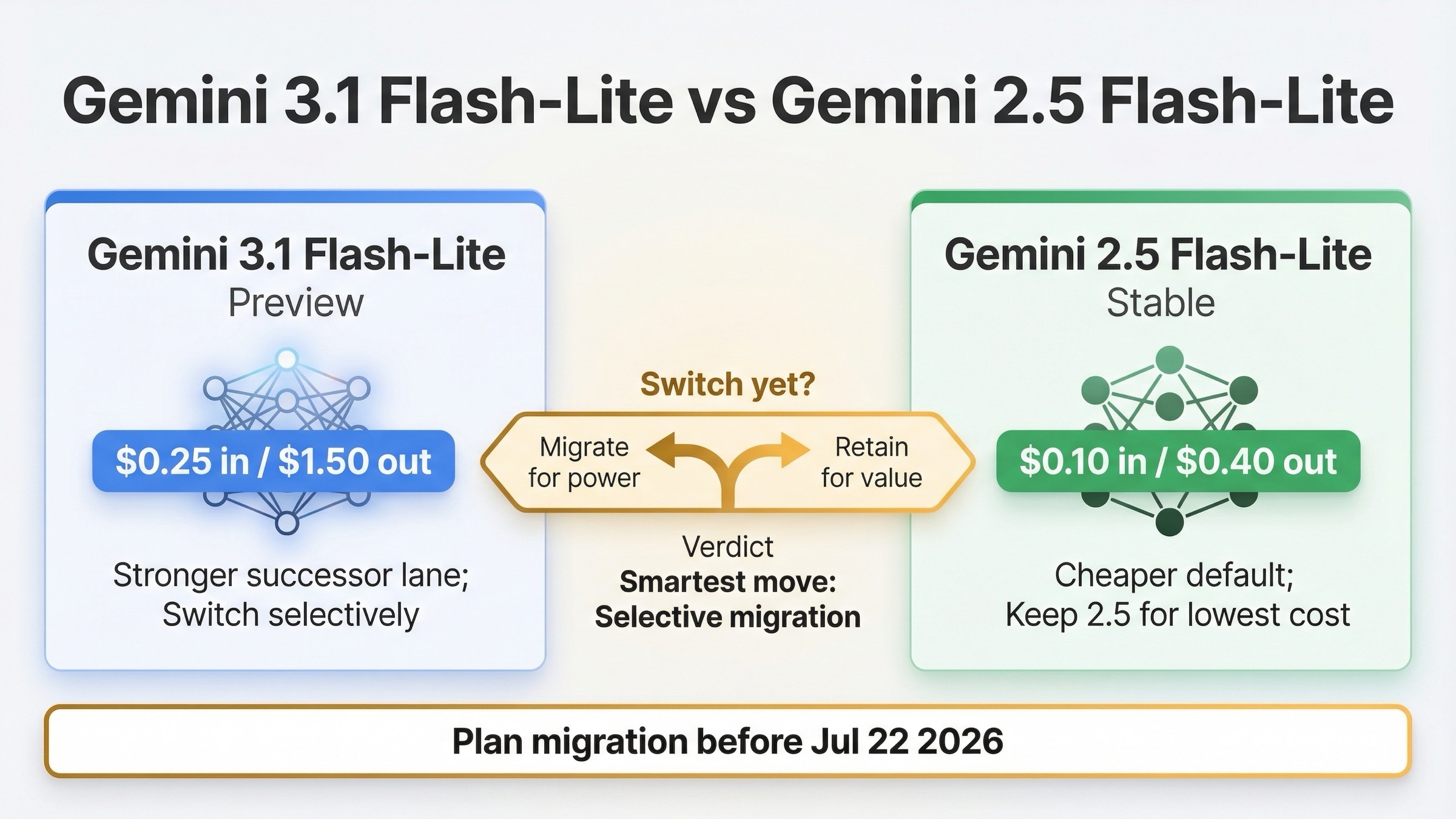
As of March 20, 2026, Gemini 2.5 Flash-Lite is still the better default if your priority is the lowest stable token cost and a free standard tier. Gemini 3.1 Flash-Lite is the better successor lane if you need a real quality jump and can justify paying much more for a preview model that Google already lists as the official replacement path. That is the practical answer behind this keyword.
