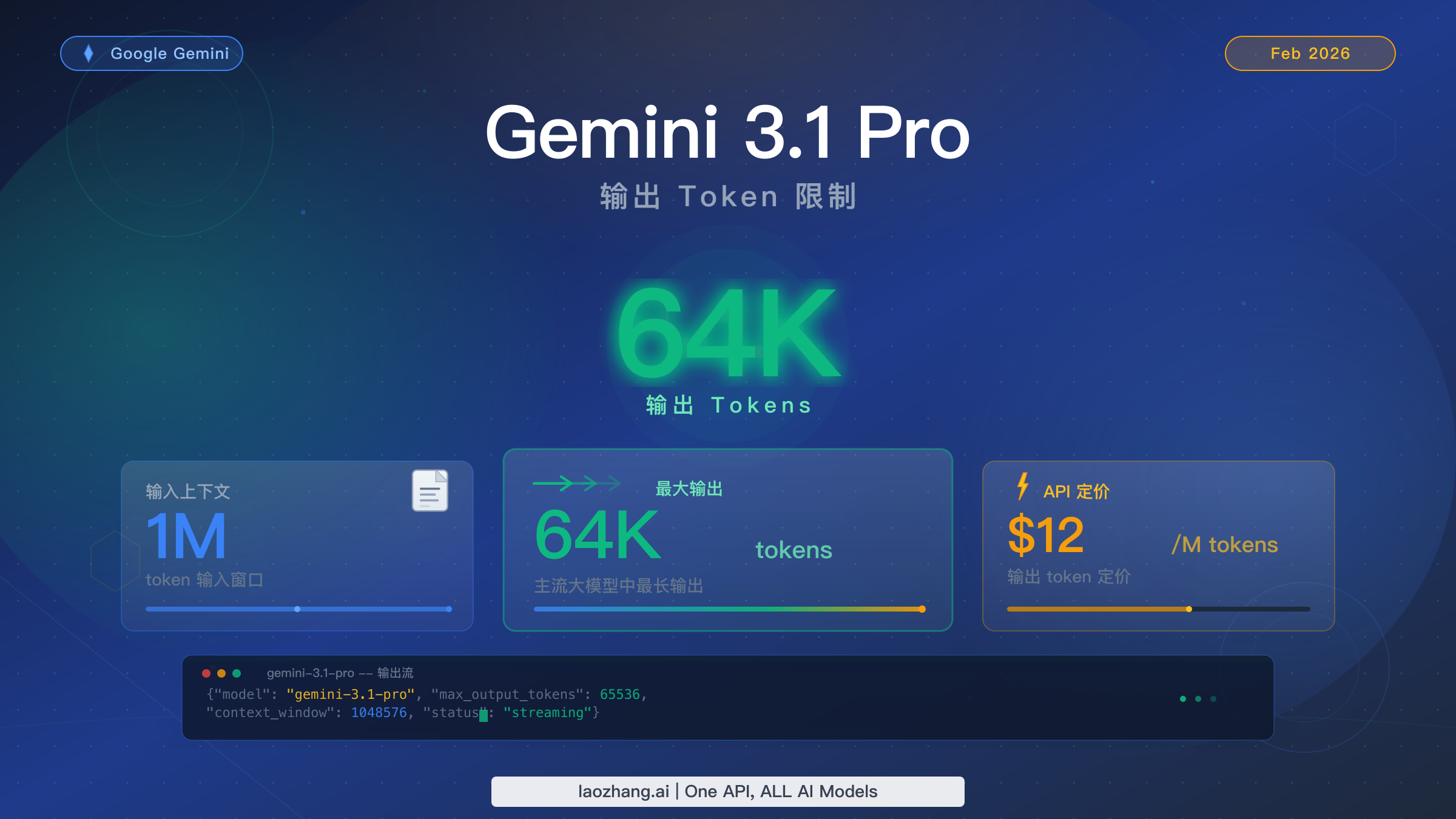
Gemini 3.1 Pro 每次 API 响应最多支持 65,536 个输出 token,大约相当于 49,000 个英文单词或 98 页文本。该模型于 2026 年 2 月 19 日发布,配备 100 万 token 的输入上下文窗口,是目前所有前沿 AI 模型中输出容量最大的之一。然而,大多数指南都忽略了一个关键细节:maxOutputTokens 的默认值仅为 8,192——开发者必须显式配置这个参数才能解锁完整的 64K 输出能力。按 Google AI Developer API 2026 年 2 月的定价,每百万输出 token 收费 12 美元,生成一次最大长度的响应大约花费 0.78 美元。
Gemini 3.1 Pro 的输出限制是多少?
