태를 확인하라: 실제 Anthropic incident를 검증하는 방법
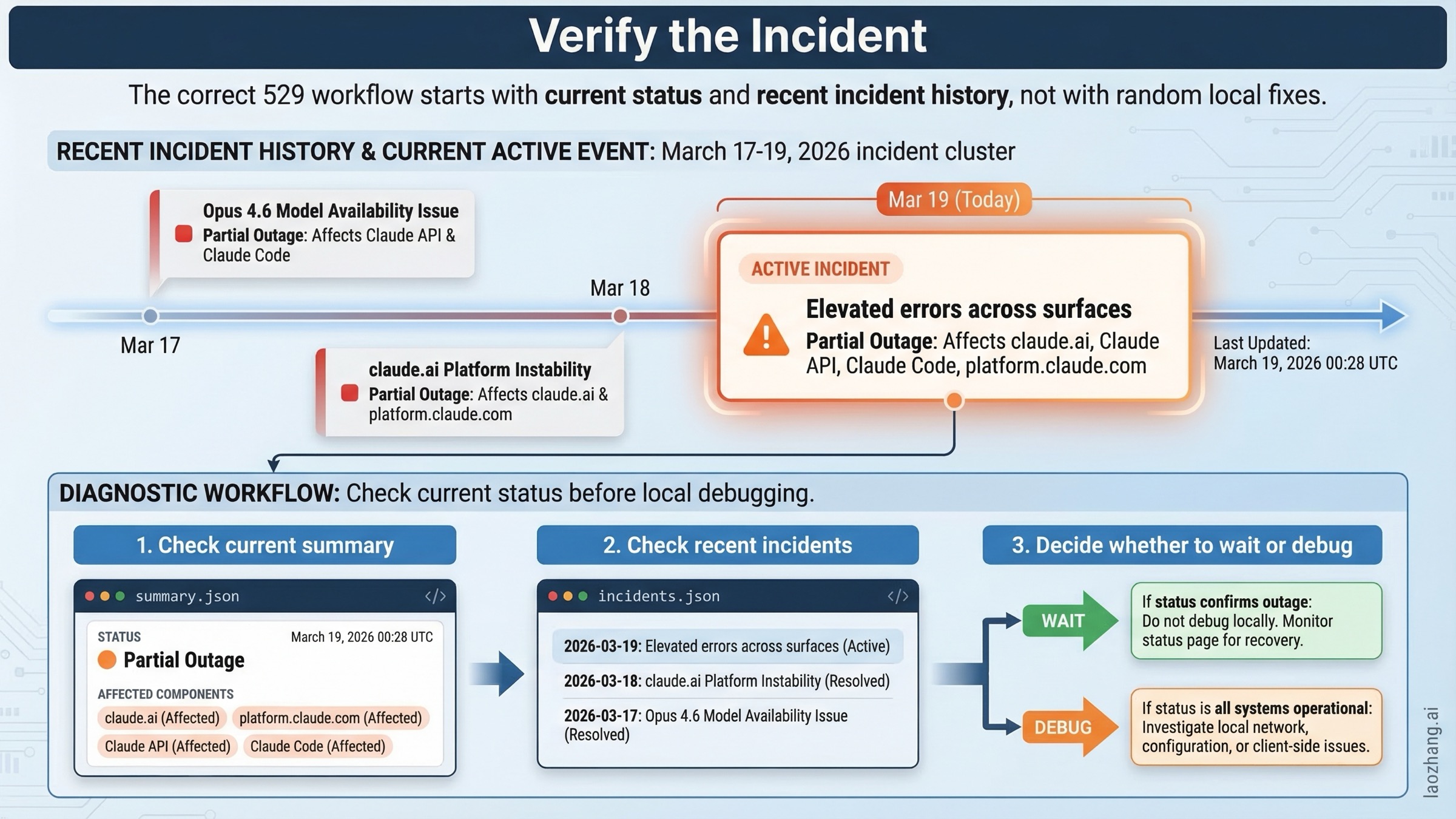
이 검색어에 대해 가장 유용한 첫 반응은 정의가 아니라 status workflow입니다.
먼저 status.claude.com 을 확인하세요. 더 자세한 정보가 필요하면 다음 machine-readable endpoint를 직접 보면 됩니다.
https://status.claude.com/api/v2/summary.jsonhttps://status.claude.com/api/v2/incidents.json
이 두 endpoint가 중요한 이유는 claude.ai, platform.claude.com, Claude API, Claude Code 같은 컴포넌트별 상태를 보여주기 때문입니다.
