先说结论:截至 2026 年 3 月 18 日,Gemini Developer API 仍然有免费额度。 Google 在官方 Gemini API quickstart 里依然写着可以免费创建 API key,官方 pricing 页面 里也仍然能看到 Gemini 2.5 Pro、2.5 Flash、2.5 Flash-Lite 的标准调用处于 free of charge 状态。真正变掉的不是“有没有免费额度”,而是 Google 不再像旧教程那样,在公开页面上给出一张可以直接当成当前完整免费配额表使用的矩阵。
现在更可靠的理解方式是两层:第一层看公开文档,确认哪些规则、哪些条款、哪些计费状态依旧明确;第二层去 AI Studio 看你项目此刻的实际限额。很多 2025 年末和 2026 年初的文章,把旧的 RPM、TPM、RPD 数字当成恒定真相,这正是开发者后来频繁踩坑的原因。本文的重点不是再抄一遍旧表,而是把 今天仍然能公开确认的事实、今天必须去 AI Studio 确认的实时配额、以及 429 到底怎么判断 讲清楚。
要点速览
Gemini API 免费额度在 2026 年 3 月依然存在,但你最好把它理解成“公开规则 + 实时项目状态”的组合,而不是一张静态配额截图。公开文档今天仍然明确写出的,是:可以免费创建 key、限额按 project 计算、RPD 在太平洋时间午夜重置、免费与付费 tier 的升级门槛、以及 Gemini 2.5 主要文本模型仍然标记为免费标准调用。今天公开文档没有继续明确承诺的,则是“每个项目、每个模型、每个时间点都固定不变的完整免费矩阵”。
这也是为什么很多旧文章会让你越看越迷糊。你在搜索结果里仍然会看到 5 RPM、10 RPM、15 RPM、100 RPD、500 RPD、1000 RPD 之类的数字。它们并不一定完全错误,很多都曾经来自旧文档、社区回复或旧时段的项目状态,但今天的公开 rate limits 页面 已经把“你的当前活跃限额”引导到 AI Studio 查看,同时还写明 actual capacity may vary。也就是说,公开文档更像规则说明书,AI Studio 才是你项目当前限额的仪表盘。
| 问题 | 2026-03-18 的安全答案 |
|---|---|
| Gemini API 现在还有免费额度吗? | 有。Google 仍允许免费创建 key,也仍在 pricing 页面上保留 2.5 主要模型的免费标准调用状态。 |
| 在哪里看精确限额? | 去 AI Studio 看当前 project 的 active limits,不要只信旧博客截图。 |
| 公开文档今天还能确认什么? | project 级限额、RPM/TPM/RPD 机制、午夜 PT 重置、tier 升级门槛、免费/付费计费状态、未付费服务条款。 |
| 免费额度能当生产配额吗? | 不建议。它更像原型和测试入口,而不是带稳定承诺的正式容量。 |
| 默认先用哪个模型? | 大多数人先从 Gemini 2.5 Flash 开始;如果更看重调用次数和低成本,可以先试 Flash-Lite。 |
| 什么时候该付费? | 你需要稳定性、隐私、欧洲用户上线、或已经开始为 429 写太多补丁的时候。 |
如果你下一步已经从“能不能免费用”转向“正式跑起来多少钱”,可以接着看我们的 Google Gemini API 定价 2026 指南。如果你比较的是 OpenAI 没有类似长期可用的免费 API 路径这一点,也可以参考 OpenAI API 免费试用现状。
2026 年 3 月的 Gemini API 免费额度到底意味着什么
今天最有用的理解方式,不是再去找一张“Gemini 免费额度表”,而是把免费额度拆成两个问题。第一个问题是:Google 还承不承认这个免费入口存在?答案是承认。官方 quickstart 依然说可以免费创建 key,官方 pricing 依然显示几个核心 2.5 模型的标准调用为免费。第二个问题是:Google 还不还愿意在公开网页里,把你项目当前的精确免费限额完整写死?答案已经不再是过去那种“是”。
