
Ошибки Gemini API делятся на две категории, требующие совершенно разных стратегий обработки: повторяемые ошибки (429, 500, 503, 504), при которых ожидание и повторная отправка запроса в итоге приведут к успеху, и неповторяемые ошибки (400, 403, 404), при которых необходимо изменить код или конфигурацию, прежде чем запрос сможет быть выполнен. Понимание этого различия -- самый важный принцип в обработке ошибок API, и неправильный подход означает либо бесполезную трату времени на повторные запросы, которые никогда не сработают, либо отказ от запросов, которые прошли бы при небольшой задержке. В этом руководстве рассмотрена каждая ошибка, с которой вы столкнётесь, вместе с рабочим кодом, который можно скопировать в свой проект.
Краткое содержание
Каждая ошибка Gemini API соответствует одной из двух стратегий: повторный запрос с экспоненциальной задержкой (для 429, 500, 503, 504) или исправление и повторное развёртывание (для 400, 403, 404). Ошибка 429 RESOURCE_EXHAUSTED составляет примерно 90% жалоб разработчиков в 2026 году, во многом потому, что Google незаметно снизил лимиты бесплатного уровня на 50--80% в декабре 2025 года. Если вы получаете ошибки 429 на бесплатном уровне, самый быстрый путь к решению -- включить тарификацию для перехода на лимиты Tier 1, которые обычно вступают в силу немедленно. При серверных ошибках (500/503) проверьте страницу статуса Google AI, прежде чем отлаживать собственный код. Таблица ниже содержит краткий справочник по каждому коду ошибки.
| HTTP-код | gRPC-статус | Повторяемая? | Первое действие |
|---|---|---|---|
| 400 | INVALID_ARGUMENT | Нет | Проверить формат тела запроса |
| 400 | FAILED_PRECONDITION | Нет | Включить тарификацию или сменить регион |
| 403 | PERMISSION_DENIED | Нет | Проверить API-ключ и разрешения |
| 404 | NOT_FOUND | Нет | Проверить имя модели и пути к ресурсам |
| 429 | RESOURCE_EXHAUSTED | Да | Подождать, затем повторить с задержкой |
| 500 | INTERNAL | Да | Повторить через 5--10 секунд |
| 503 | UNAVAILABLE | Да | Повторить через 30--60 секунд |
| 504 | DEADLINE_EXCEEDED | Да | Увеличить таймаут, уменьшить объём входных данных |
Дерево диагностики ошибок
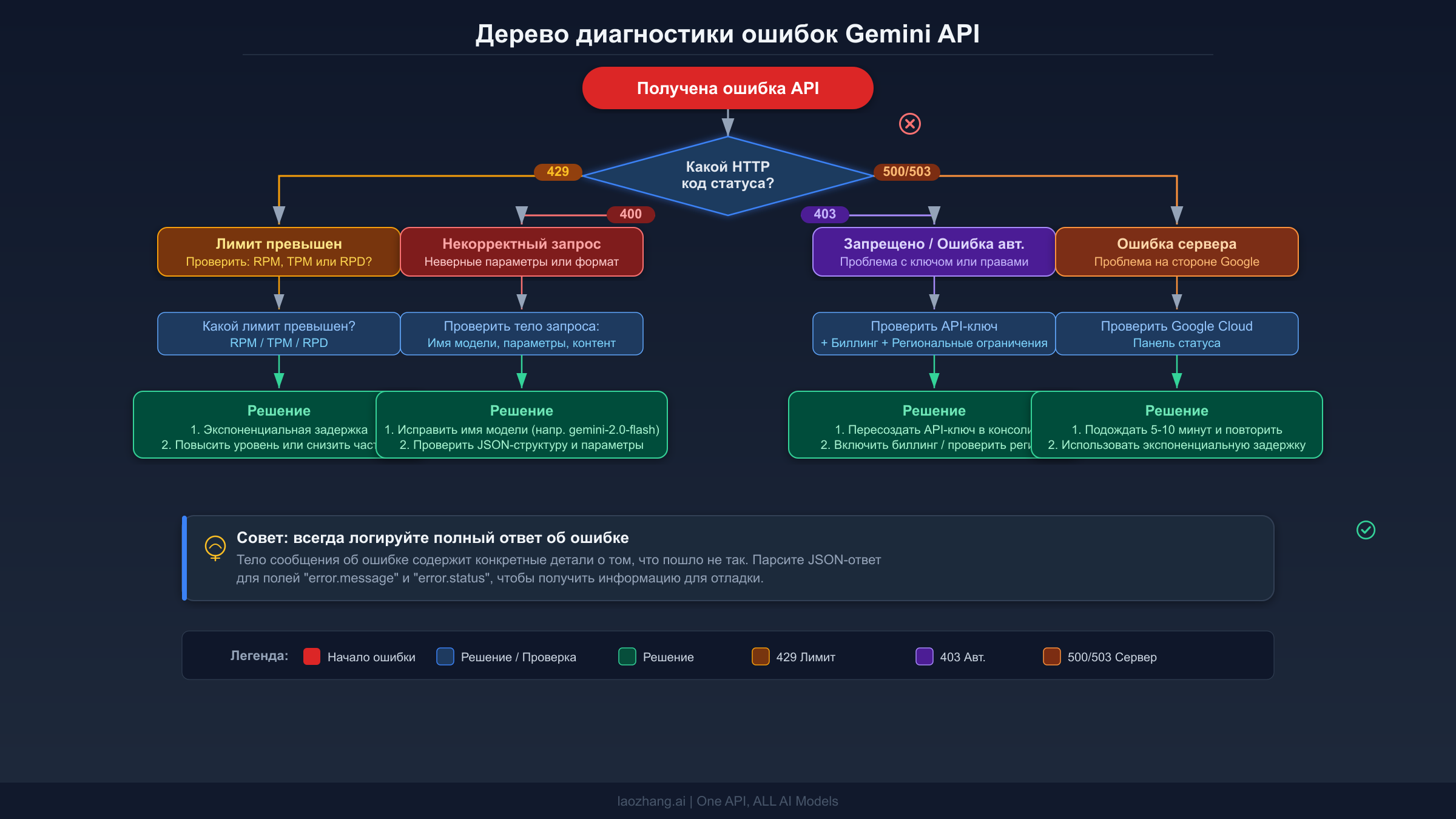
Когда запрос к Gemini API завершается ошибкой, HTTP-код статуса указывает, какому диагностическому пути следовать. Критически важный первый шаг -- прочитать полное тело ответа с ошибкой, а не только код статуса. Каждая ошибка Gemini API возвращает JSON-объект, содержащий поле status с именем gRPC-ошибки и поле message с читаемым описанием, которое часто указывает непосредственно на проблему. Многие разработчики совершают ошибку, перехватывая исключения на уровне HTTP и отбрасывая эти детали, что превращает пятиминутное исправление в час догадок.
