Краткое содержание
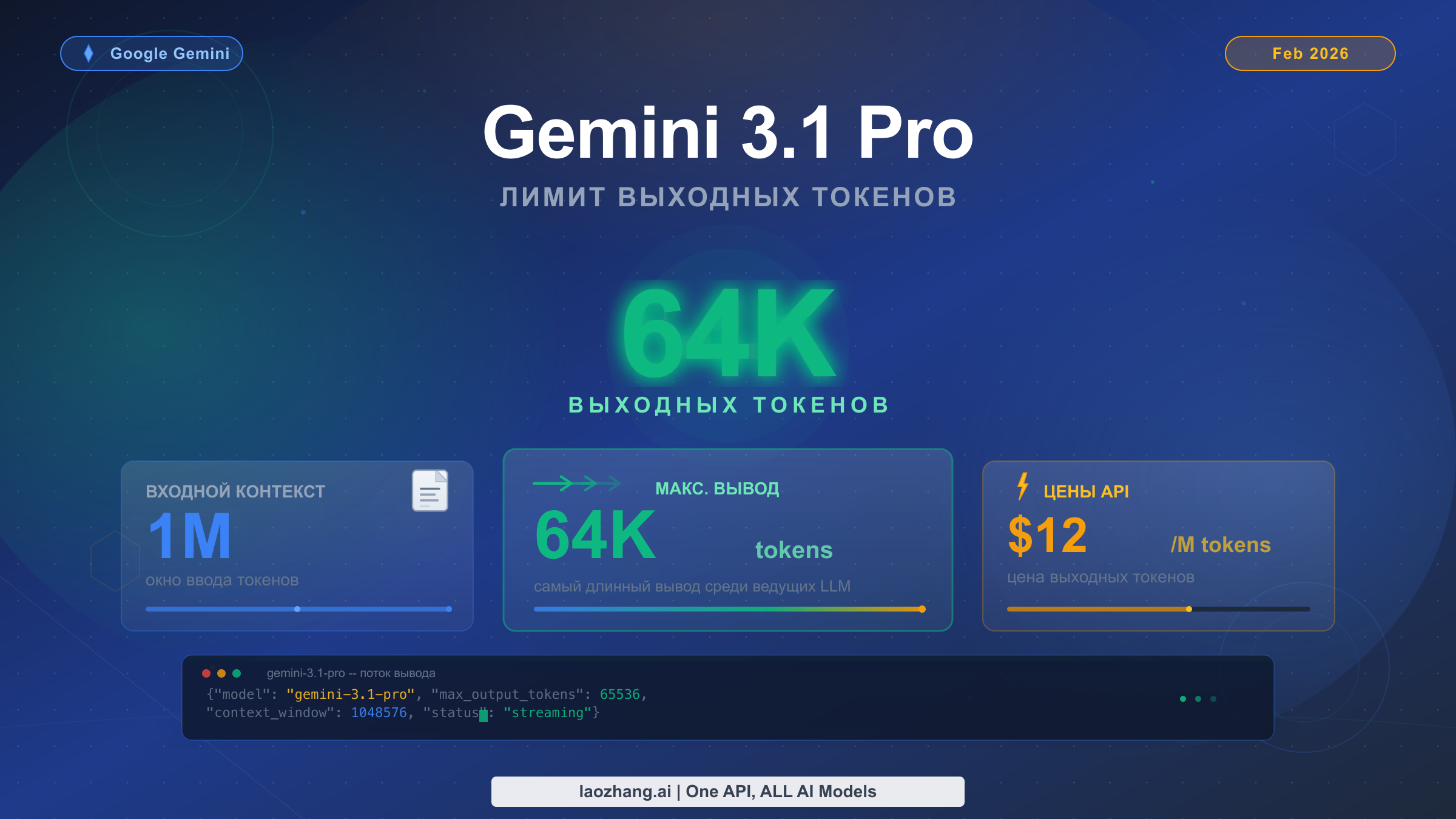
Gemini 3.1 Pro поддерживает максимальный вывод в 65 536 токенов за один ответ API, что составляет примерно 49 000 английских слов или 98 страниц текста. Модель была выпущена 19 февраля 2026 года и сочетает контекстное окно на 1 миллион входных токенов с одним из самых больших объёмов вывода среди всех передовых моделей ИИ. Однако критически важная деталь, которую упускает большинство руководств: значение maxOutputTokens по умолчанию составляет всего 8 192 — разработчики должны явно задать этот параметр, чтобы разблокировать полный объём вывода в 64K. При стоимости $12 за миллион выходных токенов (Google AI Developer API, февраль 2026) генерация ответа максимальной длины обходится примерно в $0,78.
Каков лимит вывода Gemini 3.1 Pro?
