
Если нужен короткий ответ на 19 марта 2026 года, он такой: Gemini 3.1 Flash-Lite лучше подходит для дешевых и быстрых high-volume задач, а Gemini 2.5 Flash остается более безопасным выбором по умолчанию, когда важнее Stable-статус, бесплатный Google Search grounding и предсказуемое production-поведение. То есть реальный вопрос здесь не "какая модель новее", а "нужно ли мне заменять 2.5 Flash везде или только на части маршрутов".
Эта тема запутывает из-за названия. Многие разработчики автоматически предполагают, что модель с суффиксом Flash-Lite обязана быть слабее старого полноценного Flash по всем параметрам. Текущие официальные документы Google показывают более сложную картину. На странице цен 3.1 Flash-Lite дешевле 2.5 Flash по input и output. На странице DeepMind она быстрее и лидирует в ряде benchmark-строк. Но те же официальные материалы оставляют 2.5 Flash впереди по FACTS, по MRCR v2 на 1M context, а его model card сохраняет статус general availability.
Краткое содержание
Практический вывод выглядит так: если у вас latency-sensitive и high-throughput задачи вроде перевода, классификации, structured extraction или routing, сначала тестируйте Gemini 3.1 Flash-Lite. Если вам нужен более безопасный default с бесплатным Search grounding или вы сильнее завязаны на grounded / very-long-context поведение, оставляйте Gemini 2.5 Flash первым кандидатом.
Официальная картина на 19 марта 2026 года:
| Область | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Что это значит |
|---|---|---|---|
| Текущий статус | Preview | Stable / GA | 3.1 новее, но 2.5 безопаснее как production-default |
| Model ID | gemini-3.1-flash-lite-preview | gemini-2.5-flash | Переключение должно быть явным, а не слепой заменой |
| Цена input | Free, затем $0.25 / 1M | Free, затем $0.30 / 1M | 3.1 дешевле на входе |
| Цена output | Free, затем $1.50 / 1M | Free, затем $2.50 / 1M | 3.1 заметно дешевле на выходе |
| Context window | 1,048,576 tokens | 1,048,576 tokens | Размер контекста не главный дифференциатор |
| Max output | 65,536 tokens | 65,536 tokens | Потолок вывода одинаковый |
| Free-tier grounding | Нет бесплатного Search grounding | Search grounding бесплатно до 500 RPD | 2.5 удобнее для grounded-assistant сценариев |
| Скорость по DeepMind | 363 tokens/s | 249 tokens/s | 3.1 быстрее |
| Ключевая оговорка | Сильнее на GPQA, MMMU-Pro, LiveCodeBench, 128k MRCR | Сильнее на FACTS и 1M MRCR | 3.1 не побеждает вообще везде |
Эти строки собираются из официальных pricing, Gemini 3.1 Flash-Lite page, Gemini 2.5 Flash page, release notes и сравнения DeepMind на flash-lite page.
Практическая рекомендация простая:
- Перевод, extraction, routing и другие high-volume полосы логично сначала отправлять на 3.1 Flash-Lite.
- Grounded ассистентов, risk-sensitive default и truly long-context задачи разумнее пока держать на 2.5 Flash.
- Если можете поддерживать split routing, именно это и есть самый защищаемый ответ на 19 марта 2026 года.
Почему это сравнение кажется странным
Оно кажется странным, потому что это не аккуратное сравнение "один класс против такого же класса". Логичнее было бы сравнивать Gemini 3.1 Flash-Lite с Gemini 2.5 Flash-Lite. Но production-команды не выбирают по маркетинговой симметрии. Они сравнивают текущий рабочий baseline с тем, что потенциально может его вытеснить.
Именно поэтому здесь настоящей базой выступает Gemini 2.5 Flash. Это зрелая low-latency reasoning-модель в публичном Gemini API. Официальная страница 2.5 Flash по-прежнему относит ее к Stable versions, а model card отдельно подтверждает статус general availability.
Gemini 3.1 Flash-Lite стартовал по другой логике. В официальных release notes указано, что он был запущен 3 марта 2026 года как первый Flash-Lite в серии Gemini 3. На специальной model page Google прямо позиционирует его для translation, transcription, simple document processing, high-volume structured extraction и model routing. То есть Google продвигает его не как "облегченную игрушку", а как дешевую и быструю рабочую полосу.
Правильная ментальная модель здесь такая:
- Gemini 2.5 Flash это стабильная рабочая лошадка.
- Gemini 3.1 Flash-Lite это более быстрый и дешевый Preview-претендент.
- Решать нужно не "кто звучит престижнее", а "на какие маршруты какую модель ставить".