这背后最大的变化是公开文档的语气。官方 rate limits 页面 现在仍然说明 RPM、TPM、RPD 的机制,也仍然说明 RPD 在太平洋时间午夜重置、限额按 project 而不是按 API key 计算,但它不再把完整的实时免费矩阵作为公开页面中心信息,而是引导你去 AI Studio 查看 active rate limits。页面同时还写了 “Specified rate limits are not guaranteed and actual capacity may vary”。这句话很关键,它意味着:免费额度依然是官方产品状态,但并不应该再被理解成一个完全公开、完全刚性的生产承诺。
这也是 2025 年 12 月很多开发者情绪爆发的原因。很多人已经把 Gemini 免费额度当成稳定基础设施来设计原型甚至小型应用,当配额收紧、页面表达方式改变之后,搜索结果却还留在旧时代,于是开发者看到的是“博客说可以,实际却一直 429”。如果你去看 Google AI Developers Forum 上关于免费额度骤降的讨论,就会发现问题不只是数字减少,更是预期模型发生了变化。
因此,今天这套免费额度更适合三类事情:
- 学习和试验 Gemini API;
- 快速验证一个产品原型是否值得继续做;
- 在低风险、低频率、可容忍波动的内部工具里试运行。
它不适合你用来假设“只要我按旧教程中的表控速,就一定能稳定跑生产”。
Google 今天仍然公开确认的事实

下面这张表只放今天仍然能从公开 Google 文档直接确认的内容。这样做的目的很简单:把真正稳定的事实和“社区里流传的旧数字”分开。
| 主题 | 当前仍公开可验证的事实 | 为什么重要 |
|---|---|---|
| 免费入口 | 官方 quickstart 仍写明可以免费创建 Gemini API key。 | 证明免费入口仍然存在。 |
| 限额范围 | 限额按 project 计算,不是按单个 API key 计算。 | 多开 key 不会把免费额度翻倍。 |
| 重置时间 | RPD 在太平洋时间午夜重置。 | 解释为什么每天恢复时间是按美西时间算。 |
| 限额维度 | 公开文档依旧把 RPM、TPM、RPD 作为主要维度。 | 你得先知道自己到底撞的是哪一类限制。 |
| 实时限额入口 | Google 让你去 AI Studio 查看 active rate limits。 | 说明“当前具体限额”已经更多依赖实时控制台。 |
| Tier 1 升级 | 开启 billing 后进入 Tier 1。 | 这是从原型阶段迈向正式容量的第一步。 |
| Tier 2 条件 | 已付费满 100 美元,且距离首次成功付款至少 3 天。 | 便于团队规划扩容节点。 |
| Tier 3 条件 | 已付费满 1000 美元,且距离首次成功付款至少 30 天。 | 适合更高流量的预算规划。 |
| 免费计费状态 | 2.5 Pro、2.5 Flash、2.5 Flash-Lite 仍在 pricing 页面标记为免费标准调用。 | 说明 Google 没有取消免费状态本身。 |
| Search grounding | Flash 与 Flash-Lite 仍公开写着共享 500 RPD 的免费 Google Search grounding。 | 这是少数今天仍公开给出精确免费数值的地方。 |
| 长上下文 | Gemini 2.5 Pro 模型页仍标明 1,048,576 输入 token 上限和 65,536 输出 token 上限。 | 长文档、长代码仓分析时非常关键。 |
| 免费数据使用 | 额外条款写明未付费服务中的提示词与响应可用于改进 Google 产品。 | 涉及隐私和敏感数据决策。 |