Для точного понимания спецификаций вывода Gemini 3.1 Pro необходимо разобраться в определённой путанице, которая встречается в документации и обзорах. Различные источники указывают немного разные цифры — 64K, 65K или 65 536 — и это различие имеет значение при настройке API-вызовов для продакшн-нагрузок. Официальная документация Google AI Developer для семейства моделей Gemini 3 указывает объём вывода как часть пары «1M / 64k» (ввод-вывод), тогда как сам API принимает значения maxOutputTokens в диапазоне от 1 до 65 537 (не включая верхнюю границу), что означает: фактический максимум, который вы можете установить, равен 65 536 токенам.
Число 65 536 важно, потому что оно равно 2^16 — естественной границе в вычислительных системах. Когда Google позиционирует модель как имеющую «вывод 64K», компания округляет 65 536 до ближайшей тысячи для простоты. Оба описания относятся к одной и той же фактической возможности, и для получения всех доступных токенов при настройке параметра maxOutputTokens всегда следует использовать точное значение 65 536.
Ниже приведена полная таблица спецификаций Gemini 3.1 Pro на основе официальной документации Google (ai.google.dev, проверено 20 февраля 2026 года):
| Спецификация | Gemini 3.1 Pro | Gemini 3.0 Pro | Изменение |
|---|---|---|---|
| Контекстное окно ввода | 1 000 000 токенов | 1 000 000 токенов | Без изменений |
| Максимум выходных токенов | 65 536 токенов | 65 536 токенов | Тот же потолок |
| maxOutputTokens по умолчанию | 8 192 токена | 8 192 токена | Без изменений |
| Дата отсечения знаний | Январь 2025 | Январь 2025 | Без изменений |
| Лимит загрузки файлов | 100 МБ | 20 МБ | Увеличение в 5 раз |
| Уровни мышления (thinking) | minimal, low, medium, high | low, high | +2 уровня |
| Model ID | gemini-3.1-pro-preview | gemini-3-pro-preview | Обновлён |
Самый важный вывод из этой таблицы — разрыв между максимальным выводом (65 536) и выводом по умолчанию (8 192). Это восьмикратное различие является основной причиной большинства проблем с обрезкой вывода, с которыми сталкиваются разработчики. Если вы вызываете API Gemini 3.1 Pro без явной установки maxOutputTokens, ваши ответы будут ограничены примерно 6 000 словами, независимо от того, сколько контента вы запрашиваете в промпте.
Gemini 3.1 Pro также представила ряд серьёзных улучшений помимо самого лимита вывода. Модель достигла 77,1% на ARC-AGI-2 (вместо 31,1% у Gemini 3.0 Pro), 80,6% на SWE-Bench Verified для агентного программирования и рейтинга Elo 2 887 на LiveCodeBench Pro. Эти улучшения бенчмарков означают, что контент, генерируемый в рамках вашего бюджета в 64K токенов, будет значительно более высокого качества, чем мог бы создать предыдущее поколение, — особенно для задач сложного рассуждения и генерации кода.
Стоит также отметить, что не изменилось между Gemini 3.0 Pro и 3.1 Pro. Потолок вывода остаётся на уровне 65 536 токенов — Google не увеличила максимальный объём вывода в этом релизе. Ценообразование также осталось прежним: $2 за миллион входных токенов и $12 за миллион выходных токенов для запросов менее 200 000 входных токенов, с повышенной тарификацией $4/$18 для запросов от 200 000 до 1 000 000 входных токенов (страница тарифов Google AI Developer API, проверено 20 февраля 2026 года). Кардинально изменилось качество рассуждений, способность к программированию и агентная производительность. Это означает, что разработчики, уже использующие вывод в 64K токенов Gemini 3 Pro, могут ожидать заметно лучших результатов при том же бюджете вывода, просто переключившись на model ID версии 3.1 Pro. Новый вариант эндпоинта customtools (gemini-3.1-pro-preview-customtools) также предлагает улучшенную производительность вызова инструментов для разработчиков, создающих агентные рабочие процессы с длинными структурированными выводами.
Что означают 64K выходных токенов на практике

Прежде чем переходить к настройке API, полезно понять, что в реальности представляют собой 65 536 выходных токенов. Количество токенов не соответствует напрямую количеству слов, поскольку токенизаторы разбивают текст по-разному в зависимости от языка и типа контента. Для стандартной английской прозы токенизатор Gemini создаёт примерно 1 токен на 0,75 слова, что означает: 65 536 токенов — это приблизительно 49 000 слов. Для кода соотношение иное — языки программирования обычно требуют больше токенов на строку из-за специальных символов, операторов и элементов синтаксиса, поэтому вы обычно получаете эквивалент 40 000–45 000 слов кода.