Цены, бесплатный уровень и grounding на 19 марта 2026 года

Большинство страниц в выдаче правильно замечают, что 3.1 Flash-Lite дешевле 2.5 Flash, но обычно не доводят эту мысль до инженерного решения.
Согласно официальной pricing page, на 19 марта 2026 года:
- Gemini 3.1 Flash-Lite Preview: free standard usage, затем
\$0.25input и\$1.50output за 1M tokens - Gemini 2.5 Flash: free standard usage, затем
\$0.30input и\$2.50output за 1M tokens
То есть:
- input дешевле примерно на 17%
- output дешевле на 40%
В реальной эксплуатации разница по output часто важнее, чем по input. Суммаризации, классификация с объяснением, короткие support-ответы, JSON extraction с развернутыми полями: именно output-линия быстро раздувает счет. Поэтому 3.1 Flash-Lite выигрывает не "символически", а вполне ощутимо.
Batch-цены сохраняют тот же вектор:
- 3.1 Flash-Lite Batch:
\$0.125input и\$0.75output - 2.5 Flash Batch:
\$0.15input и\$1.25output
Но официальная страница цен одновременно показывает, почему 2.5 Flash не исчезает. Ключевая развилка это grounding:
- у Gemini 2.5 Flash есть free-tier Google Search grounding до 500 RPD
- у Gemini 3.1 Flash-Lite Preview бесплатного Search grounding на free tier нет; дальше идет другая, платная логика с лимитом 5,000 prompts per month
Если ваше приложение строится вокруг встроенного поиска Google, 2.5 Flash проще защитить как default: дешевле обойдется ранний rollout, и публичная grounding-история понятнее. Если grounding вам не нужен, дешевый output у 3.1 Flash-Lite становится очень сильным аргументом в его пользу.
Если вам нужен отдельный разбор free tier, русская локализация уже есть в статье Gemini API free quota 2026. Для operational troubleshooting тоже есть локализованный Gemini API error troubleshooting guide. Но по pricing-деталям и thinking controls часть материалов в этом репозитории пока остается английской, поэтому ниже я отмечаю такие ссылки как явные fallback.
Бенчмарки: где выигрывает 3.1 Flash-Lite и почему 2.5 Flash еще важен

Самый полезный официальный источник для этого сравнения это страница DeepMind, где Gemini 3.1 Flash-Lite High сопоставляется с Gemini 2.5 Flash Dynamic.
Ключевые строки выглядят так:
| Метрика | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | Куда склоняется вывод |
|---|---|---|---|
| Output speed | 363 tokens/s | 249 tokens/s | 3.1 Flash-Lite |
| Humanity's Last Exam | 16.0% | 11.0% | 3.1 Flash-Lite |
| GPQA Diamond | 86.9% | 82.8% | 3.1 Flash-Lite |
| MMMU-Pro | 76.8% | 66.7% | 3.1 Flash-Lite |
| LiveCodeBench | 72.0% | 62.6% | 3.1 Flash-Lite |
| MRCR v2 at 128k | 60.1% | 54.3% | 3.1 Flash-Lite |
| FACTS | 40.6% | 50.4% | Gemini 2.5 Flash |
| MRCR v2 at 1M | 12.3% | 21.0% | Gemini 2.5 Flash |
Отсюда возникает более честная картина, чем в большинстве "launch-style" материалов.
Плюсы миграции на 3.1 очевидны:
- он быстрее
- он дешевле
- он впереди по заметным reasoning, coding и multimodal сигналам
Но и доводы в пользу сохранения 2.5 не искусственные:
- FACTS ближе к grounded factuality, и здесь 2.5 впереди
- MRCR v2 at 1M важен, если у вас правда длинные документы и long-range retrieval не декоративный пункт, а реальная метрика
Поэтому я бы не советовал слепо заменять 2.5 Flash везде в первый же день. Если приложение сильно зависит от grounded answers или от very-long-context поведения, у 2.5 Flash остается вполне защитимая роль.
Google в официальном launch post отдельно подчеркивает 2.5x faster time to first answer token и 45% higher output speed по сравнению с 2.5 Flash. Эти headline-цифры объясняют шум вокруг модели, но не отменяют caveat-строк из той же официальной экосистемы.
Риски Preview, лимиты и что по-прежнему дает Stable
Benchmark-победы это только половина решения. Вторая половина это lifecycle status.
На официальной rate-limits page есть три детали, которые легко пропустить:
- лимиты считаются на project, а не на API key
- у preview models лимиты обычно жестче
- указанные лимиты не гарантированы, и фактическая capacity может меняться
Вот почему слово Preview имеет инженерный смысл. Оно не означает "не использовать", но означает "не считать это застывшим baseline".