Последовательность диагностики работает следующим образом. Сначала проверьте, находится ли код статуса в диапазоне 4xx или 5xx. Если это 4xx, проблема на вашей стороне, и повторный запрос не поможет. Необходимо изучить сообщение об ошибке, определить, что не так с вашим запросом, исправить и повторить попытку. Если это 5xx, проблема, скорее всего, на стороне Google. Проверьте страницу статуса, и если сервис выглядит работоспособным, реализуйте логику повторных запросов с экспоненциальной задержкой. Единственное исключение из этого чёткого разделения -- ошибка 429, которая технически является кодом 4xx, но ведёт себя как временная ошибка, разрешающаяся при достаточном ожидании или снижении частоты запросов.
Для каждого типа ошибки следуйте этой последовательности. Начните с логирования полного ответа об ошибке, включая заголовки, особенно заголовок Retry-After для ошибок 429. Затем проверьте, встречали ли вы эту ошибку ранее в логах. Повторяющиеся ошибки 400 на одном и том же эндпоинте указывают на систематическую проблему с формированием запросов. Спорадические ошибки 429 говорят о необходимости ограничения частоты запросов на стороне клиента. Постоянные ошибки 403 после развёртывания указывают на проблему с переменными окружения или управлением секретами. Понимание этих паттернов значительно экономит время отладки. Если вы работаете с Gemini CLI и сталкиваетесь с постоянными ошибками 429, учтите, что CLI имеет собственное поведение ограничения частоты, отдельное от прямых вызовов API, как описано в gemini-cli issue #10722 на GitHub.
Детальный разбор -- 429 RESOURCE_EXHAUSTED (самая частая ошибка)
Ошибка 429 RESOURCE_EXHAUSTED -- безоговорочно самая часто встречающаяся ошибка Gemini API, и её распространённость резко выросла после того, как Google незаметно снизил лимиты бесплатного уровня на 50--80% 6--7 декабря 2025 года. До этой даты Gemini 2.0 Flash предлагал 10 RPM на бесплатном уровне. После изменения значение упало до 5 RPM, а дневные лимиты запросов претерпели аналогичные сокращения по всем моделям. Это изменение не было объявлено через официальные каналы и застало тысячи разработчиков врасплох. Если ваше приложение прекрасно работало в ноябре 2025 года, но начало выдавать ошибки 429 в декабре без каких-либо изменений кода -- это почти наверняка причина.
Gemini API измеряет ваше потребление по трём независимым параметрам, и превышение любого одного из них вызывает ошибку 429. Эти параметры: RPM (запросы в минуту), TPM (токены в минуту на входе) и RPD (запросы в день). Это означает, что вы можете быть в пределах лимита RPM, но всё равно получить ограничение, потому что несколько крупных запросов превысили порог TPM. Актуальные лимиты бесплатного уровня, проверенные по официальной документации 17 марта 2026 года, приведены ниже.
| Модель | Бесплатный RPM | Бесплатный RPD | Бесплатный TPM |
|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250 000 |
| Gemini 2.5 Flash | 10 | 250 | 250 000 |
| Gemini 2.5 Flash-Lite | 15 | 1 000 | 250 000 |
Источник: ai.google.dev/gemini-api/docs/rate-limits, проверено 17.03.2026
Лимиты применяются на проект, а не на API-ключ. Это важнейшее различие, которое сбивает с толку многих разработчиков. Создание нескольких API-ключей внутри одного проекта Google Cloud не даёт дополнительной квоты. Если вам нужна большая ёмкость, потребуется либо отдельный проект (что противоречит условиям использования Google, если делается для обхода лимитов), либо переход на платный уровень.
Как определить, какой лимит вы превысили
При получении ошибки 429 сообщение в ответе обычно указывает, какой конкретный лимит был превышен, но не всегда чётко. Вот как систематически определить узкое место. Сначала проверьте потребление в Google Cloud Console в разделе APIs & Services > Gemini API > Quotas. Если потребление RPM резко возрастает, а TPM остаётся низким, вы делаете слишком много мелких запросов и должны их группировать. Если TPM резко растёт, а RPM умеренный, ваши запросы содержат слишком много входных данных, и следует сократить длину контекста или перейти на меньшую модель. Если ограничивающим фактором является RPD, вы достигли дневного потолка и должны либо подождать до полуночи по тихоокеанскому времени для сброса, либо повысить уровень.