Чтобы представить эти цифры в конкретной перспективе, рассмотрим, что можно сгенерировать за один API-вызов при различных объёмах вывода. При лимите по умолчанию в 8 192 токена вы работаете примерно с 6 000 слов — достаточно для объёмного блог-поста или короткого технического документа, но не более. При 16 384 токенах объём удваивается до примерно 12 000 слов, что покрывает детальный технический отчёт или подробное руководство с примерами кода. При 32 768 токенах вы получаете около 24 000 слов — эквивалент обширной исследовательской работы или короткой главы электронной книги. А при полном лимите в 65 536 токенов вы генерируете примерно 49 000 слов — объём полноценного технического руководства, конспектов за целый семестр или многомодульного Python-приложения с исчерпывающей документацией.
Этот масштаб чрезвычайно важен для конкретных сценариев использования, где генерация контента за один проход даёт лучшие результаты, чем склеивание нескольких коротких ответов. Когда вы разбиваете длинный документ на несколько API-вызовов, вы теряете контекстуальную связность между разделами, можете внести несогласованности в терминологию или стиль и добавляете сложность в оркестрацию вашего приложения. Лимит вывода в 64K устраняет эти проблемы для большинства задач по генерации длинных текстов.
Вот сценарии использования, в которых полный объём вывода Gemini 3.1 Pro приносит наибольшую пользу. Генерация технической документации получает огромное преимущество, поскольку справочники по API, пользовательские руководства и документация по интеграции требуют единообразного форматирования и перекрёстных ссылок, которые нарушаются при разбиении на несколько вызовов. Генерация целых кодовых баз для малых и средних приложений — таких как полные CRUD API, CLI-инструменты или конвейеры обработки данных — может быть выполнена за один связный ответ, а не функция за функцией. Подготовка юридических и комплаенс-документов, где единообразие формулировок имеет юридическую значимость, выигрывает от генерации за один проход. Написание академических статей и исследовательских отчётов, где аргументация должна логически выстраиваться на протяжении тысяч слов, получает связность благодаря расширенному окну вывода. Перевод длинных документов, где контекст из ранних абзацев влияет на последующие решения, работает значительно лучше при большом бюджете вывода.
Для разработчиков, создающих продакшн-приложения, практическое правило простое: если ожидаемый вывод не превышает 6 000 слов, лимита по умолчанию в 8 192 токена достаточно. Если вам нужно от 6 000 до 25 000 слов, установите maxOutputTokens на 32 768. А если вам нужен максимальный объём вывода для генерации на уровне документа, установите 65 536 и примите соответствующие компромиссы по задержке и стоимости, связанные с генерацией такого объёма контента.
Важный момент — как Gemini токенизирует различные типы контента. Английский текст в среднем даёт около 1 токена на 0,75 слова, но структурированный контент, такой как JSON, XML или код с обширными комментариями, может значительно увеличить количество токенов. Кодовая база Python из 10 000 строк с docstring, аннотациями типов и встроенными комментариями может потребовать 80 000–100 000 токенов при измерении как вывод, что превышает лимит в 65 536. В таких случаях необходимо структурировать запросы на генерацию так, чтобы создавать управляемые фрагменты — например, генерируя модуль за модулем, а не пытаясь создать всю кодовую базу за один вызов. Аналогично, такие языки, как китайский, японский и корейский, потребляют токены иначе, чем английский — примерно 1 токен на 0,6–0,7 символов, что означает: эффективный эквивалент в словах для генерации на азиатских языках оказывается короче.
Как настроить maxOutputTokens в API
Самый важный шаг настройки для разблокировки полного объёма вывода Gemini 3.1 Pro — это явная установка параметра maxOutputTokens. Без этого каждый API-вызов по умолчанию ограничивается 8 192 токенами, независимо от указаний в вашем промпте. Рассмотрим настройку для каждого основного способа доступа.
Python (SDK google-generativeai)
Google AI Python SDK предоставляет наиболее простой путь настройки. Вы устанавливаете maxOutputTokens как часть параметра generation_config при создании модели или вызове generate_content:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3.1-pro-preview", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, } ) response = model.generate_content( "Write a comprehensive technical manual for building REST APIs with Python FastAPI." ) print(f"Output tokens used: {response.usage_metadata.candidates_token_count}") print(response.text)
Обратите внимание на использование temperature: 1.0, что является рекомендуемым значением по умолчанию для моделей Gemini 3. Документация Google особо предупреждает, что изменение temperature с 1.0 может вызвать «зацикливание или снижение производительности» на сложных задачах рассуждения — это отличается от предыдущих моделей, где для фактических ответов часто использовались более низкие значения temperature.
