Google 的 Gemini API 在 2026 年依然是最慷慨的免费 AI API 之一,开发者可以零成本使用 Gemini 2.5 Pro 等前沿模型,并享有 100 万 token 的上下文窗口。2025 年 12 月的配额削减让数千名开发者措手不及,之后,精确了解免费配额的具体内容以及何时值得付费,已经成为每位 AI 开发者的必备知识。本指南提供经 Chrome 验证的 Google 官方数据、实用的成本计算,以及一套你今天就能用于实际决策的升级框架。
要点速览
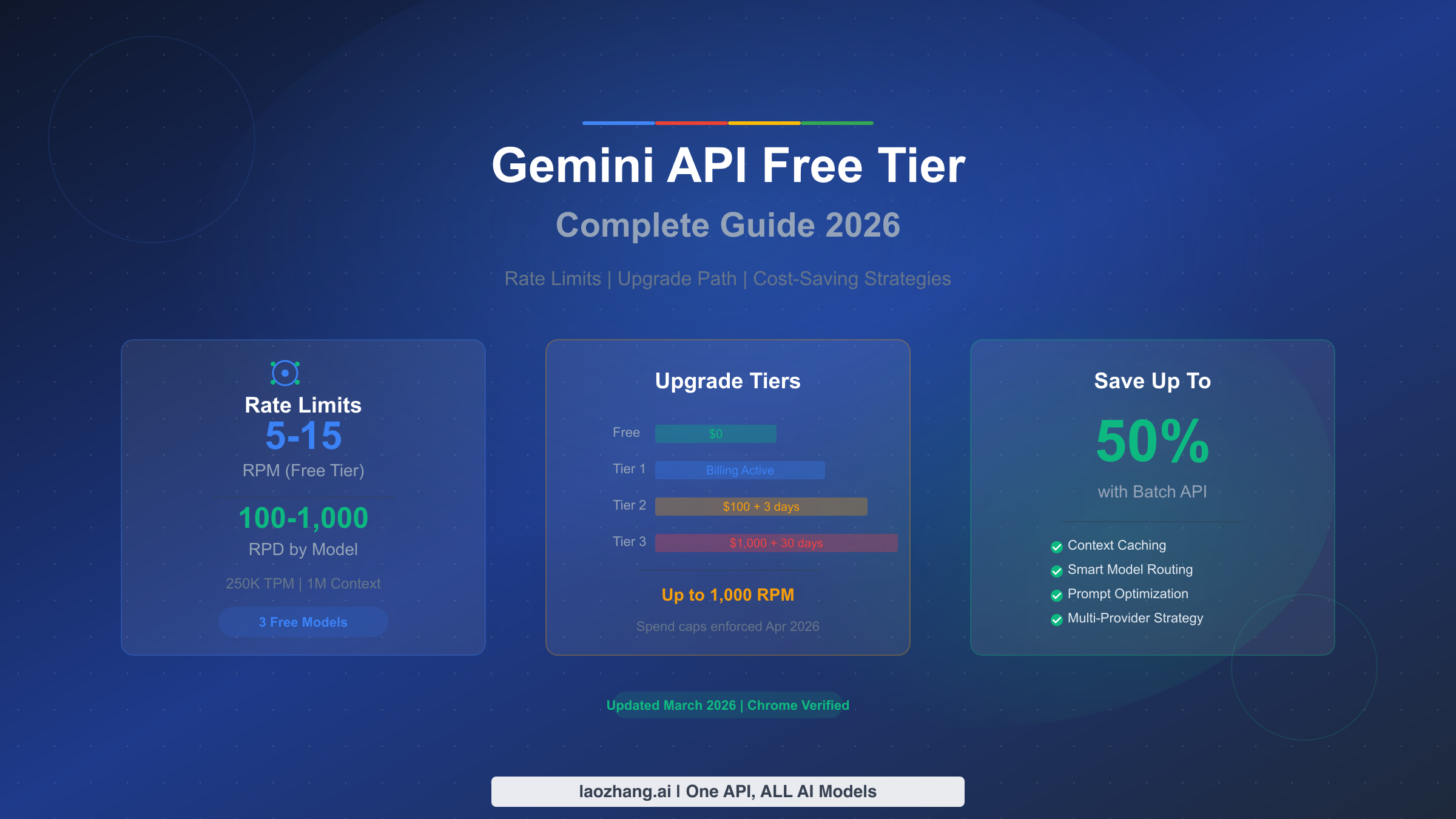
Gemini API 免费配额目前提供三款稳定模型,速率限制从每分钟 5 次到 15 次请求不等,具体取决于你选择的模型。以下是每位开发者在写第一行代码之前都应了解的核心信息。
截至 2026 年 3 月,免费配额包含的三款模型分别是:Gemini 2.5 Pro(5 RPM、每日 100 次请求)、Gemini 2.5 Flash(10 RPM、每日 250 次请求)和 Gemini 2.5 Flash-Lite(以 15 RPM 和每日 1,000 次请求领先)。三款模型共享每分钟 250,000 token 的限额,并完整支持 100 万 token 上下文窗口。此外还有两款预览版模型——Gemini 3 Flash 和 Gemini 3.1 Flash-Lite——同样免费提供,但限制更为严格。开通不需要信用卡,但请注意,免费配额下你的提示词和响应内容可能会被用于改进 Google 产品。升级到 Tier 1 不需要预付费用,按用量计费即可,升级后立即消除数据共享顾虑,同时速率限制提升至 150-300 RPM。
免费配额完整速率限制:每个模型、每个数字

理解速率限制是高效使用 Gemini API 的基础,而这些数字自 2025 年底以来已经发生了重大变化。Google 从三个维度衡量速率限制:每分钟请求数(RPM)、每分钟 token 数(TPM)和每日请求数(RPD)。你的用量会同时与这三个维度进行比对,超过任一限制就会触发 429 错误,即使其他两个维度远未达标也是如此。这些限制是按 Google Cloud 项目而非单个 API Key 进行统计的,每日配额在太平洋时间午夜重置。
下表列出了截至 2026 年 3 月免费配额所有可用模型的完整速率限制,经 Chrome 验证,数据直接提取自 Google 官方速率限制文档(ai.google.dev)。
| 模型 | RPM | RPD | TPM | 上下文窗口 | 状态 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 100 | 250,000 | 100万 tokens | 稳定版 |
| Gemini 2.5 Flash | 10 | 250 | 250,000 | 100万 tokens | 稳定版 |
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 250,000 | 100万 tokens | 稳定版 |
| Gemini 3 Flash Preview | 有限 | 有限 | 有限 | 100万 tokens | 预览版 |