要准确理解 Gemini 3.1 Pro 的输出规格,需要先理清文档和媒体报道中的一些混乱信息。不同的来源引用了略有差异的数字——64K、65K 或 65,536——而这些区别在配置生产环境的 API 调用时确实有影响。Google AI 开发者官方文档将 Gemini 3 模型系列的输出容量描述为"1M / 64k"的输入输出配对,而 API 本身接受的 maxOutputTokens 值范围是 1 到 65,537(不含),也就是说你实际能设置的最大值是 65,536 个 token。
65,536 这个数字之所以重要,是因为它等于 2^16,是计算机系统中一个自然的边界值。当 Google 宣传该模型拥有"64K 输出"时,他们只是将 65,536 四舍五入到最近的千位来简化表述。两种说法指的是同一个底层能力,你在设置 maxOutputTokens 参数时应始终使用精确值 65,536,以获取所有可用的 token。
以下是基于 Google 官方文档的 Gemini 3.1 Pro 完整规格表(ai.google.dev,2026 年 2 月 20 日验证):
| 规格参数 | Gemini 3.1 Pro | Gemini 3.0 Pro | 变化 |
|---|---|---|---|
| 输入上下文窗口 | 1,000,000 tokens | 1,000,000 tokens | 不变 |
| 最大输出 token 数 | 65,536 tokens | 65,536 tokens | 上限不变 |
| 默认 maxOutputTokens | 8,192 tokens | 8,192 tokens | 默认值不变 |
| 知识截止日期 | 2025 年 1 月 | 2025 年 1 月 | 不变 |
| 文件上传限制 | 100 MB | 20 MB | 提升 5 倍 |
| 思考级别 | minimal、low、medium、high | low、high | 新增 2 个级别 |
| 模型 ID | gemini-3.1-pro-preview | gemini-3-pro-preview | 已更新 |
这张表中最重要的信息是最大输出(65,536)与默认输出(8,192)之间的差距。这个 8 倍的差异是大多数开发者遇到输出截断问题的根本原因。如果你在调用 Gemini 3.1 Pro API 时没有显式设置 maxOutputTokens,无论你在提示词中请求多少内容,响应都会被限制在大约 6,000 个单词以内。
Gemini 3.1 Pro 还引入了超越输出限制本身的多项重大改进。该模型在 ARC-AGI-2 上取得了 77.1% 的分数(Gemini 3.0 Pro 为 31.1%),在 SWE-Bench Verified 上的智能编程得分为 80.6%,在 LiveCodeBench Pro 上的 Elo 评分达到 2,887。这些基准测试的提升意味着,在你 64K 的输出预算内生成的内容质量将显著高于上一代模型,特别是在复杂推理和代码生成任务方面。
同样值得注意的是 Gemini 3.0 Pro 和 3.1 Pro 之间没有变化的部分。输出上限仍为 65,536 个 token——Google 在此次发布中并未提高最大输出容量。定价也保持一致:对于输入 token 不超过 200,000 的请求,每百万输入 token 收费 2 美元,每百万输出 token 收费 12 美元;对于输入在 200,000 到 1,000,000 之间的请求,价格为 4 美元/18 美元(Google AI Developer API 定价页面,2026 年 2 月 20 日验证)。真正显著变化的是推理质量、编码能力和智能体性能,这意味着已经在使用 Gemini 3 Pro 64K 输出的开发者只需切换到 3.1 Pro 模型 ID,就能从相同的输出预算中获得明显更好的结果。新的 customtools 端点变体(gemini-3.1-pro-preview-customtools)还为构建智能体工作流的开发者提供了更好的工具调用性能,尤其适用于生成长结构化输出的场景。
64K 输出 token 在实际应用中意味着什么
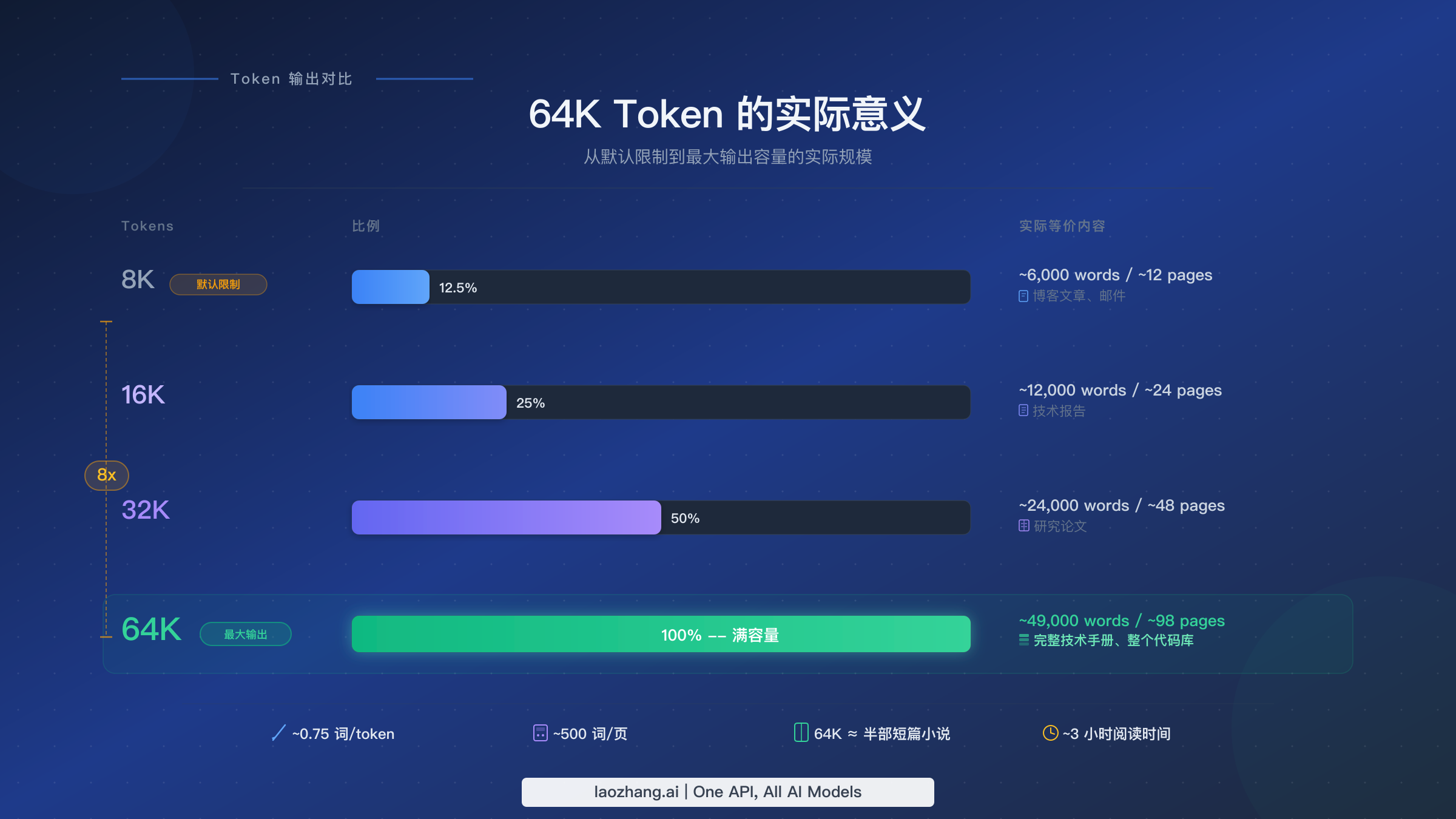
在深入 API 配置之前,有必要先了解 65,536 个输出 token 在现实中究竟代表什么。token 数量不能直接等同于单词数量,因为分词器会根据语言和内容类型以不同方式分割文本。对于标准英文散文,Gemini 分词器大约每 0.75 个单词产生 1 个 token,这意味着 65,536 个 token 大约相当于 49,000 个单词。对于代码,比例有所不同——编程语言由于特殊字符、运算符和语法元素的存在,每行往往消耗更多 token,因此你通常能获得大约 40,000 到 45,000 个等效单词的代码量。