This comparison matters because Google is telling two stories at the same time. On the official deprecations page, gemini-3.1-flash-lite-preview is the recommended replacement for gemini-2.5-flash-lite, and the stable 2.5 Flash-Lite model now has an earliest shutdown date of July 22, 2026. But the official pricing page still makes 2.5 Flash-Lite the cheaper live option by a wide margin. So the right question is not "Which name is newer?" It is "Should I move now, wait, or split my traffic?"
If you want the short answer, here it is: stay on 2.5 Flash-Lite if minimum spend is the main goal, move specific higher-value workloads to 3.1 Flash-Lite if the quality jump pays for itself, and plan an orderly migration before July 22, 2026 instead of pretending the old lane will remain forever.
TL;DR
- Keep Gemini 2.5 Flash-Lite as your default when you want the lowest stable token cost and a free standard tier.
- Move selected higher-value workloads to Gemini 3.1 Flash-Lite when the quality jump is large enough to repay a much higher token bill.
- If you are still on
gemini-2.5-flash-lite-preview-09-2025, do not wait. That preview line has the tighter migration clock.
The current official comparison looks like this:
| Area | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash-Lite | What it means |
|---|---|---|---|
| Current status | Preview | Stable | 3.1 is newer, but 2.5 is still the lower-risk default |
| Model ID | gemini-3.1-flash-lite-preview | gemini-2.5-flash-lite | You should route explicitly, not assume one silent upgrade path |
| Release timing | March 3, 2026 | July 22, 2025 | 3.1 is the new lane, 2.5 is the mature one |
| Replacement guidance | No shutdown date announced | Earliest shutdown date July 22, 2026; recommended replacement is 3.1 Flash-Lite | 2.5 is still usable, but the migration question is now real |
| Standard input price | $0.25 / 1M | $0.10 / 1M | 3.1 costs 2.5x more on input |
| Standard output price | $1.50 / 1M | $0.40 / 1M | 3.1 costs 3.75x more on output |
| Standard free tier | No free standard token tier shown on pricing page | Free standard tier shown | 2.5 is easier for low-cost experimentation |
| Search grounding | Free up to 500 RPD, then paid allowances | Free up to 500 RPD, then paid allowances | Grounding is not the main difference anymore |
| Public Batch API ceilings | Same published ceilings as 2.5 Flash-Lite | Same published ceilings as 3.1 Flash-Lite | Public batch tables do not give 3.1 a throughput win |
| Best fit | Better quality for translation, routing, extraction, and other high-volume tasks where quality matters | Lowest-cost stable lane for summarization, compaction, light classification, and cost-sensitive production | Pick based on value per task, not on launch momentum |
Those rows come from the official models directory, dedicated Gemini 3.1 Flash-Lite model page, dedicated Gemini 2.5 Flash-Lite model page, pricing page, rate-limits page, release notes, and deprecations page.
The important point is that this is not the same kind of comparison as Gemini 3.1 Flash-Lite versus Gemini 2.5 Flash. In that broader comparison, 3.1 Flash-Lite often wins on both cost and quality. Against 2.5 Flash-Lite, the story changes: 3.1 is the stronger model, but 2.5 remains the cheaper live lane.
If you are only experimenting inside AI Studio, 2.5 Flash-Lite also remains the easier starting point because the live pricing page still shows a standard free tier there. The 3.1 Flash-Lite story becomes more compelling once you are evaluating API workloads where higher quality can save retries, cleanup, or downstream model calls.