2026년 3월 19일에 다시 확인했을 때 summary endpoint는 완전한 green 보드가 아니었습니다. Minor Service Outage 상태였고, 주요 컴포넌트는 partial outage 로 표시되어 있었습니다. 이어서 01:21 UTC 업데이트에서는 “Elevated errors across surfaces” incident가 monitoring 으로 전환되었고, 23:59-00:30 UTC 사이의 인증 오류 증가가 원인 구간으로 적혔습니다. incidents feed를 보면 왜 최근 이력까지 같이 봐야 하는지도 분명해집니다. 2026년 3월 17일~19일 사이 Claude에는 연속된 incident cluster가 있었고, 예를 들면 다음과 같습니다.
- 2026년 3월 17일: Claude Opus 4.6 elevated errors
- 2026년 3월 18일: Claude Opus 4.6 elevated errors
- 2026년 3월 18일: Opus 4.6 increased errors
- 2026년 3월 18일: Claude.ai elevated errors, Claude Code도 영향
- 2026년 3월 19일: “Elevated errors across surfaces” incident가 00:28 UTC에 열리고 01:21 UTC에 monitoring으로 전환
이 사실만으로도 “30초 뒤 다시 시도” 같은 조언은 충분하지 않습니다. 짧은 장애라면 통할 수 있지만, 실제 outage window 안에 있다면 로컬 디버깅만 계속하는 것은 시간 낭비입니다.
운영상 기억할 만한 경고도 있습니다. anthropics/claude-code 저장소의 Issue #1838 에서는 사용자가 overloaded_error를 겪고 있는데 dashboard 반영이 늦었던 사례가 공유되었습니다. status page가 무의미하다는 뜻은 아니지만, 초기 몇 분 동안은 사용자 보고가 먼저 올라올 수도 있다는 의미로 읽는 편이 맞습니다.
안전한 순서는 다음과 같습니다.
- summary 확인
- incidents 확인
- 한 surface만 문제인지, 한 model family만 문제인지, 전체 workflow 문제인지 분리
- 공식 상태가 아직 녹색이어도 외부 보고가 쌓이고 있다면, 파괴적 변경 없이 보수적으로 retry
production workload라면 JSON feed를 모니터링에 넣는 쪽이 dashboard UI만 보는 것보다 낫습니다.
처음 10분 동안 해야 할 일
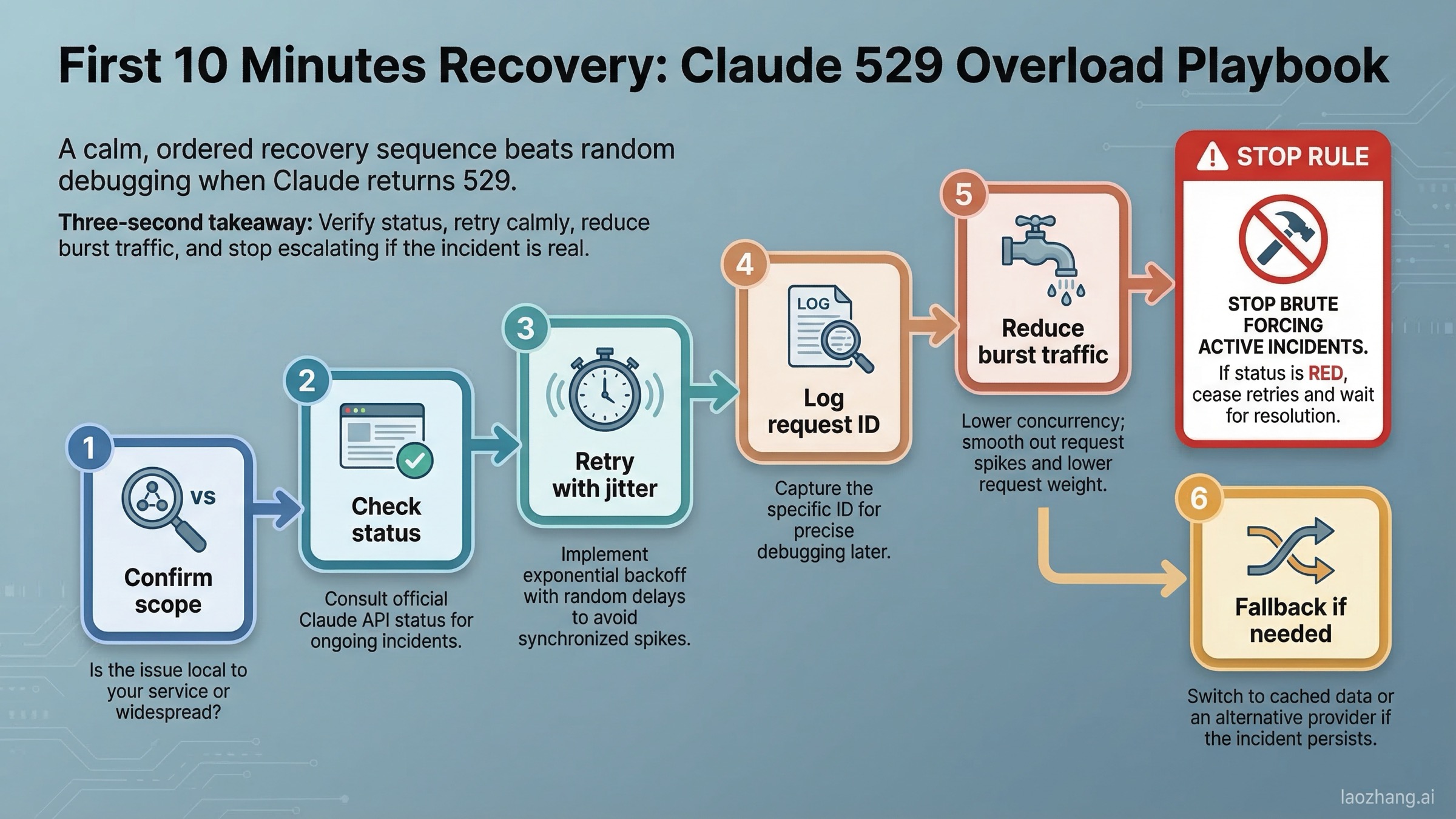
API, Workbench, Claude Code에서 529를 본다면 다음 순서가 실용적입니다.
1단계: 범위를 확인한다. Claude chat과 API가 동시에 흔들린다면 platform-side incident 가능성이 크게 올라갑니다. 한 경로만 실패한다면 upstream 또는 자신의 체인을 함께 점검해야 합니다.