Проблема «фантомных 429»
В начале 2026 года несколько разработчиков с платными аккаунтами Tier 1 сообщили о получении ошибок 429 RESOURCE_EXHAUSTED, несмотря на то что их панели мониторинга показывали нулевое или почти нулевое потребление. Этот феномен «фантомных 429» представляется серверным багом в системе учёта квот Google. Если вы столкнулись с этим, сначала убедитесь, что панель мониторинга отображает данные нужного проекта. Затем проверьте, не запущены ли пакетные задания API, поскольку пакетные операции потребляют отдельные квоты, которые могут не отображаться в реальном времени. Если ничего из этого не применимо, по общему мнению сообщества следует подождать 15--30 минут, так как проблема обычно решается сама. Если она сохраняется более часа, подайте заявку в поддержку через Google AI Developers Forum. Обсуждение этой проблемы можно найти в темах, таких как этот отчёт на Google AI Developers Forum, где разработчики делятся обходными решениями.
Практические шаги для снижения ошибок 429 без повышения уровня
Если переход на платный уровень пока невозможен, несколько стратегий оптимизации могут значительно снизить частоту ошибок 429 на бесплатном уровне. Наиболее эффективный подход -- группировка запросов, при которой несколько мелких запросов объединяются в меньшее количество крупных. Поскольку бесплатный уровень ограничивает RPM строже, чем TPM, отправка одного запроса с 10 вопросами гораздо эффективнее, чем отправка 10 отдельных запросов. Gemini API поддерживает многораундовые диалоги в рамках одного запроса, что делает эту оптимизацию простой в реализации.
Ещё одна мощная техника -- ограничение частоты на стороне клиента, при котором ваше приложение устанавливает лимиты строже, чем у API, для сохранения запаса прочности. Если бесплатный уровень разрешает 10 RPM для Gemini 2.5 Flash, настройте клиент на отправку максимум 8 запросов в минуту. Этот буфер поглощает временные колебания и предотвращает раздражающий паттерн превышения лимита последним запросом в пакете. Реализовать это можно с помощью простого алгоритма «корзины токенов» или скользящего окна. Даже добавление задержки в 100--300 миллисекунд между последовательными запросами часто достаточно для предотвращения ошибок 429, связанных с пиковыми нагрузками.
Для приложений, допускающих более высокую задержку, Batch API предлагает принципиально иной подход к управлению квотами. Пакетные запросы имеют собственные отдельные лимиты (100 одновременных запросов, ограничение входного файла 2 ГБ) и обрабатываются асинхронно, что означает, что они не конкурируют с вашими запросами в реальном времени за квоту. Google явно рекомендует Batch API для рабочих нагрузок, не требующих немедленных ответов, таких как конвейеры обработки данных, очереди генерации контента и задачи оценки. Это часто упускаемое из виду решение, которое может полностью устранить ошибки 429 для подходящих сценариев использования.
Более подробное руководство, специально посвящённое ошибкам 429, включая продвинутые техники оптимизации, смотрите в нашем детальном руководстве по исправлению 429 RESOURCE_EXHAUSTED. Для полного разбора лимитов по всем уровням и моделям обратитесь к нашему полному руководству по лимитам для каждого уровня.
Исправление ошибок 400 и 403 (неповторяемые)
В отличие от ошибок 429, ошибки 400 и 403 указывают на фундаментальную проблему с вашим запросом или аутентификацией, которая не разрешится ожиданием. Повторять эти ошибки без каких-либо изменений бессмысленно и тратит как ваше время, так и квоту API.
400 INVALID_ARGUMENT -- некорректный запрос
Ошибка 400 со статусом INVALID_ARGUMENT означает, что Gemini API получил ваш запрос, но не смог его обработать, потому что что-то в теле запроса неправильно. Наиболее частые причины: отправка неподдерживаемого значения параметра, превышение максимального лимита выходных токенов для данной модели, передача недопустимого значения temperature или topP, или ссылка на имя модели, которое не существует или было устарело.
Вот конкретный пример, который ловит многих разработчиков. Модели Gemini 3.x требуют, чтобы параметр temperature оставался на значении по умолчанию 1.0. Установка значения 0.2 или 0.7, что прекрасно работает с моделями Gemini 2.5, может вызвать зацикливание или ухудшение качества с моделями Gemini 3, а также может спровоцировать ошибку 400. Всегда проверяйте ограничения параметров для конкретной модели в справочной документации API. Исправление ошибок 400 следует последовательному шаблону: внимательно прочитайте сообщение об ошибке, сравните параметры вашего запроса с документацией и исправьте несоответствие.
python# BAD - Gemini 3 Pro Preview was shut down March 9, 2026 model = "gemini-3-pro-preview" # GOOD - Use the current model model = "gemini-2.5-flash" # Common 400 error: invalid parameter for model # BAD - temperature < 1.0 can cause issues with Gemini 3.x config = {"temperature": 0.3} # GOOD - use default temperature for Gemini 3.x config = {"temperature": 1.0}
400 FAILED_PRECONDITION -- региональное или тарифное ограничение
Эта разновидность ошибки 400 означает, что ваш аккаунт не соответствует необходимым условиям для использования API. Две наиболее частые причины -- работа из неподдерживаемого региона без включённой тарификации и попытка использовать функции, требующие платного уровня. Если вы видите эту ошибку, перейдите в Google AI Studio и проверьте, включена ли тарификация для вашего проекта. Включение тарификации часто решает проблему немедленно, даже если вы не собираетесь тратить деньги, поскольку оно повышает ваш проект с бесплатного уровня до Tier 1.