| 欧洲上线限制 | 面向 EEA、瑞士、英国终端用户的 API 客户端只能使用 paid services。 | 决定免费额度是否能作为当地上线方案。 |
这张表其实回答了一个比“Gemini 现在到底 10 RPM 还是 15 RPM”更重要的问题:哪些事情今天仍然可以被公开文档直接托底。 你会发现真正稳定的,是规则、条款、计费状态和 tier 门槛;不再那么稳定的,是完整实时免费矩阵本身。
怎么在 AI Studio 里看你项目的真实限额
如果这篇文章里只能记住一个操作,那就是:创建 key 以后,马上去 AI Studio 看你真正要用的那个 project 的限额页面。Google 自己在公开 rate limits 页面里就是这么指路的。
比较安全的操作顺序是:
- 在 AI Studio 创建 API key;
- 确认这个 key 绑定的是哪个 Google Cloud project;
- 打开这个 project 的 AI Studio 限额页面;
- 看你实际要调用的模型名,而不是只看家族名;
- 记录 RPM、TPM、RPD,以及它是 stable、preview 还是 experimental。
这么做能避免两个常见误判。第一,很多人以为“我账号下有多个 key,所以额度也会分开”。不会。官方文档写得很清楚:限额按 project 计算。第二,很多人把 stable 模型和 preview 模型当成同一回事,但公开文档也明确说了 preview 和 experimental 往往更容易有更紧的限制。
我非常建议你在两个时点都留截图:第一次创建 key 时截一次,开启 billing 之后再截一次。这样你团队内部讨论限额时,就不会再靠“我好像在哪篇博客看过一个数字”来决策,而是直接基于你们自己项目的当前状态。
看 AI Studio 时,除了原始数字,还要特别看四件事:
- billing 是否已经开启;
- 模型是 stable 还是 preview;
- 是否多个服务共享同一个 project;
- 你的场景是否还依赖 search grounding、图像生成等额外限制。
很多“Gemini 免费额度不稳定”的抱怨,其实并不是模型坏了,而是项目里已经有 playground、内部脚本、定时任务、测试环境一起在吃同一个 bucket。
免费额度下该选哪个模型:Flash、Flash-Lite 还是 Pro

大多数开发者在免费额度阶段,不应该一上来就追求最强模型,而应该优先选择 能让自己更快迭代 的模型。很多时候,真正决定你能不能把原型做出来的,不是一次回答的上限,而是你一天能不能试够足够多次。
| 模型 | 免费阶段最适合做什么 | 为什么常常更合适 | 主要代价 |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 抽取、分类、路由、批量原型 | 计费最低、响应快、适合高频小任务 | 深度推理和复杂编码不如 Flash/Pro |
| Gemini 2.5 Flash | 通用聊天、产品原型、演示版本 | 质量和实用性最平衡,是最稳妥的默认起点 | 精确实时限额仍要到 AI Studio 看 |
| Gemini 2.5 Pro | 长文档推理、复杂代码、难问题分析 | 推理更强,长上下文能力最好 | 免费阶段更容易遇到“体验很好但迭代速度不够”的问题 |
如果你现在的目标是 把产品逻辑跑通,Flash 往往是最稳的默认选项;如果你做的是高频低复杂度任务,比如标签归类、内容抽取、轻量摘要,Flash-Lite 反而更像真正的效率模型。只有当任务本身明显因为推理质量卡住,比如超长文档分析、复杂代码解释、难一点的多步判断,Pro 才值得优先考虑。
换句话说,免费额度阶段的模型选择,本质上是在两个瓶颈之间做取舍:
- 如果你的瓶颈是 任务太难,考虑 Pro;