为了更直观地理解这些数字,我们来看看在不同输出规模下,单次 API 调用能生成什么。在默认的 8,192 token 限制下,你的输出大约是 6,000 个单词——足够写一篇完整的博客文章或一份简短的技术文档,但仅此而已。在 16,384 token 时,翻倍到大约 12,000 个单词,可以覆盖一份详细的技术报告或一篇包含代码示例的全面教程。在 32,768 token 时,你能达到大约 24,000 个单词,相当于一篇长篇研究论文或一本电子书的某个章节。而在完整的 65,536 token 限制下,你可以生成大约 49,000 个单词——相当于一本完整的技术手册、一整个学期的讲义,或者一个包含完整文档的多模块 Python 应用程序。
对于那些在单次生成中能产生更好效果的特定场景来说,这个规模极为重要。当你把一份长文档拆分成多次 API 调用时,你会丢失各部分之间的上下文连贯性,可能在术语或风格上引入不一致,还会增加应用程序编排层的复杂度。64K 输出限制为大多数长篇生成任务消除了这些问题。
以下是 Gemini 3.1 Pro 完整输出能力最具价值的使用场景。技术文档生成从中受益巨大,因为 API 参考文档、用户指南和集成手册需要一致的格式和交叉引用,而这些在跨调用拆分时会出现问题。中小型应用程序的完整代码库生成——比如完整的 CRUD API、CLI 工具或数据管道——可以在单次连贯的响应中完成,而不需要逐函数生成。法律和合规文件起草中,语言的一致性具有法律意义,因此受益于单次生成。学术论文和研究报告写作中,论点必须在数千字的篇幅中逻辑性地层层递进,也因扩展的输出窗口而获得更好的连贯性。长文档翻译中,前面段落的上下文会影响后续的翻译选择,在大输出预算下效果会显著提升。
对于构建生产应用的开发者来说,实用的经验法则很简单:如果你预期的输出在 6,000 个单词以下,默认的 8,192 token 限制就够用了。如果你需要 6,000 到 25,000 个单词之间的输出,将 maxOutputTokens 设为 32,768。如果你需要最大输出容量来进行文档级别的生成,将其设为 65,536,同时接受相应的延迟和成本代价。
还有一个重要的考量因素是 Gemini 如何对不同类型的内容进行分词。英文文本平均每 0.75 个单词约 1 个 token,但 JSON、XML 或包含大量注释的代码等结构化内容可能会显著增加 token 消耗。一个包含文档字符串、类型注解和行内注释的 10,000 行 Python 代码库,作为输出可能会消耗 80,000 到 100,000 个 token,超出 65,536 的限制。对于这种情况,你需要将生成请求组织为可管理的分块——例如逐模块生成而非尝试在一次调用中生成整个代码库。同样,中文、日文和韩文等语言的 token 消耗方式与英文不同,大约每 0.6 到 0.7 个字符消耗 1 个 token,这意味着亚洲语言生成的有效单词等效输出更短。
如何在 API 中配置 maxOutputTokens
解锁 Gemini 3.1 Pro 完整输出能力最重要的配置步骤就是显式设置 maxOutputTokens 参数。如果不进行此设置,无论提示词如何要求,每次 API 调用都会默认限制在 8,192 个 token。以下是在各主要接入方式中配置该参数的方法。
Python(google-generativeai SDK)
Google AI Python SDK 提供了最直接的配置方式。你可以在创建模型或调用 generate_content 时,通过 generation_config 参数设置 maxOutputTokens:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3.1-pro-preview", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, } ) response = model.generate_content( "Write a comprehensive technical manual for building REST APIs with Python FastAPI." ) print(f"Output tokens used: {response.usage_metadata.candidates_token_count}") print(response.text)
注意这里使用了 temperature: 1.0,这是 Gemini 3 系列模型推荐的默认值。Google 的文档特别警告,将温度从 1.0 调整可能会导致复杂推理任务中出现"循环或性能下降"——这与早期模型中常用较低温度获取事实性输出的做法有所不同。
Node.js(Google AI JavaScript SDK)
