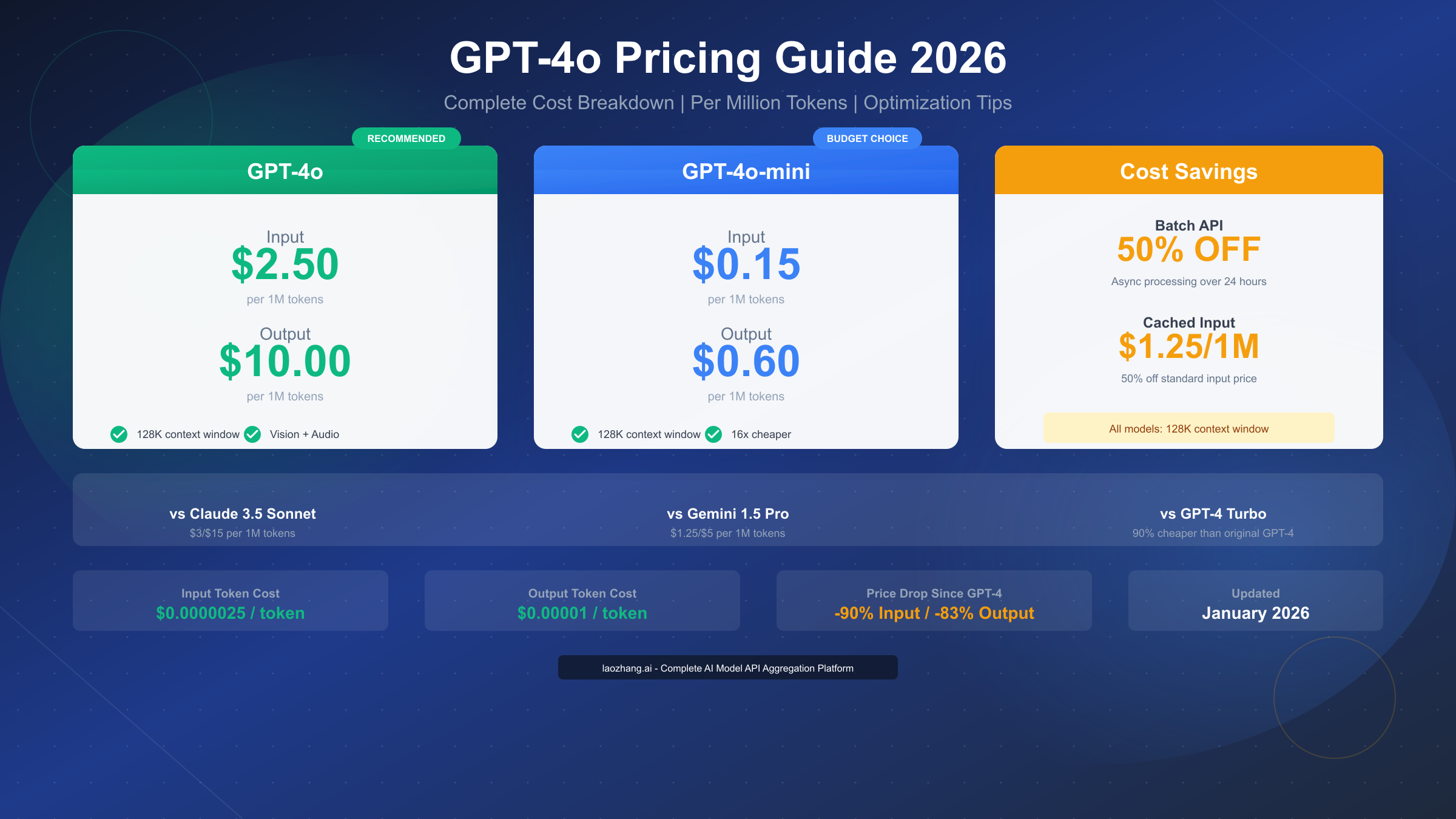
OpenAI's GPT-4o model represents a significant advancement in AI capabilities while offering substantially lower costs than its predecessors. According to OpenAI's official pricing documentation (https://openai.com/api/pricing/ ), GPT-4o costs $2.50 per million input tokens and $10.00 per million output tokens as of January 2026. The more budget-friendly GPT-4o-mini variant costs just $0.15 per million input tokens and $0.60 per million output tokens—making it 16 times cheaper than the standard GPT-4o. OpenAI also offers cached input pricing at $1.25 per million tokens (50% off) and Batch API processing at 50% off both input and output costs, providing multiple pathways to reduce your API expenses.