| Gemini 3.1 Flash-Lite Preview | 有限 | 有限 | 有限 | 100万 tokens | 预览版 |
除了文本生成模型,Google 还免费提供嵌入模型。Gemini Embedding 模型在免费配额下支持每分钟 1000 万 token,对于构建搜索和检索系统来说非常慷慨。更新的 Gemini Embedding 2 Preview 增加了多模态嵌入能力,支持文本、图片、音频和视频输入,全部免费。
值得注意的是,官方公布的速率限制代表的是理论上限,实际可用容量可能有所不同。Reddit 上多位开发者反馈,在高峰时段实际遇到的限制远低于官方数字。r/GeminiAI 子版块记录了一些案例:尽管官方 RPD 限制为 250,Gemini 2.5 Flash 在高流量时段实际只能完成约 20 次请求。Google 的文档也承认了这一点,声明"指定的速率限制不作保证,实际容量可能有所变化"。
预览版模型的额外限制
Gemini 3 Flash 和 Gemini 3.1 Flash-Lite 等预览版模型在标准速率限制之外还有额外的限制。这些模型的配额更为严格,Google 会随着模型开发进度频繁调整。它们还缺少稳定版模型上可用的功能,例如上下文缓存和批量 API 支持。对于生产工作负载,稳定的 2.5 系列仍然是推荐选择,而预览版模型更适合用于评估和实验。
5 分钟获取免费 API Key
设置 Gemini API 免费配额的访问权限非常简单,无需任何付款信息。整个过程大约需要五分钟,只涉及三个步骤。首先,访问 Google AI Studio(aistudio.google.com)并使用你的 Google 账号登录。如果你还没有 Google 账号,需要先创建一个,这大约会多花两分钟。
登录后,导航到 API Keys 部分,你可以在左侧边栏或 aistudio.google.com/api-keys 找到它。点击"Create API Key"按钮。Google 会自动创建一个新的 Google Cloud 项目,或者让你选择一个现有项目。你的 API Key 会立即生成,然后就可以在免费配额限制下开始调用 API 了。
用一个简单的 curl 命令测试你的 Key:
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{"contents":[{"parts":[{"text":"Explain rate limits in one sentence"}]}]}'
关于 API Key 管理,有几个重要细节需要注意。每个 Google Cloud 项目最多可以有 5 个 API Key,一个结算账号最多可以支持 10 个项目。这意味着你在一个结算体系下理论上可以管理多达 50 个 API Key,但速率限制是在项目级别而非 Key 级别执行的。在同一项目中创建多个 Key 并不会叠加你的配额。如果你需要在免费配额下获得更高的总吞吐量,需要使用不同的项目,但请注意 Google 会监控滥用此方法的行为。如需详细的 Key 生成流程和常见问题排查,请参阅我们的 Gemini API Key 完整指南。
2025 年 12 月到底发生了什么