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-pro-preview", generationConfig: { maxOutputTokens: 65536, temperature: 1.0, }, }); const result = await model.generateContent( "Generate a complete Node.js Express application with authentication, CRUD operations, and tests." ); console.log(`Tokens used: ${result.response.usageMetadata.candidatesTokenCount}`); console.log(result.response.text());
cURL(直接调用 REST API)
对于直接 HTTP 调用或没有官方 SDK 的语言集成场景,REST API 在 generationConfig 对象中接受 maxOutputTokens 参数:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Write a complete Python data pipeline framework with error handling, logging, and tests."}] }], "generationConfig": { "maxOutputTokens": 65536, "temperature": 1.0 } }'
Google AI Studio
如果你是在 Google AI Studio 中进行原型开发而非直接编写 API 代码,输出 token 限制可在右侧设置面板中配置。点击齿轮图标,在生成设置下找到"Max output tokens",然后拖动滑块或直接输入 65536。此设置会在你的会话期间保持不变,并应用于后续所有提示,直到你重新修改。
Vertex AI
对于通过 Google Cloud 的 Vertex AI 进行企业级部署,配置方式遵循相同的模式,但使用 Vertex AI 客户端库:
pythonfrom google.cloud import aiplatform from vertexai.generative_models import GenerativeModel, GenerationConfig model = GenerativeModel("gemini-3.1-pro-preview") response = model.generate_content( "Your prompt here", generation_config=GenerationConfig( max_output_tokens=65536, temperature=1.0, ) )
开发者常犯的一个错误是将 maxOutputTokens 设为超过 65,536 的值,这会导致 API 返回 400 错误。有效范围是 1 到 65,537(不含),所以 65,536 就是上限。另一个常见的误解是把 maxOutputTokens 当作保证值——将其设为 65,536 并不意味着模型每次都会生成 65,536 个 token。该参数只是设定了上限,如果模型判断响应已经完整,可能会在较少的 token 数处停止。对于需要最大化输出长度的任务,你的提示词工程与配置同样重要:明确要求全面、详细的回复,并指定期望的输出格式和长度。
理解思考 token 及其对输出的影响

Gemini 3.1 Pro 输出系统中最容易被忽视的一个方面是思考(推理)能力与输出 token 预算之间的互动关系。Gemini 3.1 Pro 引入了扩展的思考系统,包含四个级别——minimal、low、medium 和 high——而模型内部推理过程消耗的 token 会从你的总输出预算中扣除。这意味着当你将 maxOutputTokens 设为 65,536 时,你不一定能获得 65,536 个 token 的可见内容。实际收到的内容量取决于模型在内部推理链上花费了多少 token。
thinking_level 参数控制模型在生成响应之前执行的推理深度。在"high"级别(默认值)下,模型会将输出预算的很大一部分分配给内部推理。这对于复杂任务——如多步骤数学证明、复杂的代码架构决策或细致的分析性写作——非常有利,但也意味着你的可见输出可能会大大低于 65,536 token 的最大值。在"minimal"级别下,模型执行最少的内部推理,最大化用于实际内容输出的 token 数量。关于 Gemini 思考级别的详细指南,包括每个级别的基准测试结果,请参阅我们的专题文章。
以下是每个思考级别大致如何影响你的可用内容 token 数(基于文档生成提示的测试结果):
| 思考级别 | 大约思考 token 消耗 | 可用内容 token | 最适合场景 |