Why this is a migration decision, not a normal spec fight
Search results around this keyword are still thin. Google-owned pages dominate because they have the freshest labels, dates, and prices. But those pages mostly answer one slice of the problem at a time. One page shows pricing, another shows model names, another shows shutdown timing, and another shows benchmarks. Very few pages tell you what to do with those facts.
That is why the deprecation table matters so much. Google's official deprecations page now says:
gemini-3.1-flash-lite-previewwas released on March 3, 2026gemini-2.5-flash-litewas released on July 22, 2025- the stable
gemini-2.5-flash-liteline has an earliest shutdown date of July 22, 2026 - Google's recommended replacement for that stable line is
gemini-3.1-flash-lite-preview
That means the answer cannot be "ignore 3.1 Flash-Lite forever." The better answer is more conditional:
- do not rush a full migration if your current 2.5 Flash-Lite traffic is mostly cheap summarization, context compaction, or low-stakes extraction
- do not ignore the new lane if you are already feeling the quality limits of 2.5 Flash-Lite
- do not confuse the stable 2.5 model with the deprecated preview ID
That last point matters. The deprecated gemini-2.5-flash-lite-preview-09-2025 variant has an earlier March 31, 2026 shutdown date. If you are still pinned to that preview ID, your timeline is much tighter than someone already using the stable gemini-2.5-flash-lite model.
So this is really two different questions:
-
If I am on the old preview ID, should I move now?
Yes. You should not burn more time on a model with an announced March 31, 2026 earliest shutdown date. -
If I am already on the stable 2.5 Flash-Lite ID, should I move everything now?
Not automatically. You still have time to benchmark and phase the transition instead of paying the 3.1 premium before it is justified.
Pricing and free-tier reality: 3.1 Flash-Lite is better, but not cheaper
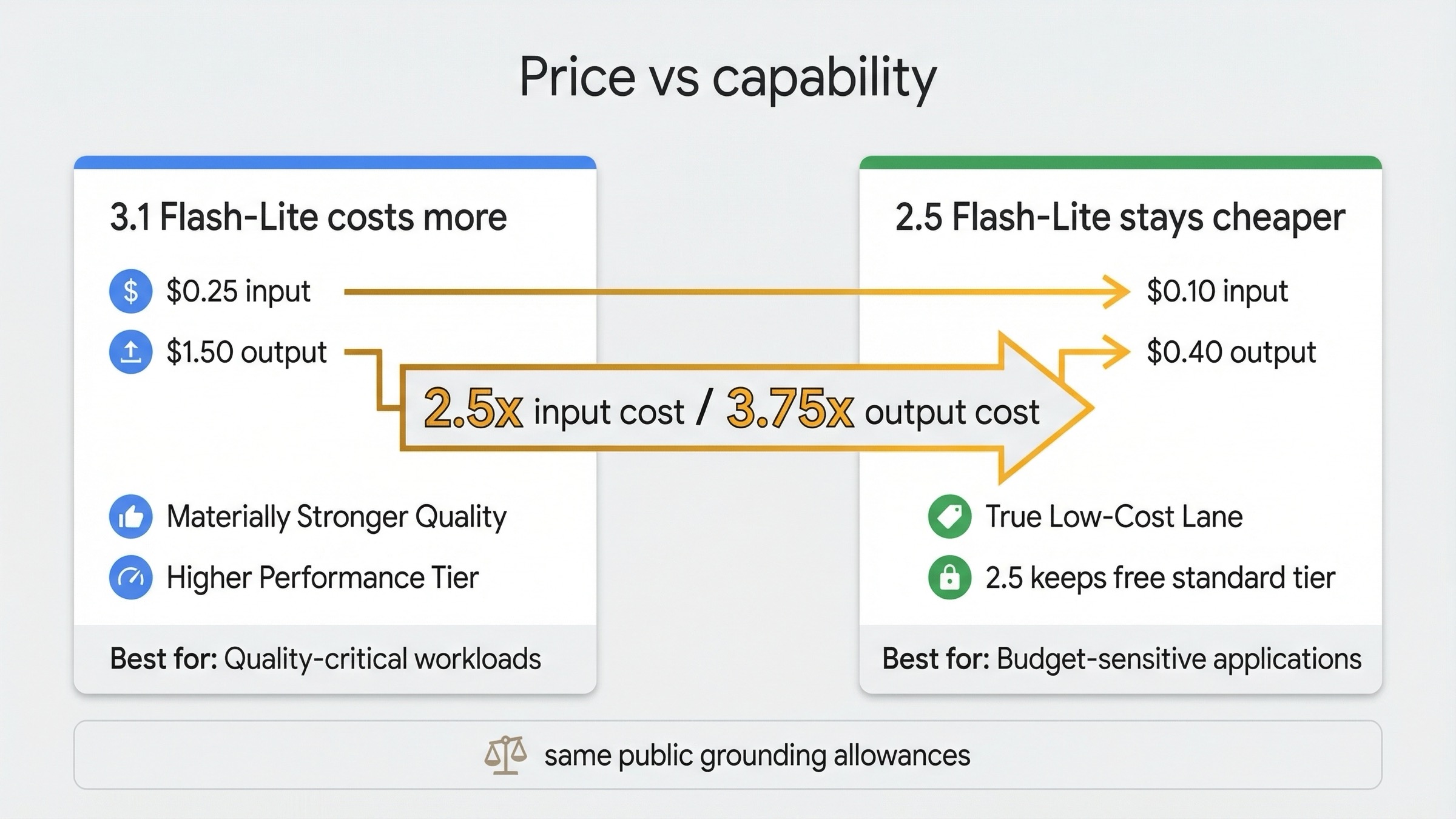
This is the part many quick takes get wrong.