2025 年 12 月 6-7 日那个周末标志着 Gemini API 免费配额的分水岭时刻。在没有任何预先通知的情况下,Google 大幅削减了所有免费配额模型的速率限制,导致大量 429"resource exhausted"错误,一夜之间中断了数千名开发者的生产工作流。Reddit 和 Hacker News 上的社区反应迅速而激烈,r/GeminiAI 上相关帖子累计收到超过 210 条来自沮丧开发者的评论。
Google AI Studio 的首席产品经理 Logan Kilpatrick 解释了这一决定的背景。他表示,慷慨的免费配额限制"最初只计划在一个周末内提供",但"无意中持续了几个月"。Google 将"大规模的欺诈和滥用"列为全面削减配额的主要原因。削减并不是对所有模型一视同仁——有些模型的限制削减了 50%,有些则削减了多达 80%,具体影响取决于特定的模型和请求类型。
实际影响非常严重。依赖原有限制构建应用的开发者突然发现系统无法运行。聊天机器人停止响应,批处理流水线陷入停滞,自动化工作流全面瘫痪。更雪上加霜的是,Google 没有提供任何迁移期或提前警告,开发者不得不在一个周末内匆忙优化使用方式或升级到付费层级。
自 2025 年 12 月以来,速率限制已稳定在本指南记录的当前水平。Google 还在 2026 年 2 月弃用了 Gemini 2.0 Flash,该模型于 2026 年 3 月 3 日正式退役。这意味着之前使用 2.0 Flash 作为高吞吐量免费选项的开发者需要迁移到 2.5 Flash 或 Flash-Lite 模型。这一事件的教训很明确:完全依赖免费配额构建生产系统存在固有风险,无论当时的配额看起来多么慷慨。如果你在这次过渡中遇到了 429 错误,我们的详细错误排查指南提供了恢复策略。
Gemini vs OpenAI vs Claude:免费方案大比拼

讨论 Gemini 免费配额,就不能不了解它与竞争对手的对比情况。这个比较揭示了为什么 Gemini 在 2026 年仍然是大多数开发者最优的免费选择,尽管经历了 2025 年 12 月的配额削减。三大 AI API 提供商在免费访问方面采取了截然不同的策略,理解这些差异可以为你节省大量的金钱和开发时间。
Google 的 Gemini API 是唯一提供真正免费配额的——不需要信用卡,不需要任何初始付款。你只需用 Google 账号注册即可立即开始调用 API。相比之下,OpenAI 和 Anthropic 都要求绑定信用卡,并提供有过期时限的初始额度。OpenAI 提供 5 美元额度,3 个月后过期;Anthropic 的 Claude API 提供类似的 5 美元额度,有效期为 30 天。一旦额度用完,你就立即进入付费计划。
| 功能 | Gemini(免费) | OpenAI($5 额度) | Claude($5 额度) |
|---|---|---|---|
| 需要信用卡 | 否 | 是 | 是 |
| RPM | 5-15 | 500(Tier 1) | 50(Tier 1) |
| RPD | 100-1,000 | 10,000 | 1,000 |
| TPM | 250,000 | 200,000 | 40,000 |
| 上下文窗口 | 100万 tokens | 128K(GPT-4o) | 200K(Claude) |