|---|---|---|---|
| minimal | ~1,000–3,000 | ~62,500–64,500 | 简单格式化、翻译、摘要 |
| low | ~5,000–10,000 | ~55,500–60,500 | 标准内容生成、问答 |
| medium | ~12,000–20,000 | ~45,500–53,500 | 技术写作、中等推理 |
| high(默认) | ~18,000–30,000 | ~35,500–47,500 | 复杂编码、深度分析、研究 |
这些数字是近似值,因为模型会根据每个具体提示的复杂度动态分配思考 token。一个使用"high"思考级别的简单格式化任务可能消耗的思考 token 反而比使用"low"级别的复杂数学证明更少。思考系统默认是动态的,意味着无论你设置什么级别,模型都会自行决定每个提示需要多少推理。thinking_level 参数是一种影响而非决定分配的方式。
这对构建长篇内容生成系统的开发者有重要的实践意义。如果你正在生成技术手册并且需要尽可能多的内容 token,将 thinking_level 设为"low"或"minimal"是正确的选择——内容生成任务并不需要"high"所启用的深度多步骤推理,而你可以回收 15,000 到 25,000 个 token 的输出容量。相反,如果你要求模型设计复杂的软件系统架构或解决困难的算法问题,在"high"级别花费的思考 token 能直接提升你获得的较短输出的质量。
你可以在同一次 API 调用中同时配置思考级别和 maxOutputTokens:
pythonresponse = model.generate_content( "Write a complete 40,000-word technical manual on Kubernetes deployment.", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, "thinking_level": "low", # Maximize content output } )
思考 token 不会出现在模型的响应文本中——它们在内部消耗,仅出现在使用量元数据中。你可以通过检查响应的 usage_metadata 对象来查看有多少 token 用于思考、多少用于内容,该对象按类别细分了 token 消耗情况。
Gemini 3.1 Pro 与竞品输出能力对比
为长篇生成选择合适的模型,不仅需要比较输出限制,还需要考量成本效率、高 token 数量下的质量以及实际吞吐量。截至 2026 年 2 月,前沿模型市场在输出能力上呈现出巨大差异,Gemini 3.1 Pro 占据了一个独特的位置:它在原始输出容量上追平或超越了大多数竞品,同时保持着显著更低的每 token 定价。
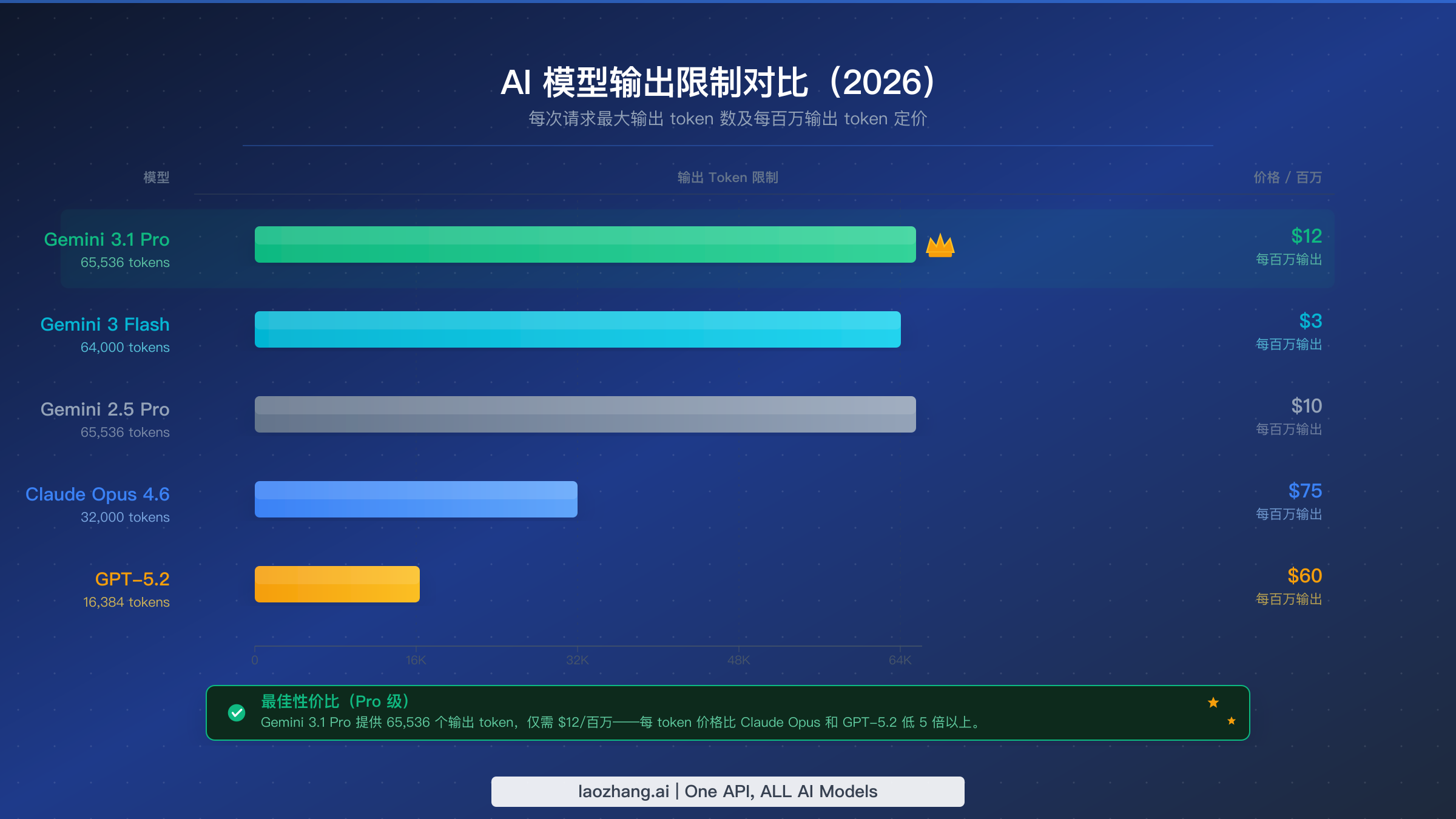
以下是各主要 AI 模型输出 token 限制的全面对比,数据来自 2026 年 2 月 20 日各官方文档验证:
| 模型 | 最大输出 token | 输出价格(每百万) | 最大输出成本 | 上下文窗口 |
|---|---|---|---|---|
| Gemini 3.1 Pro | 65,536 | $12.00 | $0.79 | 1M tokens |
| Gemini 3.0 Pro | 65,536 | $12.00 | $0.79 | 1M tokens |
| Gemini 3 Flash | 64,000 | $3.00 | $0.19 | 1M tokens |
| Gemini 2.5 Pro | 65,536 | $10.00 | $0.66 | 1M tokens |
| Claude Opus 4.6 | 32,000 | $75.00 | $2.40 | 200K tokens |
| Claude Sonnet 4.6 | 16,000 | $15.00 | $0.24 | 200K tokens |
| GPT-5.2 | 16,384 | $60.00 | $0.98 | 128K tokens |
从这个对比中可以看出几个明显的趋势。Gemini 系列在输出容量上占据主导地位,三个不同的模型(3.1 Pro、3.0 Pro 和 2.5 Pro)都提供 65,536 个 token。这并非巧合——Google 一直将长输出能力作为差异化的投资方向。相比之下,Claude Opus 4.6 上限为 32,000 个 token(大约是 Gemini 最大值的一半),而 GPT-5.2 限制在 16,384 个 token(大约是四分之一)。