Node.js (Google AI JavaScript SDK)
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-pro-preview", generationConfig: { maxOutputTokens: 65536, temperature: 1.0, }, }); const result = await model.generateContent( "Generate a complete Node.js Express application with authentication, CRUD operations, and tests." ); console.log(`Tokens used: ${result.response.usageMetadata.candidatesTokenCount}`); console.log(result.response.text());
cURL (прямой REST API)
Для прямых HTTP-вызовов или при интеграции с языками без официального SDK REST API принимает maxOutputTokens в объекте generationConfig:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Write a complete Python data pipeline framework with error handling, logging, and tests."}] }], "generationConfig": { "maxOutputTokens": 65536, "temperature": 1.0 } }'
Google AI Studio
Если вы прототипируете в Google AI Studio, а не работаете с API напрямую, лимит выходных токенов настраивается в панели настроек справа. Нажмите на значок шестерёнки, найдите «Max output tokens» в настройках генерации и перетащите ползунок или введите значение 65536 напрямую. Эта настройка сохраняется для вашей сессии и применяется ко всем последующим промптам, пока вы её не измените.
Vertex AI
Для корпоративных развёртываний через Google Cloud Vertex AI настройка выполняется аналогично, но с использованием клиентской библиотеки Vertex AI:
pythonfrom google.cloud import aiplatform from vertexai.generative_models import GenerativeModel, GenerationConfig model = GenerativeModel("gemini-3.1-pro-preview") response = model.generate_content( "Your prompt here", generation_config=GenerationConfig( max_output_tokens=65536, temperature=1.0, ) )
Частая ошибка разработчиков — установка maxOutputTokens на значение выше 65 536, что возвращает ошибку 400 от API. Допустимый диапазон — от 1 до 65 537 (не включая верхнюю границу), поэтому 65 536 является потолком. Ещё одна распространённая ошибка — путаница между параметром maxOutputTokens и гарантией: установка значения 65 536 не означает, что модель всегда будет генерировать 65 536 токенов. Параметр задаёт верхнюю границу, и модель может сгенерировать меньше токенов, если определит, что ответ завершён. Для задач, где необходимо максимизировать длину вывода, промпт-инженерия важна не менее самой настройки: явно запрашивайте исчерпывающие, детальные ответы и указывайте желаемый формат и объём вывода.
Thinking-токены и их влияние на объём вывода

Один из наиболее недооценённых аспектов системы вывода Gemini 3.1 Pro — это взаимодействие между функцией мышления (reasoning) и бюджетом выходных токенов. Gemini 3.1 Pro представила расширенную систему мышления с четырьмя уровнями — minimal, low, medium и high — причём токены, потребляемые внутренним процессом рассуждения модели, вычитаются из вашего общего бюджета вывода. Это означает, что когда вы устанавливаете maxOutputTokens на 65 536, вы не обязательно получаете 65 536 токенов видимого контента. Фактический объём контента, который вы получите, зависит от того, сколько токенов модель потратит на свою внутреннюю цепочку рассуждений.
Параметр thinking_level управляет глубиной рассуждений, которые модель выполняет перед генерацией ответа. На уровне «high» (который используется по умолчанию) модель выделяет значительную часть бюджета вывода на внутренние рассуждения. Это отлично подходит для сложных задач — многоступенчатых математических доказательств, продуманных архитектурных решений в коде или глубокого аналитического текста, — но означает, что видимый вывод может быть значительно меньше максимума в 65 536 токенов. На уровне «minimal» модель выполняет минимальные внутренние рассуждения, что максимизирует количество токенов, доступных для фактического контента. Подробное руководство по уровням мышления Gemini, включая бенчмарки для каждого уровня, читайте в нашей специальной статье.
Вот как каждый уровень мышления приблизительно влияет на доступные токены для контента (на основе тестирования с промптами для генерации документов):
| Уровень мышления | Приблизительно thinking-токенов | Доступные токены контента | Лучше всего подходит для |
|---|---|---|---|
| minimal | ~1 000–3 000 | ~62 500–64 500 | Простое форматирование, перевод, резюмирование |
| low | ~5 000–10 000 | ~55 500–60 500 | Стандартная генерация контента, вопросы и ответы |
| medium | ~12 000–20 000 | ~45 500–53 500 | Техническое письмо, умеренные рассуждения |
| high (по умолчанию) | ~18 000–30 000 | ~35 500–47 500 | Сложное программирование, глубокий анализ, исследования |
Эти числа приблизительны, поскольку модель динамически распределяет thinking-токены в зависимости от сложности каждого конкретного промпта. Простая задача форматирования на уровне «high» может потреблять меньше thinking-токенов, чем сложное математическое доказательство на уровне «low». Система мышления по умолчанию динамична, то есть модель сама решает, сколько рассуждений требует каждый промпт, независимо от установленного вами уровня. Параметр thinking_level влияет на распределение, но не диктует его.