2단계: jitter가 있는 retry를 한다. transient overload는 retry가 합리적인 몇 안 되는 경우지만, 서비스에 분노한 듯 재시도 폭탄을 날리는 것은 상황을 악화시킵니다. exponential backoff에 작은 random jitter를 더하세요. Anthropic Python SDK 문서는 connection errors, 408, 409, 429, >=500에 대해 기본적으로 2회 자동 재시도를 한다고 설명합니다.
3단계: request ID를 남긴다. _request_id 는 support와 postmortem에 매우 유용합니다.
4단계: burst를 줄인다. rate limits 문서대로 더 짧은 간격에서도 enforcement가 있고 API는 token-bucket 방식으로 동작합니다. 지금 보이는 것이 529여도 concurrency spike를 낮추는 것이 좋습니다.
5단계: 실제로는 429가 아닌지 확인한다. exception이나 error body가 RateLimitError라면 mental model을 바꿔야 합니다. 그때는 /en/posts/claude-api-429-solution이 더 맞는 가이드입니다.
6단계: request weight를 줄인다. 거대한 context window, 긴 tool output, 무거운 첨부가 있다면 잠시 가볍게 만드세요.
7단계: 코드만이 아니라 timing도 바꾼다. 특정 모델군이 안 좋은 시간대라면 10~20분 미루는 편이 무의미한 retry를 누적하는 것보다 낫습니다.
pythonimport time import random from anthropic import Anthropic, APIStatusError, RateLimitError client = Anthropic(max_retries=2) def call_with_jitter(messages, max_attempts=5): for attempt in range(max_attempts): try: return client.messages.create( model="claude-sonnet-4-6", max_tokens=1024, messages=messages, ) except RateLimitError: # 429: generic overload가 아니라 rate limiting으로 처리 raise except APIStatusError as e: if e.status_code == 529: delay = min(2 ** attempt, 20) + random.uniform(0, 1) time.sleep(delay) continue raise raise RuntimeError("Claude remained overloaded after retries")
핵심은 brute force가 아니라 graceful degradation입니다.
Claude chat과 Claude Code 사용자는 어떻게 봐야 하나
이 키워드로 들어오는 많은 사용자는 raw API를 직접 호출하지 않습니다. claude.ai, Claude Code, Workbench, Cursor, MCP 체인 등 결국 Anthropic에 도달하는 도구 안에서 막힙니다. 그래서 troubleshooting sequence도 조금 달라집니다.