成本效率的对比同样引人注目。使用 Gemini 3.1 Pro 生成一次最大长度的响应花费 0.79 美元,而使用 Claude Opus 4.6 同样的操作只能获得一半的 token 却要花费 2.40 美元。GPT-5.2 花费 0.98 美元却只能获得四分之一的 token。对于需要大量输出的生产工作负载——例如批量文档生成、自动化报告撰写或代码生成流水线——大规模下的成本差异将是巨大的。处理 1,000 次最大输出请求,Gemini 3.1 Pro 的成本为 790 美元,而 Claude Opus 4.6 则为 2,400 美元。
然而,原始输出容量并非唯一因素。Claude Opus 4.6 在 SWE-Bench Verified 上取得了略微更高的分数(80.8% vs. 80.6%),一些开发者也表示在某些类型的散文写作中更偏好其输出风格。GPT-5.2 尽管输出上限较低,但在特定的结构化输出任务上表现出色,并且拥有成熟的函数调用生态系统。正确的选择取决于你的具体使用场景:如果最大输出长度和成本效率是首要需求,Gemini 3.1 Pro 是明确的领先者。如果你需要更高的推理质量来处理较短输出且预算不受限制,Claude Opus 4.6 仍具竞争力。
对于需要通过单一 API 端点访问多个模型的开发者——在长输出任务中使用 Gemini、在专业任务中切换到 Claude——像 laozhang.ai 这样的聚合平台提供了统一接口,简化了多模型工作流,无需为每个提供商分别管理 API 密钥和账单。
如需了解更详细的 Gemini 3.1 Pro 与 Claude Opus 4.6 的全方位对比,包括基准测试、编码任务和实际使用场景的分析,请参阅我们的专题文章。
大输出场景下的成本优化策略
使用 Gemini 3.1 Pro 生成长输出功能强大,但在生产工作负载中成本可能会快速累积。按每百万输出 token 12 美元计算,单次 65,536 token 的响应成本为 0.79 美元。对于每天处理数百甚至数千个请求的应用来说,理解和优化这些成本至关重要。
第一个也是影响最大的优化策略是为每种请求类型合理设定 maxOutputTokens 参数。许多开发者将所有请求的 maxOutputTokens 都设为 65,536 作为"安全"默认值,但当模型生成较短的响应时,这样做会浪费预算,因为账单会按实际输出的全部 token 计费。更高效的做法是对请求类型进行分类并分配适当的限制:聊天机器人响应和快速摘要用 8,192,标准内容生成用 16,384,详细技术文档用 32,768,只有真正需要最大输出容量的任务才用 65,536。
第二个主要优化杠杆是思考级别。如前文所述,更高的思考级别会在内部消耗更多输出 token,这意味着你为从未出现在响应中的推理 token 付费了。对于格式化、翻译或模板化内容等简单生成任务,将 thinking_level 设为"minimal"或"low"可以将每次请求消耗的总 token 减少 15,000 到 25,000 个,每次请求潜在节省 0.18 到 0.30 美元。在每天数千次请求的规模下,这笔节省相当可观。
上下文缓存是第三种优化策略,对于反复处理相似提示的应用尤其有价值。如果你基于相同的模板、风格指南或参考材料生成多份文档,可以缓存共享上下文,每小时每百万缓存输入 token 仅需 0.50 美元,而无需每次请求都重新发送完整上下文。关于此技术的完整操作指南,请参阅我们的上下文缓存降低 API 成本指南。
Batch API 提供了第四种成本降低机会。Google 通过 Batch API 提交请求时,所有 token 成本享受 50% 的折扣。对于延迟不敏感的工作负载——如隔夜文档生成、每周报告汇编或批量翻译任务——切换到 Batch API 可将输出成本从每百万 token 12 美元降至 6 美元,使一次最大输出响应的成本降至约 0.39 美元。
以下是常见生产场景的成本对比表,基于完整的 Gemini API 定价指南:
| 场景 | 输出 token 数 | 实时 API 成本 | Batch API 成本 | 月费(每天 1K 请求) |
|---|---|---|---|---|
| 聊天回复 | 2,000 | $0.024 | $0.012 | $720 / $360 |
| 博客文章 | 8,192 | $0.098 | $0.049 | $2,940 / $1,470 |
| 技术文档 | 32,768 | $0.393 | $0.197 | $11,790 / $5,895 |
| 完整手册 | 65,536 | $0.786 | $0.393 | $23,580 / $11,790 |
第五种策略是在 Gemini 系列中选择合适的模型。Gemini 3 Flash 提供 64,000 个输出 token,每百万仅需 3 美元——比 Gemini 3.1 Pro 便宜四倍。对于需要长输出但不需要最高推理能力的任务,如简单的文档扩展、翻译或格式转换,Flash 以极低的成本提供了相当的输出长度。将 Gemini 3.1 Pro 保留给真正受益于其卓越推理能力的任务:复杂分析、精密代码生成和多步骤问题求解。