| 免费模型 | 5(3稳定+2预览) | GPT-4o、GPT-4o mini | Sonnet、Haiku |
| 有效期 | 无限制 | 3 个月 | 30 天 |
| 数据隐私 | 用于训练 | 不用于训练 | 不用于训练 |
| 搜索/Grounding | 免费(500 RPD) | 免费不可用 | 不可用 |
上下文窗口的优势是 Gemini 最显著的差异化特征。免费配额下 100 万 token 的上下文窗口,让你可以在单次请求中处理整个代码库、长篇文档或数小时的对话历史。OpenAI 的 GPT-4o 上限为 128K token,即使是 Claude 慷慨的 200K 上下文窗口,也只有 Gemini 免费提供的五分之一。
然而,Gemini 免费配额伴随着一个开发者必须认真考虑的重大权衡:数据隐私。在免费配额下,你的提示词和响应可能会被用于改进 Google 产品。这使得免费配额不适合处理敏感用户数据、专有商业信息或任何受隐私法规约束的内容。OpenAI 和 Claude 的 API 数据在任何层级都不会被用于训练。如果数据隐私是你的刚需,升级到 Gemini 付费 Tier 1 即可消除数据共享,同时价格仍然具有竞争力。如需深入了解 Gemini 和 OpenAI 各层级的定价对比,请参阅我们的详细定价对比指南。
对于需要访问多个 AI 提供商但不想管理多套 API Key 和结算账号的开发者,laozhang.ai 等统一 API 平台提供了单一端点来访问 Gemini、OpenAI、Claude 及数十种其他模型,在简化多提供商架构的同时,往往还能通过批量聚合提供成本优势。
真实成本分析:升级后到底花多少钱
要理解升级超出免费配额后的实际成本,需要将基于 token 的定价转化为真实使用场景。定价页面显示 Gemini 2.5 Flash 的数字是"每百万输入 token $0.30",但这对你的月账单意味着什么?让我们用截至 2026 年 3 月经过验证的 ai.google.dev 定价(来源:Gemini API 定价),计算三个常见使用场景的成本。
场景一:客服聊天机器人(小型企业)
一个每天处理 200 次对话的聊天机器人,每次对话平均 3 轮交互,每轮 500 输入 token 和 300 输出 token。月度用量:200 次对话 x 30 天 x 3 轮 = 18,000 次请求。输入 token:18,000 x 500 = 900 万 token。输出 token:18,000 x 300 = 540 万 token。使用 Gemini 2.5 Flash(每百万 token $0.30/$2.50):输入成本 $2.70,输出成本 $13.50,合计约 $16.20/月。同样的工作负载使用 OpenAI GPT-4o(每百万 token $2.50/$10.00):输入 $22.50 + 输出 $54.00 = $76.50/月。使用 Gemini 节省 79%。
场景二:RAG 文档检索系统(初创企业)