403 PERMISSION_DENIED -- проблемы с аутентификацией и доступом
Ошибка 403 означает, что сервер понял ваш запрос, но отказывается его авторизовать. Это почти всегда проблема с API-ключом. Распространённые причины включают: использование API-ключа от неправильного проекта, использование ключа, который был отозван или скомпрометирован (Google проактивно блокирует обнаруженные в публичных репозиториях ключи), отсутствие включённого Generative Language API в проекте Google Cloud, или попытка доступа к дообученной модели без надлежащей аутентификации.
Если вы получаете ошибки 403 именно при доступе к API из браузерного приложения, учтите, что множественные входы в аккаунты Google могут вызывать конфликты аутентификации. Браузер может пытаться аутентифицироваться с использованием учётных данных рабочего аккаунта, не имеющего доступа к API, даже если ваш личный аккаунт его имеет. Решение -- выйти из всех аккаунтов Google и войти только в тот аккаунт, у которого включён доступ к API. Это удивительно распространённая проблема, как отмечается на форумах поддержки Google. Для более подробного устранения проблем с аутентификацией смотрите наше руководство по устранению ошибки 401, которое подробно охватывает смежные проблемы с учётными данными.
Создание надёжной логики повторных запросов
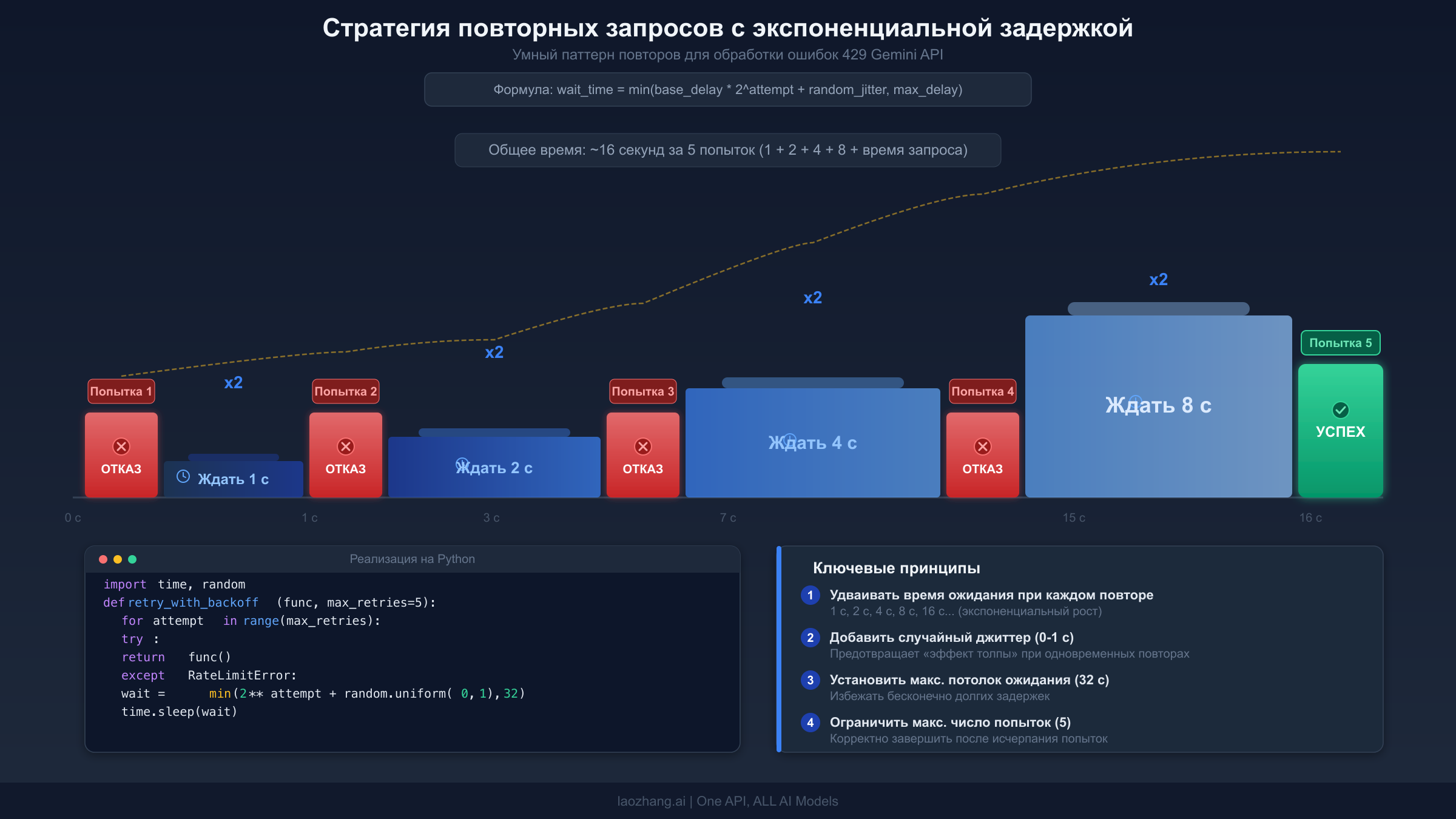
Логика повторных запросов -- ваша первая линия защиты от временных ошибок (429, 500, 503, 504). Ключевой принцип -- экспоненциальная задержка: начните с короткой паузы и удваивайте её после каждой неудачной попытки, добавляя небольшой случайный «джиттер» для предотвращения одновременного повтора всеми клиентами. Ниже представлена готовая к использованию в продакшене реализация на Python, обрабатывающая все повторяемые ошибки Gemini API.