Google's launch post calls Gemini 3.1 Flash-Lite the company's "most cost-effective AI model yet." That wording is easy to misread. It does not mean 3.1 Flash-Lite is cheaper than Gemini 2.5 Flash-Lite on the live token tables. It means Google thinks the quality-per-dollar tradeoff is strong relative to larger models and older lanes.
On the official pricing page, checked on March 20, 2026:
- Gemini 3.1 Flash-Lite Preview costs
\$0.25input and\$1.50output per 1M tokens - Gemini 2.5 Flash-Lite costs
\$0.10input and\$0.40output per 1M tokens
That means the new model is:
- 2.5x more expensive on input
- 3.75x more expensive on output
That is not a rounding error. It changes the recommendation completely.
If your Flash-Lite lane exists mainly to do cheap memory compaction, low-value classification, or bulk summarization, 2.5 Flash-Lite still has a strong case. In many teams, those tasks are supposed to be boring and inexpensive. Paying 3.75x more for output just to say you are on the newest lane is usually weak engineering.
The same pricing page also keeps 2.5 Flash-Lite more attractive for low-friction experimentation. As of March 20, 2026, the live table shows a free standard tier for 2.5 Flash-Lite, while 3.1 Flash-Lite Preview does not show a free standard token tier. So the older model is still easier for budget-sensitive testing, personal tools, and background workloads that need predictable low spend.
One more subtle point matters: grounding does not save 3.1 here. Both tables currently show the same broad grounding story:
- free Google Search grounding up to 500 RPD
- paid-tier free grounding up to 1,500 RPD before overage charges
That means the Flash-Lite comparison is no longer "3.1 is stronger but 2.5 gets the better grounding story." On March 20, 2026, the bigger difference is simpler:
- 2.5 Flash-Lite is still the cheaper stable lane
- 3.1 Flash-Lite is the more capable but more expensive preview successor
If you need the broader billing context around these models, our Gemini API pricing 2026 guide and Gemini API free quota 2026 guide go deeper on the surrounding tier rules.
What 3.1 Flash-Lite actually improves
The strongest official argument for switching is the Google DeepMind Gemini 3.1 Flash-Lite page, because it compares Gemini 3.1 Flash-Lite directly against Gemini 2.5 Flash-Lite rather than against a different tier.