Практическое значение этого существенно для разработчиков, создающих системы генерации длинного контента. Если вы генерируете техническое руководство и вам нужен каждый возможный токен контента, установка thinking_level на «low» или «minimal» — правильный выбор. Задача генерации контента не требует глубокого многоступенчатого рассуждения, которое обеспечивает уровень «high», и вы возвращаете 15 000–25 000 токенов объёма вывода. И наоборот, если вы просите модель спроектировать сложную программную систему или решить трудную алгоритмическую задачу, thinking-токены, потраченные на уровне «high», напрямую улучшают качество более короткого вывода.
Уровень мышления можно настроить вместе с maxOutputTokens в одном API-вызове:
pythonresponse = model.generate_content( "Write a complete 40,000-word technical manual on Kubernetes deployment.", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, "thinking_level": "low", # Maximize content output } )
Thinking-токены не видны в тексте ответа модели — они потребляются внутренне и отображаются только в метаданных использования. Вы можете проверить, сколько токенов было использовано на мышление, а сколько — на контент, изучив объект usage_metadata ответа, который разбивает потребление токенов по категориям.
Сравнение вывода Gemini 3.1 Pro с конкурентами

Выбор правильной модели для генерации длинных текстов требует сравнения не только лимитов вывода, но и стоимостной эффективности, качества при большом количестве токенов и практической пропускной способности. По состоянию на февраль 2026 года ландшафт передовых моделей предлагает кардинально разные возможности вывода, и Gemini 3.1 Pro занимает особое место: она соответствует большинству конкурентов или превосходит их по чистому объёму вывода, сохраняя при этом значительно более низкую цену за токен.
Ниже приведено полное сравнение лимитов выходных токенов основных моделей ИИ, верифицированное по официальной документации на 20 февраля 2026 года:
| Модель | Макс. выходных токенов | Цена вывода (за 1M) | Стоимость макс. вывода | Контекстное окно |
|---|---|---|---|---|
| Gemini 3.1 Pro | 65 536 | $12,00 | $0,79 | 1M токенов |
| Gemini 3.0 Pro | 65 536 | $12,00 | $0,79 | 1M токенов |
| Gemini 3 Flash | 64 000 | $3,00 | $0,19 | 1M токенов |
| Gemini 2.5 Pro | 65 536 | $10,00 | $0,66 | 1M токенов |
| Claude Opus 4.6 | 32 000 | $75,00 | $2,40 | 200K токенов |
| Claude Sonnet 4.6 | 16 000 | $15,00 | $0,24 | 200K токенов |
| GPT-5.2 | 16 384 | $60,00 | $0,98 | 128K токенов |
Из этого сравнения вырисовывается ряд закономерностей. Модели Gemini доминируют в колонке объёма вывода: три разные модели (3.1 Pro, 3.0 Pro и 2.5 Pro) предлагают по 65 536 токенов. Это не случайно — Google последовательно инвестирует в возможности длинного вывода как конкурентное преимущество. Для сравнения: Claude Opus 4.6 ограничен 32 000 токенами (примерно вдвое меньше максимума Gemini), а GPT-5.2 — 16 384 токенами (примерно четверть).
Сравнение стоимостной эффективности не менее показательно. Генерация ответа максимальной длины с Gemini 3.1 Pro стоит $0,79, тогда как аналогичная операция с Claude Opus 4.6 обошлась бы в $2,40 при вдвое меньшем объёме токенов. GPT-5.2 стоит $0,98 за четверть объёма токенов. Для продакшн-нагрузок, требующих значительных объёмов вывода — таких как пакетная генерация документов, автоматизированное составление отчётов или конвейеры генерации кода, — разница в стоимости в масштабе становится колоссальной. Обработка 1 000 запросов с максимальным выводом обойдётся в $790 с Gemini 3.1 Pro против $2 400 с Claude Opus 4.6.
Однако чистый объём вывода — не единственный фактор. Claude Opus 4.6 демонстрирует немного более высокий результат на SWE-Bench Verified (80,8% против 80,6%), и некоторые разработчики отмечают, что предпочитают стиль его ответов для определённых типов прозы. GPT-5.2, несмотря на более низкий потолок вывода, превосходит конкурентов в определённых задачах со структурированным выводом и обладает зрелой экосистемой вызова функций. Правильный выбор зависит от вашего конкретного сценария: если максимальная длина вывода и стоимостная эффективность — главные требования, Gemini 3.1 Pro является очевидным лидером. Если вам нужно наивысшее качество рассуждений для более коротких ответов и бюджет не ограничен, Claude Opus 4.6 остаётся конкурентоспособной альтернативой.