pythonimport time import random import google.generativeai as genai from google.api_core import exceptions def call_gemini_with_retry( model_name: str, prompt: str, max_retries: int = 5, base_delay: float = 1.0, max_delay: float = 60.0 ): """Call Gemini API with exponential backoff retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content(prompt) return response except exceptions.ResourceExhausted as e: # 429 - Rate limited delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) wait_time = delay + jitter print(f"Rate limited (attempt {attempt + 1}/{max_retries}). " f"Waiting {wait_time:.1f}s...") time.sleep(wait_time) except exceptions.InternalServerError: # 500 - Server error delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay * 0.1) print(f"Server error (attempt {attempt + 1}/{max_retries}). " f"Retrying in {delay + jitter:.1f}s...") time.sleep(delay + jitter) except exceptions.ServiceUnavailable: # 503 - Service unavailable wait_time = min(30 * (2 ** attempt), 300) print(f"Service unavailable. Waiting {wait_time}s...") time.sleep(wait_time) except exceptions.InvalidArgument as e: # 400 - Do NOT retry, fix the request raise RuntimeError(f"Invalid request (not retryable): {e}") except exceptions.PermissionDenied as e: # 403 - Do NOT retry, fix credentials raise RuntimeError(f"Permission denied (not retryable): {e}") raise RuntimeError(f"Failed after {max_retries} attempts")
Та же логика на Node.js с использованием официального SDK Google Generative AI выглядит следующим образом.
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function callGeminiWithRetry(modelName, prompt, maxRetries = 5) { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result.response.text(); } catch (error) { const status = error.status || error.httpStatusCode; // Non-retryable errors — fail immediately if ([400, 403, 404].includes(status)) { throw new Error(`Non-retryable error ${status}: ${error.message}`); } // Retryable errors — wait and retry if ([429, 500, 503, 504].includes(status)) { const delay = Math.min(1000 * Math.pow(2, attempt), 60000); const jitter = Math.random() * delay * 0.1; console.log(`Error ${status}, attempt ${attempt + 1}/${maxRetries}. ` + `Waiting ${((delay + jitter) / 1000).toFixed(1)}s...`); await new Promise(r => setTimeout(r, delay + jitter)); continue; } throw error; // Unknown error, don't retry } } throw new Error(`Failed after ${maxRetries} attempts`); }
Три критически важных момента, которые многие реализации повторных запросов упускают. Во-первых, никогда не повторяйте ошибки 400 или 403. Они указывают на проблему в вашем коде или конфигурации, которая не разрешится со временем. Их повтор тратит квоту и откладывает реальное исправление. Во-вторых, добавляйте случайный «джиттер» к задержкам. Без джиттера все клиенты, получившие ограничение одновременно, будут повторять запросы одновременно, создавая «эффект толпы», который вызывает очередную волну ошибок 429. В-третьих, установите максимальный потолок задержки. Экспоненциальная задержка без ограничения может привести к абсурдно долгим ожиданиям после нескольких неудач. Шестьдесят секунд обычно является разумным максимумом для интерактивных приложений.
Обработка серверных ошибок 500 и 503
Серверные ошибки (5xx) означают, что что-то пошло не так на инфраструктуре Google, а не в вашем коде. Правильная реакция -- почти всегда повторить запрос после задержки, но для каждого типа ошибки есть важные нюансы, влияющие на то, как вы должны реагировать.
Ошибки 500 INTERNAL могут быть действительно временными или указывать на то, что ваш входной контекст слишком велик для обработки моделью. Если вы постоянно получаете ошибки 500 на одном и том же запросе, но другие запросы работают нормально, попробуйте уменьшить длину входного контекста. Документация Gemini API отмечает, что чрезмерно длинные входные контексты являются известным триггером ошибок 500, особенно с моделями, поддерживающими контекстное окно в 1 миллион токенов. Если вы обрабатываете большие документы, рассмотрите разбиение их на меньшие части и выполнение нескольких запросов вместо отправки всего за один раз.
Ошибки 503 UNAVAILABLE обычно указывают на то, что сервис Gemini находится под высокой нагрузкой. Они более вероятны в периоды пиковой нагрузки и во время развёртывания моделей. При обнаружении ошибки 503 ваше первое действие -- проверить панель статуса Google Cloud, чтобы узнать, есть ли известный инцидент. Если да, остаётся только ждать. Если страница статуса показывает, что все сервисы работают нормально, реализуйте логику повторных запросов с более длинными начальными задержками, начиная с 30 секунд вместо 1 секунды, используемой для ошибок 429.
Ошибки 504 DEADLINE_EXCEEDED означают, что обработка вашего запроса заняла больше времени, чем допускает таймаут сервера. Чаще всего это вызвано очень большими промптами или запросами, требующими интенсивных вычислений модели (например, сложные задачи рассуждения с режимом «мышления» Gemini 2.5 Pro). Решение обычно состоит в увеличении таймаута на стороне клиента. Если вы используете Python SDK, можете передать параметр timeout. Если вы делаете прямые HTTP-запросы, установите таймаут HTTP-клиента минимум 120 секунд для крупных запросов. Если ошибки 504 продолжаются даже с увеличенными таймаутами, рассмотрите переход на Batch API, который не имеет ограничений по таймауту для отдельных запросов.