The important rows from that official table look like this:
| Metric | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash-Lite | Lean |
|---|---|---|---|
| Input price | $0.25 / 1M | $0.10 / 1M | Gemini 2.5 Flash-Lite |
| Output price | $1.50 / 1M | $0.40 / 1M | Gemini 2.5 Flash-Lite |
| Output speed | 363 tokens/s | 366 tokens/s | Effectively even |
| GPQA Diamond | 86.9% | 66.7% | Gemini 3.1 Flash-Lite |
| MMMU-Pro | 76.8% | 51.0% | Gemini 3.1 Flash-Lite |
| SimpleQA Verified | 43.3% | 11.5% | Gemini 3.1 Flash-Lite |
| LiveCodeBench | 72.0% | 34.3% | Gemini 3.1 Flash-Lite |
| MRCR v2 at 128k | 60.1% | 30.6% | Gemini 3.1 Flash-Lite |
That is a real gap. This is not one of those launch pages where the newer model is only a little better. Google's own comparison page shows a meaningful quality jump.
The practical implication is that 3.1 Flash-Lite is not just "2.5 Flash-Lite, but newer." It is closer to a deliberate step up the quality ladder while still trying to stay lighter and cheaper than larger Flash or Pro lanes.
That makes it attractive for tasks where better quality creates immediate business value:
- translation that needs fewer cleanup passes
- extraction pipelines where fewer malformed outputs save downstream effort
- routing and triage layers where a better first decision reduces expensive retries
- lightweight coding or UI-generation assistance where 2.5 Flash-Lite feels too brittle
But those gains do not automatically make 3.1 Flash-Lite the right universal default. You still need to ask whether the task is valuable enough to deserve the cost jump. If a lane exists mostly to keep infrastructure cheap, quality gains that do not change user outcomes are often not worth paying for.
That is also where community reaction becomes useful. Threads in AI Studio and Gemini-related communities are full of two different reactions:
- some users say 3.1 Flash-Lite clearly feels better than 2.5 Flash-Lite
- others try to use Flash-Lite like a primary coding or app-building model and come away disappointed
Both reactions make sense. The model can be stronger than the old lite lane without becoming the right default for every task a team might throw at it.
Preview risk, public limits, and the migration clock
The official rate-limits page adds an important caveat that quick benchmark posts usually skip: preview models may have more restrictive rate limits, and actual capacity may vary.
That warning does not prove Gemini 3.1 Flash-Lite is unstable in your workload. But it does mean you should not treat a preview model like a mature settled baseline without your own evals.
At the same time, the same rate-limits page removes one tempting but wrong claim. The published Batch API tables currently show the same enqueued-token ceilings for Gemini 3.1 Flash-Lite Preview and Gemini 2.5 Flash-Lite across Tier 1, Tier 2, and Tier 3. So if you were hoping the public docs already showed a clean throughput advantage for 3.1, they do not. The migration case for 3.1 rests more on quality than on a public batch-limit edge.