Для разработчиков, которым необходим доступ к нескольким моделям через единый API-эндпоинт — переключение между Gemini для длинных ответов и Claude для специализированных задач — агрегаторные платформы, такие как laozhang.ai, предоставляют унифицированный интерфейс, упрощающий мультимодельные рабочие процессы без необходимости управлять отдельными API-ключами и биллинговыми аккаунтами для каждого провайдера.
Для более подробного сравнения Gemini 3.1 Pro и Claude Opus 4.6 по бенчмаркам, задачам программирования и реальным сценариям использования ознакомьтесь с нашим специальным анализом.
Стратегии оптимизации затрат при больших объёмах вывода
Генерация длинных ответов с Gemini 3.1 Pro — мощный инструмент, но затраты могут быстро накапливаться в продакшн-нагрузках. При стоимости $12 за миллион выходных токенов один ответ в 65 536 токенов стоит $0,79. Для приложений, обрабатывающих сотни или тысячи запросов ежедневно, понимание и оптимизация этих расходов — необходимость.
Первая и наиболее действенная стратегия оптимизации — правильный подбор параметра maxOutputTokens для каждого типа запросов. Многие разработчики устанавливают maxOutputTokens на 65 536 для всех запросов как «безопасное» значение по умолчанию, но это приводит к перерасходу средств, когда модель генерирует более короткие ответы, при этом тарифицируется фактический объём вывода. Более эффективный подход — классифицировать типы ваших запросов и назначить соответствующие лимиты: 8 192 для ответов чат-бота и кратких резюме, 16 384 для стандартной генерации контента, 32 768 для детальных технических документов и 65 536 только для задач, которые действительно требуют максимального объёма вывода.
Второй важный рычаг оптимизации — уровень мышления. Как обсуждалось в предыдущем разделе, более высокие уровни мышления потребляют больше выходных токенов внутренне, а значит, вы платите за thinking-токены, которые никогда не появляются в ответе. Для простых задач генерации — форматирования, перевода или шаблонного контента — установка thinking_level на «minimal» или «low» сокращает общее потребление токенов на 15 000–25 000 за запрос, потенциально экономя $0,18–$0,30 на каждый запрос. При тысячах ежедневных запросов это даёт существенную экономию.
Кэширование контекста — третья стратегия оптимизации, особенно ценная для приложений, которые многократно обрабатывают похожие промпты. Если вы генерируете несколько документов на основе одного шаблона, руководства по стилю или справочного материала, вы можете закэшировать общий контекст и платить всего $0,50 за миллион кэшированных входных токенов в час, вместо повторной отправки полного контекста с каждым запросом. Подробное описание этой техники читайте в нашем руководстве по кэшированию контекста для снижения затрат на API.
Batch API предоставляет четвёртую возможность сокращения затрат. Google предлагает 50%-ную скидку на все расходы за токены при отправке запросов через Batch API вместо API реального времени. Для нагрузок, где задержка не критична — например, ночная генерация документов, еженедельная компиляция отчётов или пакетные задания по переводу, — переход на Batch API снижает стоимость вывода с $12 до $6 за миллион токенов, уменьшая стоимость ответа максимального объёма примерно до $0,39.
Ниже приведена таблица сравнения затрат для типичных продакшн-сценариев, основанная на полном руководстве по тарифам Gemini API:
| Сценарий | Выходные токены | Стоимость в реальном времени | Стоимость Batch API | Месяц (1K запросов/день) |
|---|---|---|---|---|
| Ответ чат-бота | 2 000 | $0,024 | $0,012 | $720 / $360 |
| Блог-пост | 8 192 | $0,098 | $0,049 | $2 940 / $1 470 |
| Технический документ | 32 768 | $0,393 | $0,197 | $11 790 / $5 895 |
| Полное руководство | 65 536 | $0,786 | $0,393 | $23 580 / $11 790 |
Пятая стратегия — выбор подходящей модели внутри семейства Gemini. Gemini 3 Flash предлагает 64 000 выходных токенов всего за $3 за миллион — в четыре раза дешевле, чем Gemini 3.1 Pro. Для задач, требующих длинного вывода, но не наивысшей способности к рассуждению, — таких как простое расширение документов, перевод или конвертация форматов, — Flash обеспечивает сопоставимый объём вывода при значительно меньших затратах. Оставьте Gemini 3.1 Pro для задач, которые действительно выигрывают от превосходных рассуждений: сложного анализа, генерации качественного кода и многоступенчатого решения задач.