- 如果你的瓶颈是 调用不够用、试验不够快,优先 Flash 或 Flash-Lite。
如果你接下来已经在比较 Gemini、OpenAI、Claude 三家 API 的正式成本结构,可以看我们的 Gemini vs OpenAI vs Claude 2026 成本对比。
为什么免费额度也会遇到 429
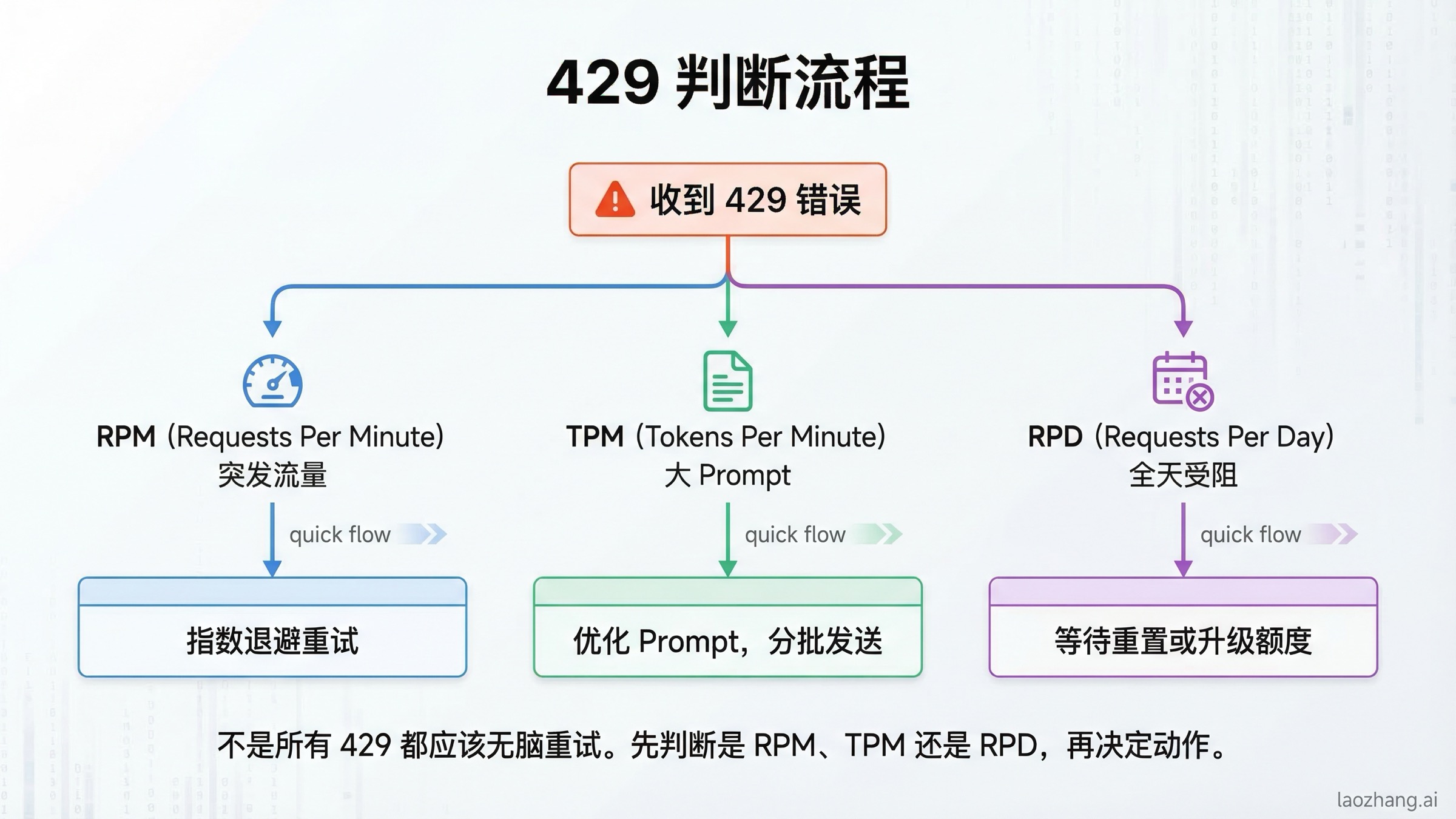
绝大多数 Gemini 免费额度的挫败感,最后都体现成 429。但 429 只是表象,真正关键的是:你撞到的是哪一种限制,以及“重试”到底是不是正确动作。
| 现象 | 更可能的原因 | 应该怎么做 |
|---|---|---|
| 一分钟内突然一波请求全部失败 | RPM 用尽 | 降低并发、排队、加随机退避 |
| 请求次数不多,但长 prompt 一直失败 | TPM 用尽 | 缩短上下文、分块、缓存重复内容 |
| 一整天前半段正常,后半段持续失败 | RPD 用尽 | 等到太平洋时间午夜,或者开 billing |
| 不同服务同时开始报错 | 同一个 project 共享额度 | 拆 project,或减少后台流量 |
| 预览模型明显更容易报错 | preview 限额更紧 | 尽量换成 stable 版本 |
| 已经开 billing 但还是感觉不够 | project 搞错、tier 没看准、或实际容量波动 | 回 AI Studio 重新核对当前项目状态 |
最重要的一点是:不是所有 429 都应该靠重试来解决。 如果是 RPM 突刺,指数退避很有用;如果是 RPD 已经用完,再优雅的 backoff 也只是浪费时间。很多开发者会在这一步做错方向:把“应该升级”的问题,当成“我还没把重试逻辑写好”的问题。
第二个容易忽略的点是,Google 现在公开就写着 actual capacity may vary。再加上社区里一段时间以来反复出现的“实际可用性比预期差”的反馈,你就应该把免费额度理解成 适合试验、不适合承诺稳定 SLA 的资源。
如果你只是想给项目加一个最基本的 429 处理逻辑,下面这种简单写法已经够了:
pythonimport asyncio import random from google import genai client = genai.Client(api_key="YOUR_GEMINI_API_KEY") async def generate_with_retry(prompt: str, retries: int = 5): for attempt in range(retries): try: return client.models.generate_content( model="gemini-2.5-flash", contents=prompt, ) except Exception as exc: if "429" not in str(exc) or attempt == retries - 1: raise delay = min(2 ** attempt + random.random(), 30) await asyncio.sleep(delay)
但请记住,这段代码只对“适合重试”的 429 有用。它不能凭空帮你多出一天的 RPD。想更系统地理解这类错误,可以继续看我们的 Gemini API rate limit 深度说明;目前这篇英文文章还没有中文对应版本,所以这里是显式英文参考。
什么时候免费额度已经不划算了
Gemini 免费额度真正适合的是“失败代价很低”的阶段。一旦你发现失败代价比账单更贵,继续死撑免费额度往往就是假省钱。
| 场景 | 继续免费额度合适吗? | 原因 |
|---|---|---|
| 学习、试验、周末原型 | 合适 | 这本来就是它最适合的用途 |
| 小型内部工具、低频调用 | 视情况而定 | 只要能容忍波动和日配额打满即可 |