GPT-4o API Pricing: The Quick Answer
For developers who need immediate pricing information, here's the essential breakdown of GPT-4o costs per million tokens:
| Model | Input Price | Output Price | Cached Input |
|---|---|---|---|
| GPT-4o | $2.50/1M | $10.00/1M | $1.25/1M |
| GPT-4o-mini | $0.15/1M | $0.60/1M | $0.075/1M |
The pricing structure becomes clearer when you understand what these numbers mean in practice. A million tokens roughly equals 750,000 words in English, which means the cost per word for GPT-4o input is approximately $0.0000033. For context, processing a typical 500-word prompt would cost about $0.00167 in input tokens—essentially negligible for most applications.
Per-token breakdown for quick calculations:
- GPT-4o input: $0.0000025 per token
- GPT-4o output: $0.00001 per token
- GPT-4o-mini input: $0.00000015 per token
- GPT-4o-mini output: $0.0000006 per token
The dramatic price difference between GPT-4o and its original GPT-4 predecessor deserves attention. When GPT-4 launched in March 2023, it cost $30 per million input tokens and $60 per million output tokens. The current GPT-4o pricing represents a 92% reduction in input costs and an 83% reduction in output costs—a remarkable demonstration of how rapidly AI pricing continues to decrease.
Complete GPT-4o Pricing Breakdown
Understanding the full GPT-4o pricing structure requires examining all the different pricing tiers and options available through OpenAI's API. This section provides a comprehensive reference for all GPT-4o related costs, helping you accurately budget for your AI integration projects.
Standard API Pricing
The standard pricing applies to real-time API calls where you need immediate responses:
| Pricing Component | GPT-4o | GPT-4o-mini | Notes |
|---|---|---|---|
| Input Tokens | $2.50/1M | $0.15/1M | Regular prompt tokens |
| Output Tokens | $10.00/1M | $0.60/1M | Generated response tokens |
| Cached Input | $1.25/1M | $0.075/1M | 50% discount |
| Context Window | 128K | 128K | Maximum tokens per request |
| Max Output | 16K | 16K | Tokens per response |
Batch API Pricing
OpenAI's Batch API offers significant cost savings for non-time-sensitive workloads. When you can wait up to 24 hours for results, the Batch API provides a straightforward 50% discount on both input and output tokens:
| Batch Component | GPT-4o | GPT-4o-mini |
|---|---|---|
| Batch Input | $1.25/1M | $0.075/1M |
| Batch Output | $5.00/1M | $0.30/1M |
The Batch API is ideal for tasks like data processing, content generation pipelines, and any scenario where real-time response isn't critical. A document processing job that would cost $100 with standard API calls would only cost $50 through the Batch API.
Audio and Vision Pricing
GPT-4o's multimodal capabilities come with additional pricing considerations:
Audio Processing:
- Audio input: $100 per million tokens
- Audio output: $200 per million tokens
Vision Processing:
- Image analysis is included in the standard token pricing
- Images are converted to tokens based on resolution
- A typical 1024x1024 image uses approximately 765 tokens
Context Window Economics
The 128K context window shared by both GPT-4o and GPT-4o-mini represents 128,000 tokens—roughly equivalent to a 300-page book. While this massive context enables powerful use cases, it's important to understand the cost implications:
- Maximum single request (128K input + 16K output): ~$3.52 for GPT-4o
- Same request with GPT-4o-mini: ~$0.029
For applications requiring large context, the cost difference between models becomes even more significant. If you're building a document analysis tool that processes lengthy reports, choosing GPT-4o-mini could reduce your costs by over 100x while still maintaining strong performance for many tasks.
If you need help getting started with the OpenAI API, our comprehensive guide on how to get your OpenAI API key walks through the entire setup process.
GPT-4o vs GPT-4o-mini: Which Should You Choose?
Selecting between GPT-4o and GPT-4o-mini requires understanding not just the price difference, but when each model delivers optimal value. This section provides a practical decision framework based on real-world performance characteristics and cost-effectiveness ratios.

Performance Comparison
Both models share the same 128K context window, but they differ significantly in capabilities:
| Capability | GPT-4o | GPT-4o-mini | Winner |
|---|---|---|---|
| Complex reasoning | Excellent | Good | GPT-4o |
| Code generation | Excellent | Very Good | GPT-4o |
| Simple Q&A | Excellent | Excellent | Tie |
| Content writing | Excellent | Very Good | GPT-4o |
| Data extraction | Excellent | Very Good | GPT-4o |
| Speed (tokens/sec) | ~80 | ~100+ | GPT-4o-mini |
| Vision analysis | Full support | Full support | Tie |
When to Use GPT-4o
Choose GPT-4o for these scenarios:
Complex reasoning tasks represent GPT-4o's primary strength. When your application requires multi-step logical analysis, sophisticated problem decomposition, or nuanced understanding of context, GPT-4o consistently outperforms the mini variant. Legal document analysis, scientific research assistance, and strategic business analysis fall into this category.