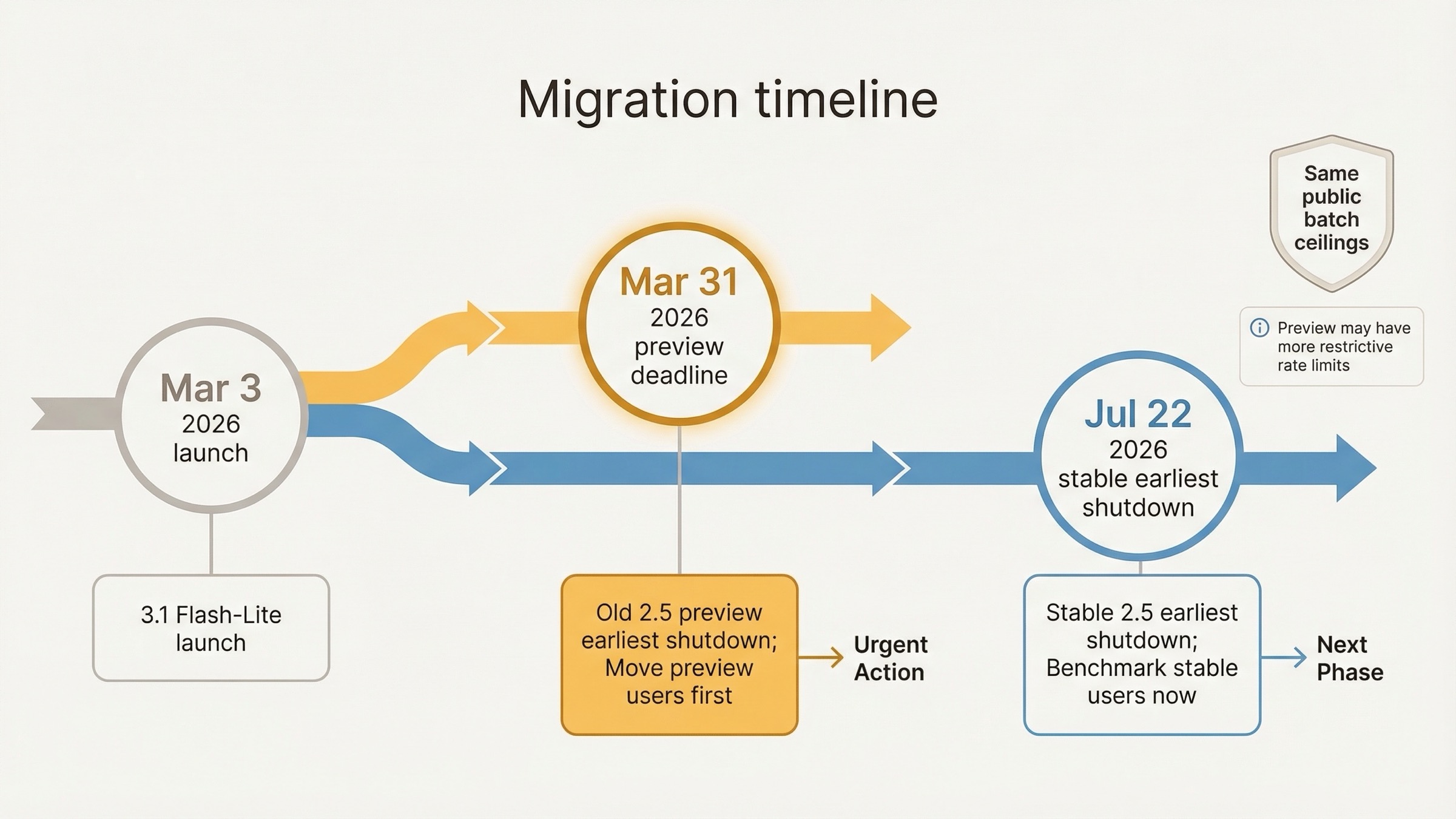
That leaves you with three timing realities:
-
If you are on
gemini-2.5-flash-lite-preview-09-2025, move now.
The deprecations page lists March 31, 2026 as the earliest shutdown date, which makes delay hard to justify. -
If you are on stable
gemini-2.5-flash-lite, you still have room to benchmark.
Google's earliest listed shutdown date is July 22, 2026, not tomorrow. -
If you know a migration is inevitable, do not wait until the last minute to learn the new lane.
The better move is phased adoption now, not panic migration later.
This is why the strongest March 2026 recommendation is not "switch everything" and not "ignore 3.1 until GA." It is "start learning the replacement path now, but keep 2.5 Flash-Lite where its cost advantage still matters."
If rate-limit behavior is a big part of your deployment decision, the current Gemini API rate-limits-per-tier guide is the right follow-up read.