| 面向用户的正式产品 | 不合适 | 你需要更稳定的容量和更明确的可预期性 |
| 含敏感文档或敏感提示词 | 不合适 | 未付费服务的数据使用条款不适合这种场景 |
| 面向 EEA、瑞士、英国用户上线 | 不合适 | 条款明确要求 paid services |
| 你已经写了大量排队、重试、限流补丁 | 通常不合适 | 工程时间成本已经开始高于账单 |
我更推荐用下面这条简单规则来判断:
- 你需要 稳定性,就付费;
- 你需要 更清晰的隐私边界,就付费;
- 你需要 欧洲地区可上线性,就付费;
- 你需要 团队多人持续高频开发,就付费。
免费额度最有价值的地方,是帮助你证明“这个项目值得预算”,而不是长期替代预算本身。
如何免费拿到 API key 并发出第一条请求
一旦你接受了上面的现实,Gemini 的入门流程其实依然非常简单。官方 quickstart 仍然是最可靠的入口。
简化步骤如下:
- 打开 Google AI Studio;
- 创建 Gemini API key;
- 把 key 放到
GEMINI_API_KEY环境变量里; - 先用 Gemini 2.5 Flash 发第一条请求;
- 回到 AI Studio 记录你项目当前的实际限额。
Python 示例:
pythonfrom google import genai import os client = genai.Client(api_key=os.environ["GEMINI_API_KEY"]) response = client.models.generate_content( model="gemini-2.5-flash", contents="请用通俗中文解释什么是向量数据库。", ) print(response.text)
Node.js 示例:
tsimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-2.5-flash", contents: "请用通俗中文解释什么是向量数据库。", }); console.log(response.text);
这里真正需要记住的不是代码,而是两条操作习惯。第一,不要把 key 直接放到前端;第二,如果你试的是 Pro 或 preview 模型,不要凭“网上说大概是多少”来判断自己的配额,先去 AI Studio 核对。
FAQ
创建 Gemini API key 需要信用卡吗?
不需要。Google 公开 quickstart 仍然写着可以免费创建 API key 开始使用。只有当你要进入付费额度时,才需要 billing。
免费额度里的提示词和响应会被 Google 用来改进产品吗?
会。Gemini API 额外条款明确写了,未付费服务中的输入和输出可以用于提供、改进和开发 Google 的产品与服务。所以涉及敏感数据时,不应继续依赖免费额度。
面向 EEA、瑞士、英国用户的应用可以用免费额度上线吗?
不可以。额外条款明确写明,这些地区的终端用户应用只能使用 paid services。
网上常见的 5 RPM、10 RPM、15 RPM 表现在还准吗?
最多只能当作历史参考,不能当成今天对你项目的保证。当前公开 rate limits 页面已经把“活跃限额”引导到 AI Studio,并明确说明实际容量可能波动。
免费阶段先选哪个模型最稳?
大多数人先从 Gemini 2.5 Flash 开始最稳;如果你做的是高频简单任务,Flash-Lite 也很适合。只有任务难度明显卡住时,才优先上 Pro。
开启 billing 之后是不是立刻就没问题了?
不是“所有问题都立刻消失”,但它通常能解决最核心的容量问题。公开文档写明 Tier 1 从开启 billing 开始,更高 tier 还要满足付费金额和时间门槛。你依然需要去 AI Studio 看实际项目状态。