Claude chat 의 경우 Anthropic 공식 문서는 capacity warning이 일시적이라고 설명합니다. 보이는 메시지가 chat-side capacity warning이라면, 몇 분 기다렸다 새로고침하는 것이 일반적으로 더 맞습니다. 반면 5-hour limit 메시지는 플랜 사용량 소진을 뜻합니다.
Claude Code 의 경우 login 문제, 기록 이상, 더 넓은 서비스 이상 징후가 함께 있는지 보세요. 실제로 2026년 3월 18일 incident update에서는 Claude.ai 측 장애가 Claude Code의 login/logout에도 영향을 주었다고 적혀 있었습니다. 즉 Claude Code 증상은 종종 더 큰 Anthropic incident의 일부일 수 있습니다.
Claude Code 앞에 MCP server나 다른 local bridge가 있다면 그 중간 레이어도 확인하세요. routing layer가 원본 오류를 감싸 증상을 흐릴 수 있습니다. 관련 배경은 /en/posts/claude-mcp-complete-guide-2025에서 볼 수 있습니다.
실무적으로는 이렇게 기억하면 됩니다.
- Anthropic 전체가 흔들리면 incident부터 의심
- 구독 경로만 막히면 chat capacity 또는 plan limit 확인
- API 자동화만 막히면 529와 429를 먼저 분리
앞으로 529를 줄이려면
provider-side overload를 없앨 수는 없지만, 자신의 운영 피해를 줄일 수는 있습니다.
첫 번째는 traffic shape 입니다. 0에서 최대 concurrency로 바로 점프하지 마세요. Anthropic 문서는 burst traffic이 평균이 낮아도 문제를 일으킬 수 있다고 경고합니다.
두 번째는 prompt와 context 절제 입니다. 더 가벼운 request는 retry하기 쉽고 timeout 같은 다른 문제와 엮일 가능성이 줄어듭니다.
세 번째는 cache와 reuse 입니다. 같은 큰 prefix를 계속 보내는 설계는 비용과 failure surface를 동시에 늘립니다.
네 번째는 tier strategy 입니다. Anthropic의 service tiers 문서에 따르면 Priority Tier는 production workload를 위한 옵션이며 peak time의 server overloaded errors를 줄이는 데 목적이 있습니다. outage-proof는 아니지만, Standard를 production SLA처럼 보면 안 된다는 신호입니다.
다섯 번째는 fallback architecture 입니다. 한 provider의 나쁜 시간대가 전체 업무를 멈추게 한다면, 그것은 공급자 문제이면서 동시에 설계 문제입니다. laozhang.ai 같은 OpenAI-compatible relay는 이런 redundancy 문맥에서만 자연스럽게 등장해야 합니다.
여섯 번째는 monitoring 입니다. incidents feed polling, request ID 기록, model family별 error spike 추적은 Reddit이나 GitHub보다 훨씬 운영에 도움이 됩니다.
반복적인 529가 사실은 burst control 또는 조직 한도 문제를 가리는 것이라면 다음으로 읽을 글은 /en/posts/claude-api-quota-tiers-limits입니다.
FAQ
Claude 529 overloaded_error는 내 잘못인가요? 보통은 아닙니다. 대부분 Anthropic 또는 업스트림 서비스의 일시적 포화 신호입니다. 다만 지나치게 공격적인 retry는 증상을 악화시킬 수 있습니다.
529는 보통 얼마나 지속되나요? 고정된 시간은 없습니다. 몇 분 안에 끝나기도 하고 더 오래가기도 합니다. 믿을 수 있는 것은 live incidents feed입니다.
바로 retry해야 하나요? 네, 하지만 backoff와 jitter를 포함해야 합니다. 차분한 1~2회 retry는 합리적이지만, 병렬 재시도 폭탄은 그렇지 않습니다.
529와 429는 같은가요? 아닙니다. 2026년 기준으로는 다른 진단 경로로 보는 편이 맞습니다. 429는 rate limiting, 529는 대개 overload입니다.
Claude chat이 깨졌는데 status page는 정상으로 보이는 이유는 무엇인가요? Anthropic 공식 문서가 chat-side capacity constraints는 formal outage가 아니며 status page에 나타나지 않을 수 있다고 설명하기 때문입니다.
코딩 중 이 문제가 생기면 가장 안전한 순서는 무엇인가요? 상태 확인, 작업 저장, backoff retry, 그리고 incident가 길어지면 fallback model 또는 fallback endpoint로 전환하는 것입니다. Claude Code를 많이 쓰는 사용자일수록 두 번째 경로를 미리 준비해 두는 편이 훨씬 낫습니다.