一个检索增强生成系统,每天处理 500 次查询,每次查询包含 10,000 token 的检索文档上下文和 1,000 token 的响应。月度用量:500 x 30 = 15,000 次请求。输入:1.5 亿 token。输出:1500 万 token。Gemini 2.5 Flash 成本:输入 $45.00 + 输出 $37.50 = $82.50/月。使用批量 API(符合条件的请求享受 50% 折扣):如果查询可以批处理,约 $41.25/月。同样的工作负载使用 GPT-4o:输入 $375 + 输出 $150 = $525/月。Gemini 每月节省 $442.50,节省率 84%。
场景三:大规模内容处理(企业级)
每天处理 2,000 份文档,平均每份 50,000 输入 token 和 2,000 输出 token。月度用量:60,000 次请求。输入:30 亿 token。输出:1.2 亿 token。此时 Gemini 2.5 Flash-Lite(每百万 token $0.10/$0.40)是明智之选:输入 $300 + 输出 $48 = $348/月。使用批量 API:约 $174/月。对比 GPT-4o mini($0.15/$0.60):$450 + $72 = $522/月。在 2.5 Pro 层级,上下文缓存可将重复输入成本降低最高 75%,差距更加明显。如需所有模型和层级的完整定价信息,我们的 Gemini API 定价与配额指南 提供了详尽的表格。
| 场景 | Gemini 2.5 Flash | GPT-4o | 节省 |
|---|---|---|---|
| 聊天机器人(200次/天) | $16.20/月 | $76.50/月 | 79% |
| RAG 检索(500次/天) | $82.50/月 | $525/月 | 84% |
| 内容处理(2K/天) | $348/月* | $522/月** | 33% |
*使用 Flash-Lite + 批量 API 可降至约 $174/月。**使用 GPT-4o mini。
何时升级:决策框架
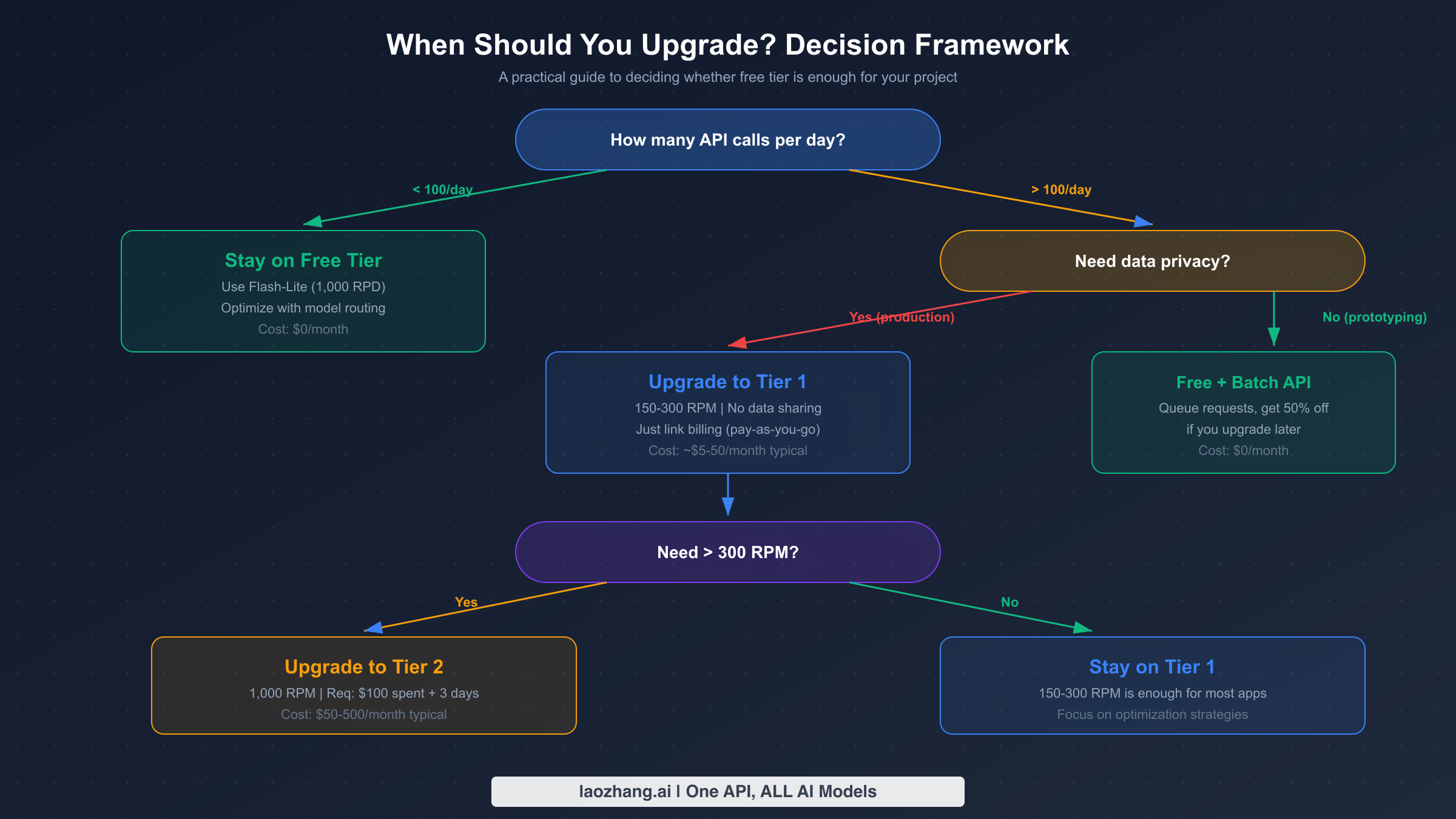
从免费配额升级的决策应该基于具体的使用指标,而非猜测。Google 提供四个层级,每个层级有不同的速率限制、定价和资格要求。层级体系在 2026 年初进行了更新,消费上限计划从 2026 年 4 月 1 日开始执行(来源:ai.google.dev/gemini-api/docs/billing,2026 年 3 月验证)。
继续使用免费配额的情况:你的应用每天 API 调用少于 100 次,并且你能接受数据被用于改进 Google 产品。免费配额非常适合个人项目、原型开发、学术研究和低流量内部工具。将请求路由到 Flash-Lite,你可以每天零成本获得多达 1,000 次请求,这对许多实际使用场景绰绰有余。
升级到 Tier 1 的情况:你需要每天超过 100 次请求、需要数据隐私保证,或者需要稳定的速率限制来支撑生产工作负载。Tier 1 激活只需绑定结算账号,无最低消费要求。你立即获得 150-300 RPM(取决于模型),这是免费配额的 30 倍提升。月度消费上限为 $250,提供了自然的成本安全网。大多数中小型应用会发现 Tier 1 完全够用。
升级到 Tier 2 的情况:你持续需要超过 300 RPM 或月度使用超过 $250。资格要求为累计消费 $100 且首次付款后至少 3 天。Tier 2 解锁最高 1,000 RPM,消费上限提升至每月 $2,000。此层级适合服务数百名并发用户的生产应用。