Построение панели мониторинга для анализа паттернов ошибок
Понимание паттернов ошибок во времени гораздо ценнее, чем отладка отдельных ошибок. Простая система мониторинга, логирующая каждый код статуса ответа API, задержку и количество токенов, может выявить паттерны, невидимые при единичной отладке. Например, если ошибки 429 группируются в определённое время суток, возможно, вы конкурируете с другими пользователями в вашем регионе в часы пик. Если ошибки 500 коррелируют с определённой длиной промптов, вы обнаружили проблему границы контекстного окна.
Наиболее практичный подход -- логировать ответы API в структурированном формате, который можно позже запросить. Включайте метку времени, HTTP-код статуса, сообщение об ошибке, имя модели, количество входных токенов и задержку ответа в каждую запись лога. Даже простой CSV-файл или база данных SQLite обеспечивают достаточную структуру для выявления тенденций. Многие разработчики обнаруживают, что их ошибки 429 исходят от одной функции или эндпоинта, генерирующего неожиданно большой объём запросов, и исправление этого единственного узкого места устраняет большинство ошибок. Если вы предпочитаете управляемое решение, Google Cloud Operations (ранее Stackdriver) может автоматически мониторить ваше потребление Gemini API через Cloud Console, хотя для этого требуется привязка проекта к биллинг-аккаунту Google Cloud.
Когда повышать уровень -- анализ бесплатного и платного уровней
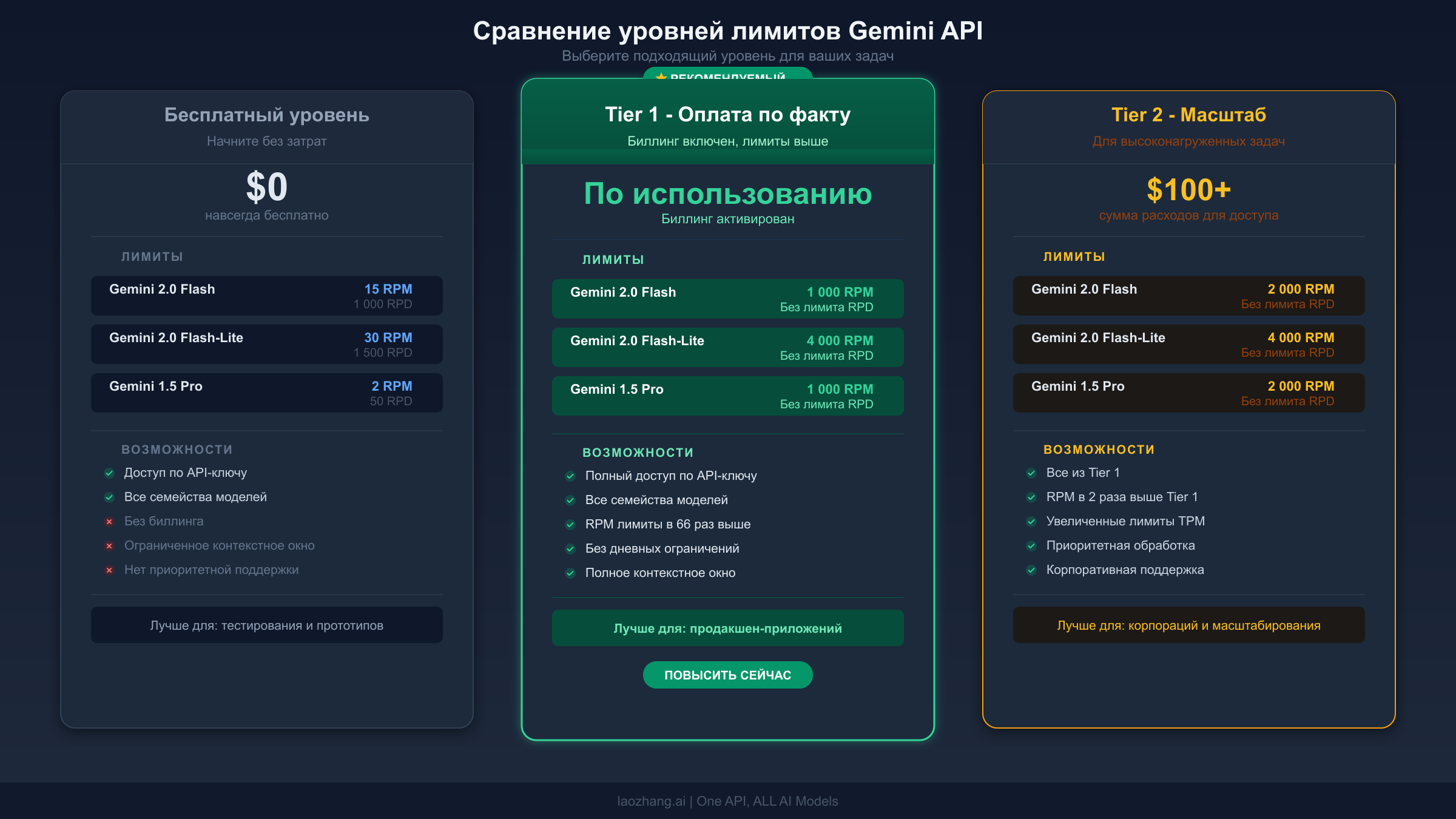
Решение о переходе с бесплатного уровня на платный становится очевидным, как только вы поймёте структуру затрат. Gemini API использует ступенчатую систему, при которой лимиты автоматически увеличиваются по мере роста ваших совокупных расходов. Вот как работают уровни, проверено по официальной документации 17 марта 2026 года.