Which workloads should stay, switch, or dual-route
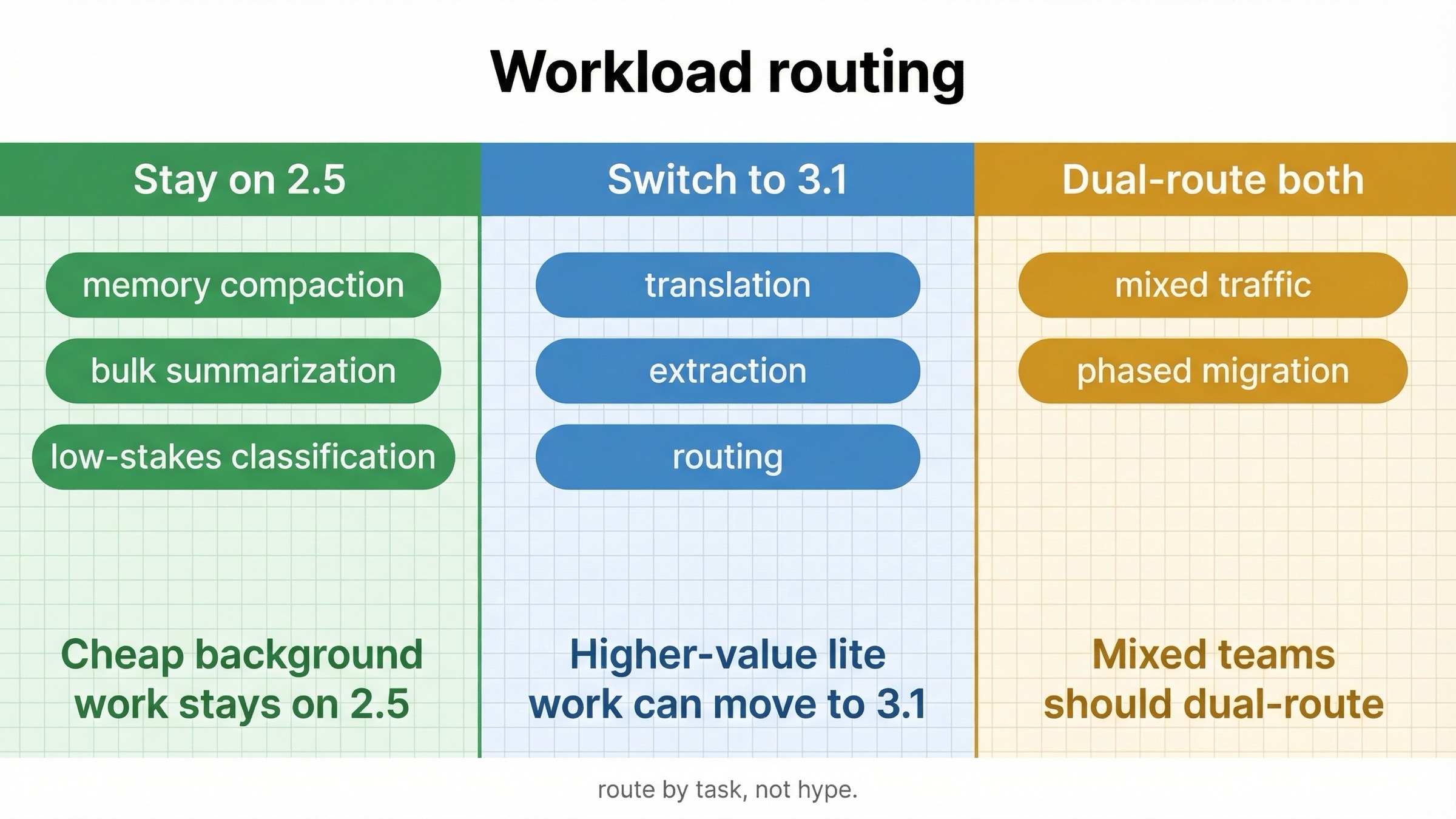
The simplest way to make this comparison useful is to turn it into routing advice.