升级到 Tier 3 的情况:你在运行需要最高吞吐量的企业级工作负载。资格要求为累计消费 $1,000 且首次付款后 30 天。Tier 3 提供最高的速率限制,消费上限从 $20,000 到超过 $100,000/月不等。如需升级流程的详细指导,请参阅我们的层级升级教程。
许多开发者忽略了一个关键信息:Tier 1 本质上是免费进入的。你只需为实际消耗的 token 付费,没有订阅费或最低消费承诺。如果你的用量较低,月账单可能只有几美元,却能获得显著更高的速率限制和完整的数据隐私保护。
最大化免费配额的 7 大策略
无论你选择留在免费配额还是升级到付费方案,以下优化策略都能帮你从每次 API 调用中获取最大价值。这些技巧是可叠加的,组合使用多种策略可以将有效成本降低 60-80%。
策略一:智能模型路由
最简单的优化是将请求路由到能胜任的最低成本模型。并非每个查询都需要 Gemini 2.5 Pro 的推理能力。对于分类任务、简单问答和结构化数据提取,Flash-Lite 能以极低的成本提供相当的效果。构建一个路由层,评估查询复杂度后将简单请求导向 Flash-Lite(免费配额下 15 RPM、1,000 RPD),将 Pro 留给真正需要高级推理的任务。
策略二:善用批量 API
对于不需要实时响应的工作负载,Google 的批量 API 在所有模型定价上提供固定 50% 的折扣。批量请求会被排队并在 24 小时内处理,非常适合内容生成、文档分析、数据提取流水线以及任何可以接受数小时延迟的任务。在免费配额下,批量请求有独立的速率限制,有效地将你的可用吞吐量翻倍。当你升级到付费层级后,仅这一项策略就能将成本减半。
策略三:上下文缓存应对重复场景
如果你的应用反复发送相同的大段上下文——比如系统提示词、参考文档或少样本示例——上下文缓存可以大幅降低输入 token 成本。缓存上下文的计费约为标准输入 token 的 25%,另加每小时的存储费用。盈亏平衡点大约在你一小时内复用相同上下文 4-5 次以上。对于使用固定系统提示词的 RAG 应用和聊天机器人,仅这一项优化就能将输入成本降低 50-75%。我们的上下文缓存降本指南提供了实现细节和代码示例。
策略四:提示词压缩与优化
在不牺牲输出质量的前提下减少输入 token 数量,是一种高杠杆的优化手段。去除系统提示词中不必要的冗余表达,使用简洁的格式指令,利用结构化输出 schema 精确指定返回格式。一个经过良好优化的提示词可以比初始版本短 40-60%,同时产生相同质量的输出。在免费配额下 TPM 限制为 250,000 的条件下,高效的提示词意味着每分钟能完成更多有用的请求。
策略五:实现指数退避与抖动机制
当你触及速率限制时,简单的重试逻辑可能会因为产生同步重试风暴而让情况更糟。实现带有随机抖动的指数退避来分散重试时间。从 1 秒延迟开始,每次重试翻倍,添加最高 50% 的随机变化量。最大延迟上限设为 60 秒,总重试次数限制为 5 次。这种方法通过避免浪费性重试同时尊重 Google 的速率限制,最大化你的实际吞吐量。
策略六:请求去重与本地缓存