| Уровень | Как получить | Ключевое преимущество |
|---|---|---|
| Free | Зарегистрироваться с аккаунтом Google | Ограниченный, но функциональный для тестирования |
| Tier 1 | Подключить биллинг-аккаунт | Немедленное увеличение RPM/RPD (часто в 10--20 раз) |
| Tier 2 | $100+ совокупных расходов + 3 дня | Существенная ёмкость для продакшена |
| Tier 3 | $1 000+ совокупных расходов + 30 дней | Лимиты корпоративного уровня |
Источник: ai.google.dev/gemini-api/docs/rate-limits, проверено 17.03.2026
Переход с Free на Tier 1 -- это самое значительное изменение, которое вы можете внести. Простое подключение биллинг-аккаунта, даже до того как вы потратите хоть один цент, разблокирует лимиты Tier 1, которые обычно в 10--20 раз выше бесплатного уровня. Повышение вступает в силу немедленно. Если вы регулярно получаете ошибки 429, этот единственный шаг решит большинство случаев. Обратите внимание, что начиная с 1 апреля 2026 года Google начнёт применять ограничения расходов по уровням, поэтому ознакомьтесь с документацией по биллингу, чтобы понять новые лимиты, которые могут применяться к вашему аккаунту.
Для продакшен-нагрузок, где даже лимитов Tier 1 недостаточно, рассмотрите единый API-шлюз, такой как laozhang.ai, который агрегирует запросы от нескольких провайдеров и предлагает более высокие лимиты без ограничений отдельных провайдеров. Этот подход особенно ценен, когда вашему приложению необходимо поддерживать пиковые нагрузки, превышающие лимиты любого отдельного провайдера. Ознакомьтесь с документацией на docs.laozhang.ai, чтобы узнать, как сервис прозрачно управляет ограничением частоты между провайдерами. Для полного разбора цен Gemini API по всем уровням и моделям смотрите наше руководство по ценам и квотам Gemini API. Также вы можете подробно сравнить ограничения бесплатного уровня в нашем руководстве по лимитам бесплатного уровня.
Проверка реальности затрат для индивидуальных разработчиков. Gemini 2.5 Flash, самая популярная модель для приложений, чувствительных к стоимости, стоит $0,30 за миллион входных токенов и $2,50 за миллион выходных токенов на платном уровне (ai.google.dev/gemini-api/docs/pricing, проверено 17.03.2026). Для типичного приложения, делающего 1 000 запросов в день со средним размером промптов, ежемесячные затраты составят примерно $5--15 в зависимости от длины ответа. Это незначительные затраты для любого приложения, приносящего реальную пользу, и повышение надёжности за счёт устранения ошибок 429 более чем оправдывает расходы. Вариант Gemini 2.5 Flash-Lite предлагает ещё более дешёвую опцию -- $0,10 за миллион входных токенов для приложений, где максимальное качество некритично.
Для команд, создающих продакшен-приложения с доступом к нескольким AI-провайдерам (Gemini, OpenAI, Anthropic и другим) через единый эндпоинт, единый API-шлюз, такой как laozhang.ai, может упростить вашу инфраструктуру, обеспечивая встроенное ограничение частоты, балансировку нагрузки и автоматическое переключение между провайдерами. Это особенно полезно, когда вы хотите переключаться с одного провайдера на другого при достижении лимитов, вместо того чтобы просто повторять запросы к уже ограниченному эндпоинту.
Изменения моделей 2026 года, влияющие на обработку ошибок
Ландшафт моделей Gemini значительно изменился в начале 2026 года, и некоторые из этих изменений напрямую влияют на обработку ошибок. Если вы сталкиваетесь с ошибками, которые начались недавно без изменений кода с вашей стороны, один из этих переходов моделей может быть причиной.
Gemini 3 Pro Preview был признан устаревшим и отключён 9 марта 2026 года. Если ваш код ссылается на gemini-3-pro-preview или аналогичные имена preview-моделей, вы будете получать ошибки 400 INVALID_ARGUMENT или 404 NOT_FOUND. Рекомендуемый путь миграции -- использовать gemini-3.1-pro-preview или gemini-2.5-pro в качестве стабильной альтернативы. Preview-модели по своей природе несут этот риск, и продакшен-приложения должны всегда ориентироваться на стабильные версии моделей, где это возможно.
Gemini 2.0 Flash признан устаревшим и запланирован к отключению 1 июня 2026 года. Если вы сейчас используете gemini-2.0-flash или gemini-2.0-flash-lite, запланируйте миграцию на gemini-2.5-flash или gemini-2.5-flash-lite до этой даты. Новые модели предлагают лучшую производительность при той же или более низкой стоимости, но могут иметь немного отличающееся поведение параметров, что может вызвать ошибки 400, если ваша конфигурация полагалась на специфические для модели значения по умолчанию.
Gemini Embedding 2 анонсирована как первая полностью мультимодальная модель эмбеддингов. Если вы создаёте RAG-приложения, эта новая модель может уменьшить ошибки, связанные с несоответствием формата входных данных при создании эмбеддингов различных типов контента. Текущая линейка моделей включает Gemini 3.1 Pro Preview, 3.1 Flash-Lite Preview, 3 Flash Preview и полное семейство Gemini 2.5 (Pro, Flash, Flash-Lite) вместе с их TTS-вариантами. Всегда проверяйте точную строку имени модели по официальному списку моделей, прежде чем использовать её в продакшен-коде, поскольку даже небольшие опечатки в именах моделей вызовут ошибки 404.