Stay on Gemini 2.5 Flash-Lite first when:
- the task exists mainly to be cheap
- the model is doing memory compression, log summarization, light classification, or other support-lane work
- the business value of better output quality is low
- stable status and a free standard tier are more important than better benchmarks
Move to Gemini 3.1 Flash-Lite first when:
- you already know 2.5 Flash-Lite is the quality bottleneck
- the task is high volume, but still important enough that better answers save meaningful downstream cost
- you need better performance on translation, extraction, routing, or lightweight code tasks
- you want to begin learning the officially recommended replacement lane before the stable 2.5 shutdown window gets closer
Dual-route both when:
- you have a clear split between cheap background workloads and higher-value lite workloads
- you want to keep compaction and low-value summarization on 2.5 Flash-Lite
- you want better extraction, translation, or decision quality on 3.1 Flash-Lite
- you want to migrate gradually instead of taking a full preview dependency all at once
For many teams, dual routing is the best current answer. It preserves the reason 2.5 Flash-Lite exists while still giving you time to learn the successor lane.
One more warning is worth making explicit: Flash-Lite is still Flash-Lite. Even if 3.1 Flash-Lite is materially better than 2.5 Flash-Lite, it is still a lite model. If your team is expecting it to replace a serious coding-default lane or a heavier reasoning lane without tradeoffs, you are probably benchmarking the wrong class of model. In that case, the right follow-up comparison is not another Flash-Lite page. It is a page about where Flash, Pro, or thinking-level controls change the result, like our Gemini API thinking-level guide.
How to migrate without regretting it
The safest migration plan on March 20, 2026 looks like this:
-
Separate your existing 2.5 Flash-Lite traffic into cheap lanes and value lanes.
Do not benchmark one mixed average. Split out summarization, routing, extraction, translation, coding helpers, and other real tasks. -
Test 3.1 Flash-Lite only where quality could repay the price jump.
If a workflow would save retries, manual cleanup, or downstream model calls, it is a real candidate. If not, leave it on 2.5. -
Benchmark both quality and total cost, not benchmark scores alone.
A better model that forces 3.75x more output cost must reduce enough errors to justify that bill. -
Migrate preview-ID users first, stable-ID users second.
The old preview line has the tighter clock. The stable line still gives you time to plan. -
Keep a fallback until your own traffic proves the new lane.
Since 3.1 Flash-Lite is still preview, do not remove your stable 2.5 route too early.
That is a more defensible plan than either extreme:
- blind full migration because the benchmarks look better
- zero migration because 2.5 Flash-Lite is still cheaper today
The right answer is phased replacement with clear cost and quality thresholds.
FAQ
Is Gemini 3.1 Flash-Lite actually cheaper than Gemini 2.5 Flash-Lite?
No. As of March 20, 2026, the official pricing page lists 3.1 Flash-Lite at \$0.25 input and \$1.50 output per 1M tokens, versus \$0.10 input and \$0.40 output for 2.5 Flash-Lite.
If 3.1 Flash-Lite costs more, why would anyone switch?
Because Google's own benchmark page shows a large quality jump over 2.5 Flash-Lite. If those gains reduce retries, cleanup work, or downstream failures, the higher token price may still be worth it.
Do both models still get grounding?
Yes. On the March 20, 2026 pricing tables, both Flash-Lite models show free Google Search grounding up to 500 RPD and paid-tier free grounding up to 1,500 RPD before overage charges.
Should I migrate right now if I am still on gemini-2.5-flash-lite-preview-09-2025?
Yes. The official deprecations page lists March 31, 2026 as that preview model's earliest shutdown date. That is a much shorter clock than the stable gemini-2.5-flash-lite line.
Should I replace stable 2.5 Flash-Lite everywhere today?
Usually no. The better move is to keep 2.5 Flash-Lite for the cheapest stable workloads, test 3.1 Flash-Lite on the tasks where quality matters, and migrate gradually before the July 22, 2026 earliest shutdown window for the stable line gets close.