在向 API 发送任何请求之前,先检查你是否已经收到过相同或足够相似的响应。实现本地缓存——简单应用用内存缓存,生产系统用 Redis 支持——以输入内容的哈希值为键存储响应。对于许多应用来说,20-40% 的请求是重复或近似重复的,可以直接从缓存响应,大幅降低成本和延迟。
策略七:多提供商故障转移策略
与其完全依赖单一 API 提供商,不如构建一个故障转移链,在触及 Gemini 速率限制时路由到替代提供商。当你的 Gemini 配额耗尽时,自动切换到 OpenAI、Claude 或开源替代方案。通过 laozhang.ai 等将多个提供商聚合在单一 API 端点下的平台,可以在最大化所有提供商的有效免费配额的同时,确保你的应用不会因为任何单一提供商的速率限制而宕机。
常见问题解答
Gemini API 真的免费吗?
是的,Gemini API 提供真正的免费配额,不需要信用卡,没有过期时限。你可以使用包括 Gemini 2.5 Pro、Flash 和 Flash-Lite 在内的模型,速率限制为 5-15 RPM 和 100-1,000 RPD。主要的权衡是你的数据在免费配额下可能会被用于改进 Google 产品。
如何解决 429"resource exhausted"错误?
429 错误表示你已超过某个速率限制(RPM、TPM 或 RPD)。首先,检查错误响应头确认你触及了哪个限制。如果是 RPD,等到太平洋时间午夜配额重置。如果是 RPM 或 TPM,实现带抖动的指数退避。考虑切换到限制更高的模型,比如拥有 1,000 RPD 的 Flash-Lite,或者升级到 Tier 1 获得 30 倍的速率限制提升。
免费配额和 Tier 1 有什么区别?
免费配额只需要一个 Google 账号,提供有限的 RPM 和 RPD。Tier 1 需要绑定结算账号但没有最低消费。关键区别在于速率限制(150-300 RPM vs 5-15 RPM)、数据隐私(Tier 1 不会将你的数据用于训练)以及对上下文缓存和批量 API 等功能的付费访问。升级本质上是免费的,因为你只需为消耗的 token 付费。
免费配额可以用于生产应用吗?
技术上可以,但风险很大。2025 年 12 月的配额削减证明了 Google 可以在没有通知的情况下减少免费配额限制。5-15 RPM 的速率限制对于大多数面向用户的应用来说太低了,数据隐私方面的影响也可能违反用户预期或监管要求。对于任何服务真实用户的应用,Tier 1 是推荐的最低配置。
Gemini 免费配额与本地 LLM 相比如何?
本地 LLM 完全消除了速率限制和 API 成本,但需要大量的硬件投入。运行一个能力较强的开源模型(如 Llama)至少需要 12GB 显存用于推理,而且在复杂任务上质量通常不如 Gemini 2.5 Pro。对于需要前沿模型质量但不想投入硬件的大多数开发者来说,Gemini 免费配额是更好的选择;而本地模型更适合对隐私敏感、需求较简单且有 GPU 资源的工作负载。
Google 还会再次削减免费配额吗?
Google 尚未宣布进一步削减的计划,但 2025 年 12 月的先例表明免费配额限制可能在没有通知的情况下改变。最佳做法是将应用架构设计为能够优雅地应对速率限制变化,使用本指南中的优化策略减少对任何单一提供商免费配额的依赖,并提前规划好升级路径,即使你目前不打算激活它。