FAQ -- частые вопросы об ошибках Gemini API
Как исправить ошибку 429 Too Many Requests в Gemini API?
Самое быстрое решение -- добавить задержку между запросами: даже 100--300 миллисекунд часто достаточно для предотвращения высокочастотных пакетов. Для долгосрочного решения реализуйте логику повторных запросов с экспоненциальной задержкой (смотрите примеры кода на Python и Node.js в разделе о повторных запросах выше). Если вы на бесплатном уровне и регулярно получаете ошибки 429, переход на Tier 1 путём включения тарификации немедленно увеличит ваши лимиты в 10--20 раз.
Что вызывает ошибку 403 PERMISSION_DENIED в Gemini API?
Ошибка 403 почти всегда указывает на проблему с API-ключом. Наиболее частые причины: использование API-ключа от другого проекта Google Cloud (не от того, в котором включён Gemini API), использование ключа, заблокированного Google из-за его обнаружения в публичном репозитории, отсутствие включённого Generative Language API в проекте, или конфликты аутентификации в браузере при одновременном входе в несколько аккаунтов Google. Проверьте ваш ключ в Google AI Studio и при необходимости сгенерируйте новый.
Почему я получаю ошибки 429, хотя мой дашборд показывает нулевое потребление?
Это проблема «фантомных 429», о которой сообщили несколько разработчиков в начале 2026 года. Похоже, что это серверный баг в системе учёта квот Google. Сначала убедитесь, что вы смотрите на правильный проект в дашборде. Проверьте наличие запущенных пакетных заданий API, потребляющих отдельные квоты. Если ничего не подходит, подождите 15--30 минут -- проблема обычно решается сама. Если сохраняется, сообщите о ней через Google AI Developers Forum.
Ошибка 500 -- это моя вина или Google?
Ошибка 500 INTERNAL почти всегда является проблемой на стороне Google, но есть важное исключение. Если ваш входной контекст чрезвычайно велик, приближаясь к контекстному окну модели или превышая его, сервер может не справиться с обработкой и вернуть ошибку 500 вместо более описательного кода. Начните с проверки панели статуса Google Cloud, чтобы узнать, есть ли известный инцидент. Если сервис выглядит работоспособным, но вы постоянно получаете ошибки 500 на одном запросе при нормальной работе других, попробуйте уменьшить объём входных данных. Сократите промпт вдвое и посмотрите, исчезнет ли ошибка. Если да -- вы нашли границу. Для спорадических ошибок 500, затрагивающих случайные запросы, просто реализуйте логику повторных запросов с экспоненциальной задержкой. Серверы Google испытывают временные сбои, как и любая распределённая система, и большинство ошибок 500 разрешаются в течение секунд.
В чём разница между ошибками 503 UNAVAILABLE и 504 DEADLINE_EXCEEDED?
Ошибка 503 означает, что сервис Gemini временно перегружен и не может принять ваш запрос прямо сейчас. Это проблема ёмкости на стороне Google, аналогичная сигналу «занято» при звонке на телефонную линию. Обычно разрешается в течение нескольких минут и наиболее распространена в периоды пиковой нагрузки или сразу после объявления Google о новой функции модели. Ошибка 504, напротив, означает, что сервер принял ваш запрос и начал его обработку, но не смог завершить в отведённое время. Обычно это вызвано очень большими промптами или сложными задачами рассуждения, особенно с моделями типа Gemini 2.5 Pro в режиме мышления. Для 503 подождите 30--60 секунд и повторите. Для 504 увеличьте таймаут клиента минимум до 120 секунд для крупных запросов или рассмотрите разбиение входных данных на меньшие части.
Как предотвратить влияние ошибок API на пользователей?
Лучшая стратегия -- эшелонированная защита. Во-первых, реализуйте логику повторных запросов с экспоненциальной задержкой для всех повторяемых ошибок, чтобы временные сбои были невидимы для пользователей. Во-вторых, добавьте паттерн «автоматического выключателя» (circuit breaker), который прекращает отправку запросов после нескольких последовательных неудач, предотвращая каскадные ошибки. В-третьих, настройте запасное поведение, например возврат кэшированных ответов или переключение на другую модель, когда основная модель недоступна. В-четвёртых, настройте мониторинг и оповещения, чтобы узнавать о всплесках ошибок раньше ваших пользователей. Даже простое ежедневное письмо с показателями частоты ошибок по кодам статуса может выявить проблемы на раннем этапе. Для продакшен-приложений рассмотрите поддержание доступа к API через нескольких провайдеров, чтобы ограничение или сбой у одного провайдера не вывел из строя всё ваше приложение.
Могут ли заблокировать мой аккаунт Gemini API за частые ошибки 429?
Google не блокирует аккаунты просто за превышение лимитов, поскольку ошибки 429 являются ожидаемой частью нормального использования API. Однако Google проактивно блокирует API-ключи, обнаруженные в публичных репозиториях, поскольку это представляет угрозу безопасности. Если ваш API-ключ появился в публичном репозитории GitHub, Google заблокирует его, и вы получите специальное сообщение об ошибке, указывающее на утечку ключа. Решение -- сгенерировать новый API-ключ через Google AI Studio и убедиться, что он хранится безопасно с использованием переменных окружения, а не захардкожен в исходном коде. Кроме того, создание нескольких проектов Google Cloud для обхода лимитов противоречит условиям использования Google и может привести к ограничениям на уровне аккаунта.