Практический рабочий процесс оптимизации затрат для продакшн-системы генерации документов может выглядеть так: сначала используйте Gemini 3.1 Pro с высоким уровнем мышления для генерации структуры и ключевых аналитических разделов (где качество рассуждений наиболее важно), затем переключитесь на Gemini 3 Flash с maxOutputTokens, установленным на 64 000, для расширения каждого раздела в полноценный текст (где объём вывода важнее глубины рассуждений). Такой гибридный подход может снизить общие затраты на 60–70% по сравнению с использованием Gemini 3.1 Pro для всего конвейера, сохраняя при этом высокое качество там, где это наиболее важно. Входные токены для каждого вызова Flash будут включать сгенерированную Pro структуру в качестве контекста, обеспечивая согласованность итогового документа.
Для команд, оценивающих совокупную стоимость владения, стоит помнить, что выходные токены обычно в 6 раз дороже входных для Gemini 3.1 Pro ($12 против $2 за миллион). Это означает, что нагрузки с длинным выводом непропорционально сильно зависят от стоимости вывода. Любая стратегия, сокращающая ненужный вывод — будь то более качественный промпт-инженеринг, избегающий повторяющегося контента, оптимизация уровня мышления или выбор модели, — оказывает непропорционально большое влияние на ваш счёт.
Устранение проблем с обрезкой вывода
Обрезка вывода — наиболее часто встречающаяся проблема при работе с большим объёмом вывода Gemini 3.1 Pro. Понимание типичных причин и способов их устранения экономит часы отладки и предотвращает разочарование при разработке продакшн-приложений. Ниже приведено систематическое руководство по диагностике и устранению обрезки вывода, основанное на наиболее распространённых паттернах, о которых сообщают в сообществе разработчиков и которые задокументированы на официальных форумах Google.
Значение maxOutputTokens по умолчанию равно 8 192, а не 65 536. Это наиболее частая причина неожиданной обрезки. Если вы не установили maxOutputTokens явно в generationConfig, каждый ответ будет ограничен примерно 6 000 словами, независимо от вашего промпта. Решение простое: всегда устанавливайте maxOutputTokens явно для любого запроса, где вы ожидаете длинный ответ. Как описано в руководстве по лимитам скорости Gemini API, лимиты по умолчанию применяются на каждом уровне тарификации, и повышение вашего биллингового уровня не меняет значение выходных токенов по умолчанию — вы должны настроить этот параметр самостоятельно.
Thinking-токены потребляют ваш бюджет вывода. При использовании уровня мышления «high» по умолчанию модель может выделить 20 000 и более токенов на внутренние рассуждения, оставляя только 40 000–45 000 токенов для видимого контента. Если вы ожидаете близко к 65 000 токенов контента, но получаете существенно меньше, проверьте, соответствует ли уровень мышления вашей задаче. Установка thinking_level: "low" для задач генерации контента может вернуть значительную часть бюджета вывода.
Модель определила, что ответ завершён. Установка maxOutputTokens на 65 536 не заставляет модель генерировать ровно столько токенов — это задаёт верхнюю границу. Если модель считает, что полностью ответила на ваш промпт за 30 000 токенов, она остановится на этом. Чтобы побудить модель генерировать более длинный вывод, будьте конкретны в промпте: укажите желаемое количество слов, запросите исчерпывающее освещение подтем или структурируйте промпт как план многосекционного документа, который естественным образом требует больше контента.
Ограничение скорости запросов обрезает ваш ответ. Если вы находитесь на бесплатном уровне или низком платном уровне, лимиты скорости могут приводить к досрочному завершению ответов в периоды высокого спроса. Бесплатный уровень Google налагает довольно строгие ограничения (5–15 RPM в зависимости от модели, с дневными лимитами запросов). Если вы наблюдаете постоянную обрезку в часы пик, но не вне пиковых часов, причиной, скорее всего, является ограничение скорости. Переход на Tier 1 (который начинается после $50 совокупных расходов) значительно увеличивает лимит RPM и снижает вероятность обрезки, связанной с высокой нагрузкой.
Сетевые таймауты обрывают длинные ответы. Генерация 65 536 токенов занимает значительное время — ранние тесты Саймона Уиллисона показали время ответа от 100 до 300+ секунд для сложных выводов. Если ваш HTTP-клиент, балансировщик нагрузки или прокси имеет таймаут по умолчанию меньше времени генерации ответа, соединение может закрыться до завершения ответа. Для выводов максимальной длины установите таймаут HTTP-клиента не менее 600 секунд (10 минут) и настройте соответствующим образом все промежуточные прокси.
Фильтры безопасности блокируют или обрезают контент. Фильтры безопасности Gemini могут обрезать ответы, содержащие контент, который система классифицирует как потенциально вредный, даже если контент является легитимным. Настройка безопасности по умолчанию — BLOCK_MEDIUM_AND_ABOVE, что подходит для большинства приложений, но может мешать генерации контента в таких областях, как медицинские тексты, юридический анализ или художественная литература с элементами конфликта. Вы можете настроить параметры безопасности для каждого запроса, но действуйте осмотрительно и ознакомьтесь с политикой допустимого использования Google.