На той же странице есть и сигнал в пользу 3.1 Flash-Lite. В публичной Batch API таблице для Tier 1 указано:
- Gemini 3.1 Flash-Lite Preview: 10,000,000 enqueued batch tokens
- Gemini 2.5 Flash: 3,000,000 enqueued batch tokens
Если вы строите большие асинхронные очереди, это реальное преимущество по throughput. Но это не повод переоценивать одну таблицу: сама же страница предупреждает, что actual capacity may vary.
Stable по-прежнему покупает вам три вещи:
- Меньше lifecycle churn. 2.5 Flash сейчас в Stable, 3.1 Flash-Lite в Preview.
- Более чистую публичную grounding-историю. 2.5 Flash все еще лучше выглядит как grounded default.
- Более простое обоснование default-маршрута. Когда что-то ломается, "мы оставили stable-модель по умолчанию" защищать проще, чем "мы подняли preview-полосу ради лучших benchmark".
Если нужно отдельно разобраться в thinking behavior, здесь пока уместен явный английский fallback: Gemini API thinking-level guide. То же относится к более подробной англоязычной разбивке лимитов: Gemini API rate-limits-per-tier guide.
Какой моделью пользоваться для разных нагрузок
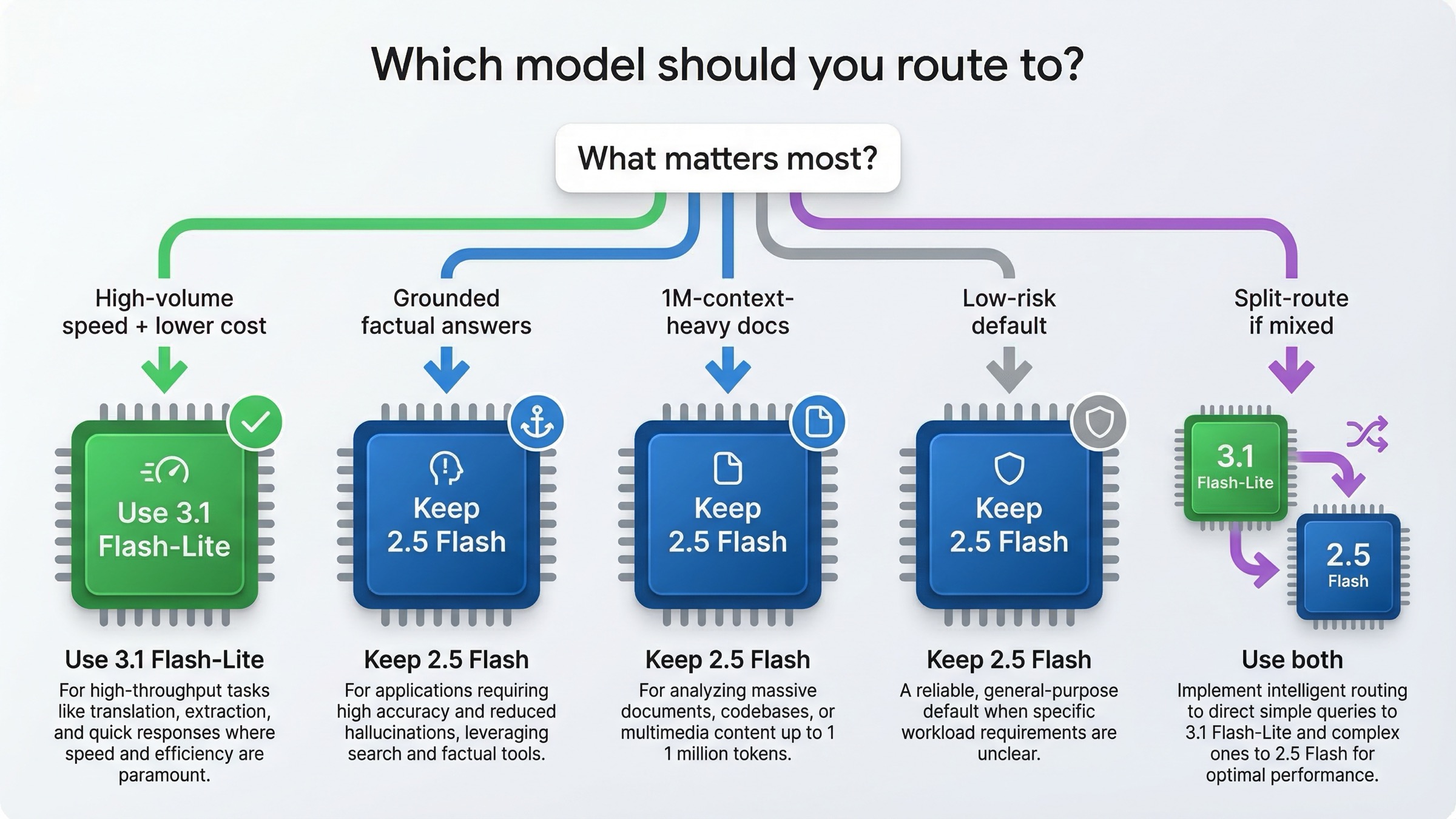
Если перевести это сравнение в routing policy, картина становится заметно проще.