一个实用的成本优化工作流可能是这样的:首先使用 Gemini 3.1 Pro 配合 high 思考级别生成大纲和关键分析章节(推理质量最重要的地方),然后切换到 Gemini 3 Flash 并将 maxOutputTokens 设为 64,000 来扩展每个章节为完整的文本(输出量比推理深度更重要的地方)。这种混合方式相比全程使用 Gemini 3.1 Pro 可以将总成本降低 60-70%,同时在关键环节保持高质量。每次 Flash 调用的输入 token 将包含 Pro 生成的大纲作为上下文,确保最终文档的一致性。
对于评估总体拥有成本的团队来说,请记住 Gemini 3.1 Pro 的输出 token 通常比输入 token 贵 6 倍(每百万 12 美元 vs 2 美元)。这意味着长输出工作负载受输出定价的影响不成比例地大。任何减少不必要输出的策略——无论是通过更好的提示词工程避免重复内容、优化思考级别,还是合理选择模型——都会对你的账单产生超大的影响。
输出截断故障排查与常见问题
输出截断是使用 Gemini 3.1 Pro 大输出能力时最常被报告的问题。理解常见原因及其修复方法可以节省数小时的调试时间,避免在构建生产应用时的挫折感。以下是根据开发者社区中最常见的模式以及 Google 官方论坛中的文档整理的系统性诊断和解决指南。
默认 maxOutputTokens 是 8,192 而非 65,536。 这是导致意外截断最常见的原因。如果你没有在 generationConfig 中显式设置 maxOutputTokens,无论提示词如何要求,每次响应都会被限制在大约 6,000 个单词。修复方法很简单:对任何期望长响应的请求都显式设置 maxOutputTokens。正如 Gemini API 速率限制指南中所述,默认限制适用于所有计费层级,升级计费层级并不会改变默认输出 token 数——你必须始终自行配置此参数。
思考 token 正在消耗你的输出预算。 使用默认的"high"思考级别时,模型可能将 20,000 或更多 token 分配给内部推理,只留下 40,000 至 45,000 个 token 给可见内容。如果你期望接近 65,000 个 token 的内容却收到明显更少的输出,请检查思考级别是否适合当前任务。对于内容生成任务,将 thinking_level 设为"low"可以回收输出预算的很大一部分。
模型判定响应已经完整。 将 maxOutputTokens 设为 65,536 并不会强制模型生成那么多 token——它只是设定了上限。如果模型认为用 30,000 个 token 就已经完全回答了你的提示,它就会在那里停止。要鼓励更长的输出,你需要在提示词中明确:指定期望的字数,要求全面覆盖各子主题,或者将提示词构建为一个多章节的文档大纲,这种结构自然需要更多内容。
速率限制正在截断你的响应。 如果你在免费层级或低付费层级,速率限制可能会在高需求时段导致响应提前终止。Google 的免费层级施加了相对严格的限制(根据模型不同为 5-15 RPM,并有每日请求上限)。如果你在高峰时段持续遇到截断但非高峰时段没有,速率限制很可能就是原因。升级到 Tier 1(累计消费 50 美元后开始)会显著增加你的 RPM 配额,降低因需求导致截断的可能性。
网络超时正在切断长响应。 生成 65,536 个 token 需要相当长的时间——Simon Willison 的早期测试报告显示复杂输出的响应时间在 100 到 300 秒以上。如果你的 HTTP 客户端、负载均衡器或代理的默认超时时间短于响应生成时间,连接可能会在响应完成之前关闭。对于最大长度的输出,请将 HTTP 客户端超时设置为至少 600 秒(10 分钟),并相应配置所有中间代理。
安全过滤器正在屏蔽或截断内容。 Gemini 的安全过滤器可能会截断系统判定为潜在有害的内容,即使该内容是合理的。默认安全设置为 BLOCK_MEDIUM_AND_ABOVE,适用于大多数应用场景,但可能会干扰医学写作、法律分析或包含冲突情节的小说等领域的内容生成。你可以按请求调整安全设置,但请谨慎操作并查阅 Google 的可接受使用政策。
如果你已验证了以上所有情况仍然遇到截断,请检查 API 响应中的 finishReason 字段。finishReason 为 STOP 表示模型主动停止,MAX_TOKENS 表示达到了输出限制,SAFETY 表示内容被安全系统屏蔽,OTHER 表示意外终止,可能需要重试。
以下是一段检查所有常见截断原因的诊断代码:
pythonresponse = model.generate_content("Your prompt here") finish_reason = response.candidates[0].finish_reason print(f"Finish reason: {finish_reason}") # Check token usage metadata = response.usage_metadata print(f"Output tokens: {metadata.candidates_token_count}") print(f"Total tokens: {metadata.total_token_count}") # Diagnose truncation if finish_reason == "MAX_TOKENS": print("Output hit token limit - increase maxOutputTokens") elif finish_reason == "SAFETY": print("Safety filter triggered - review content or adjust settings") elif finish_reason == "STOP" and metadata.candidates_token_count < 1000: print("Model stopped early - improve prompt specificity")
"中间遗忘"现象导致输出不完整。 对于输入上下文非常长的提示(数十万 token),模型可能会忘记放在输入中间位置的指令。Google 自己的文档也承认了这一局限性。解决方法是将你最关键的指令——包括输出长度要求和格式规范——同时放在提示的开头和结尾。这种冗余设计有助于模型在处理大上下文窗口时仍然关注你的输出要求。
开始使用 Gemini 3.1 Pro
将本指南中的所有内容付诸实践只需几分钟的设置。首先从 Google AI Studio 获取 Gemini API 密钥,你可以在免费层级零成本体验 Gemini 3.1 Pro。免费层级每分钟和每天的请求数有限制,但足以在付费计划之前测试和验证你的输出配置。
以下是使用 Gemini 3.1 Pro 获取最大输出的最简代码:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3.1-pro-preview", generation_config={ "max_output_tokens": 65536, "temperature": 1.0, "thinking_level": "low", # Maximize content output } ) response = model.generate_content("Your detailed prompt here") # Check token usage metadata = response.usage_metadata print(f"Input tokens: {metadata.prompt_token_count}") print(f"Output tokens: {metadata.candidates_token_count}") print(f"Total tokens: {metadata.total_token_count}")
在生产部署中,请牢记本指南中的关键原则。始终显式设置 maxOutputTokens——永远不要依赖默认的 8,192 限制。根据任务复杂度匹配 thinking_level,以优化推理质量和输出长度之间的平衡。对于非实时工作负载使用 Batch API 以节省 50% 的成本。通过响应元数据监控 token 使用情况,以便尽早发现意外截断。如果你需要通过统一端点无缝访问 Gemini 以及 Claude 和 GPT 模型,可以考虑使用 laozhang.ai 这样的 API 聚合器——当你希望将长输出任务路由到 Gemini、将专业任务路由到其他模型而无需管理多个 API 集成时,这尤其有价值。
你应该使用的模型 ID 是标准模型的 gemini-3.1-pro-preview 和增强工具调用性能的 gemini-3.1-pro-preview-customtools。两者目前均处于预览阶段,意味着 Google 可能在正式发布前对行为和功能进行调整。在构建生产系统时请记住这一点——锁定模型版本并在升级前进行充分测试。还需要注意的是,多轮对话中的函数调用需要"thought signatures":加密的推理上下文必须在后续轮次中回传,缺少签名将导致 400 错误。
Gemini 3.1 Pro 的 64K 输出能力代表了 AI 驱动长篇内容生成的真正进步。这个模型不仅产出更多 token——它产出更好的 token,在 ARC-AGI-2 推理上提升至 77.1%,在 SWE-Bench 编码任务上达到 80.6%,在竞技编程上获得 Elo 2,887 的评分。无论你是在构建文档生成流水线、自动化编码助手,还是需要全面输出的研究工具,配置和优化输出限制都是从这个模型中获取最大价值的基础。