Если вы проверили все вышеперечисленные причины и по-прежнему сталкиваетесь с обрезкой, изучите поле finishReason в ответе API. Значение finishReason равное STOP означает, что модель решила остановиться; MAX_TOKENS — что лимит вывода был достигнут; SAFETY — что контент был заблокирован; а OTHER указывает на непредвиденное завершение, которое может требовать повторного запроса.
Вот диагностический фрагмент кода, который проверяет все типичные причины обрезки:
pythonresponse = model.generate_content("Your prompt here") finish_reason = response.candidates[0].finish_reason print(f"Finish reason: {finish_reason}") # Check token usage metadata = response.usage_metadata print(f"Output tokens: {metadata.candidates_token_count}") print(f"Total tokens: {metadata.total_token_count}") # Diagnose truncation if finish_reason == "MAX_TOKENS": print("Output hit token limit - increase maxOutputTokens") elif finish_reason == "SAFETY": print("Safety filter triggered - review content or adjust settings") elif finish_reason == "STOP" and metadata.candidates_token_count < 1000: print("Model stopped early - improve prompt specificity")
Феномен «потери в середине» вызывает неполные ответы. При промптах с очень длинным входным контекстом (сотни тысяч токенов) модель может терять инструкции, размещённые в середине ввода. Собственная документация Google признаёт это ограничение. Обходной путь — размещать наиболее важные инструкции, включая требования к длине вывода и спецификации формата, как в начале, так и в конце промпта. Такое дублирование помогает модели сохранять фокус на ваших требованиях к выводу даже при обработке больших контекстных окон.
Начало работы с Gemini 3.1 Pro
Чтобы применить всё описанное в этом руководстве на практике, потребуется всего несколько минут настройки. Начните с получения API-ключа Gemini в Google AI Studio, где вы можете бесплатно экспериментировать с Gemini 3.1 Pro на бесплатном уровне. Бесплатный уровень предоставляет ограниченное количество запросов в минуту и в день, но его достаточно для тестирования и прототипирования настройки вывода перед переходом на платный план.
Вот минимальный код для начала работы с максимальным выводом Gemini 3.1 Pro:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3.1-pro-preview", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, "thinking_level": "low", # Maximize content output } ) response = model.generate_content("Your detailed prompt here") # Check token usage metadata = response.usage_metadata print(f"Input tokens: {metadata.prompt_token_count}") print(f"Output tokens: {metadata.candidates_token_count}") print(f"Total tokens: {metadata.total_token_count}")
Для продакшн-развёртываний запомните ключевые принципы из этого руководства. Всегда устанавливайте maxOutputTokens явно — никогда не полагайтесь на лимит по умолчанию в 8 192. Подбирайте thinking_level в соответствии со сложностью задачи, чтобы оптимизировать баланс между качеством рассуждений и длиной вывода. Используйте Batch API для нагрузок, не требующих работы в реальном времени, чтобы сократить затраты на 50%. Отслеживайте использование токенов через метаданные ответа для раннего обнаружения неожиданной обрезки. И рассмотрите API-агрегатор, такой как laozhang.ai, если вам нужен бесшовный доступ к Gemini наряду с Claude и GPT через единый эндпоинт — это особенно ценно, когда вы хотите направлять задачи с длинным выводом на Gemini, а специализированные задачи — на другие модели, не управляя несколькими API-интеграциями.
Model ID, который вам следует использовать: gemini-3.1-pro-preview для стандартной модели и gemini-3.1-pro-preview-customtools для улучшенной производительности вызова инструментов. Обе модели сейчас находятся в превью-режиме, что означает: Google может вносить изменения в поведение и возможности до выхода общедоступной версии. Учитывайте это при построении продакшн-систем — зафиксируйте версию модели и тщательно тестируйте перед обновлением. Также обратите внимание, что «thought signatures» обязательны для многоходовых диалогов с вызовом функций: зашифрованный контекст рассуждений должен передаваться обратно в последующих ходах, и отсутствие подписей приведёт к ошибке 400.
Возможность вывода в 64K токенов Gemini 3.1 Pro представляет собой подлинный шаг вперёд для генерации длинного контента с помощью ИИ. Модель не просто производит больше токенов — она производит более качественные токены, с улучшениями бенчмарков до 77,1% на ARC-AGI-2 для рассуждений, 80,6% на SWE-Bench для задач программирования и Elo 2 887 в соревновательном программировании. Создаёте ли вы конвейеры генерации документов, автоматизированных помощников по программированию или исследовательские инструменты, требующие исчерпывающего вывода, — настройка и оптимизация лимита вывода является фундаментом для извлечения максимальной ценности из этой модели.