| Нагрузка | Первый выбор | Почему |
|---|---|---|
| Массовый перевод | Gemini 3.1 Flash-Lite | Google сам позиционирует модель под translation, а цена/скорость идеально совпадают с этим сценарием |
| Structured extraction и JSON pipelines | Gemini 3.1 Flash-Lite | Более дешевый output и меньшая latency важнее Stable-статуса |
| Routing / classifier layers | Gemini 3.1 Flash-Lite | Model page буквально приводит routing как подходящий use case |
| Легкий coding и UI generation | Gemini 3.1 Flash-Lite | Сильнее LiveCodeBench и быстрее отклик |
| Search-grounded factual assistants | Gemini 2.5 Flash | Бесплатный grounding и более сильный FACTS-сигнал делают его безопаснее |
| Очень длинные документы около 1M context | Gemini 2.5 Flash | Он выигрывает официальную MRCR-строку на 1M |
| Широкий production-default при низкой tolerance к риску | Gemini 2.5 Flash | Stable / GA все еще многое значит |
| Системы со split routing | Обе модели | 2.5 для grounded/long-context, 3.1 для fast high-volume полос |
Есть еще одна тонкость: thinking controls различаются. В model card 2.5 Flash 2.5 описывается как hybrid reasoning model с configurable thinking budgets. Для 3.1 Flash-Lite Google чаще использует язык reasoning levels. Если у вас архитектура завязана на точную настройку inference budget, эта разница важнее, чем кажется по заголовкам.
Как мигрировать без сожалений
Лучшая стратегия на март 2026 года это не "переключить все", а staged rollout.
-
Сначала low-risk, high-volume полосы
Переносите на 3.1 Flash-Lite перевод, extraction, classification, routing и другие конвейеры, где скорость и цена дают немедленную отдачу. -
Держите grounded и long-context полосы на 2.5 Flash
Если вы зависите от встроенного Search grounding или реально прогоняете сценарии близко к 1M context, не убирайте 2.5 Flash из default-маршрута слишком рано. -
Сохраняйте fallback и regression lane
Не удаляйте маршрут на 2.5 только потому, что 3.1 выглядит лучше в публичных таблицах. Пока вы не прогнали собственные prompt-evals, latency budgets и failure patterns, у вас должен оставаться безопасный откат.
Эту позицию проще всего сформулировать так:
- если ваши bottleneck это скорость и token cost, сначала переключайте 3.1
- если bottleneck это grounding, long-context retrieval или stability requirement, оставляйте 2.5
- если умеете в split routing, не выбирайте один маршрут там, где логичнее иметь два
FAQ
Gemini 3.1 Flash-Lite лучше Gemini 2.5 Flash?
В большинстве быстрых и недорогих reasoning-задач да: он быстрее, дешевле и сильнее по ряду официальных benchmark-сигналов. Но если вы включаете в "лучше" stable lifecycle, free-tier grounding и отдельные long-context/factuality метрики, 2.5 Flash все еще может быть лучшим выбором.
Gemini 3.1 Flash-Lite действительно дешевле?
Да, относительно Gemini 2.5 Flash. Официальная pricing page указывает \$0.25 input и \$1.50 output для 3.1 Flash-Lite против \$0.30 input и \$2.50 output для 2.5 Flash.
Почему не стоит заменять 2.5 Flash везде сразу?
Потому что 3.1 все еще Preview, а официальные же таблицы оставляют 2.5 Flash впереди по FACTS и MRCR v2 at 1M. Для grounded и very-long-context production-цепочек это не декоративные оговорки.
Какой самый защищаемый выбор сейчас?
Делить маршруты. Используйте 3.1 Flash-Lite для быстрых high-volume задач, а 2.5 Flash сохраняйте для grounded, long-context и stability-sensitive маршрутов.