Multimodal applications that combine vision, audio, and text benefit from GPT-4o's integrated architecture. While GPT-4o-mini supports vision, GPT-4o handles complex image analysis and audio processing with higher accuracy. Medical image interpretation or detailed visual inspection tasks warrant the premium model.
High-stakes outputs where accuracy is paramount justify GPT-4o's higher cost. Customer-facing applications where errors have significant consequences—financial advice platforms, healthcare information systems, or enterprise decision support tools—benefit from GPT-4o's superior reliability.
When to Use GPT-4o-mini
GPT-4o-mini excels in these situations:
High-volume, cost-sensitive applications benefit tremendously from the 16x lower input cost. A customer service chatbot handling thousands of daily conversations can operate at a fraction of the cost while maintaining satisfactory response quality. At $0.15 per million input tokens, you can process nearly 17 times more requests for the same budget.
Simple task automation like data formatting, basic text transformation, and straightforward Q&A doesn't require GPT-4o's advanced reasoning. Using GPT-4o-mini for these tasks represents smart resource allocation—you're not paying for capabilities you don't need.
Development and testing phases benefit from GPT-4o-mini's lower costs. Building and iterating on prompts, testing integration code, and prototyping features all consume tokens without requiring production-level performance. Many development teams use GPT-4o-mini for testing and only switch to GPT-4o for production deployments.
Speed-critical applications where latency matters more than maximum capability favor GPT-4o-mini's faster response times. Interactive applications, real-time assistants, and user-facing tools where response delay impacts experience often perform better with the faster mini model.
Cost-Effectiveness Decision Matrix
| Monthly Volume | Task Complexity | Recommended Model | Est. Monthly Cost |
|---|---|---|---|
| < 10M tokens | High | GPT-4o | < $125 |
| < 10M tokens | Low-Medium | GPT-4o-mini | < $7.50 |
| 10M-100M tokens | High | GPT-4o + caching | $250-2,500 |
| 10M-100M tokens | Low-Medium | GPT-4o-mini | $15-75 |
| > 100M tokens | Mixed | Hybrid approach | Varies |
The hybrid approach deserves special attention. Many production applications route requests to different models based on complexity detection. A customer service platform might use GPT-4o-mini for 80% of routine queries while escalating complex issues to GPT-4o—optimizing both cost and quality.
Real-World Cost Calculation Examples
Abstract pricing becomes meaningful when translated into practical scenarios. This section presents detailed cost calculations for common GPT-4o use cases, helping you estimate expenses for your specific applications.

Scenario 1: Customer Service Chatbot
A customer service chatbot represents one of the most common GPT-4o applications. Let's calculate monthly costs for a mid-sized business:
Assumptions:
- 500 conversations per day
- Average conversation: 800 input tokens (customer query + context)
- Average response: 400 output tokens
- 30 days per month
Calculation:
Daily tokens: 500 × (800 + 400) = 600,000 tokens
Monthly tokens: 600,000 × 30 = 18,000,000 tokens
GPT-4o cost:
- Input: 15M × \$0.0000025 = \$37.50
- Output: 3M × \$0.00001 = \$30.00
- Total: \$67.50/month
GPT-4o-mini cost:
- Input: 15M × \$0.00000015 = \$2.25
- Output: 3M × \$0.0000006 = \$1.80
- Total: \$4.05/month
The difference is striking: GPT-4o costs 16 times more than GPT-4o-mini for this use case. For a customer service chatbot handling routine queries, GPT-4o-mini at $4.05/month represents exceptional value.
Scenario 2: Document Summarization Service
A legal or business document summarization service processes longer inputs with shorter outputs:
Assumptions:
- 100 documents per day
- Average document: 4,000 input tokens
- Average summary: 500 output tokens
- 30 days per month
Calculation:
Monthly input tokens: 100 × 30 × 4,000 = 12,000,000
Monthly output tokens: 100 × 30 × 500 = 1,500,000
GPT-4o cost:
- Input: 12M × \$0.0000025 = \$30.00
- Output: 1.5M × \$0.00001 = \$15.00
- Total: \$45.00/month
With Batch API (50% off):
- Total: \$22.50/month
Since document summarization doesn't require real-time processing, the Batch API cuts costs in half. This represents an excellent opportunity for cost optimization.
Scenario 3: Developer Code Assistant
Individual developer usage tends toward higher complexity but lower volume:
Assumptions:
- 50 coding requests per day
- Average prompt: 2,000 tokens (code context + question)
- Average response: 800 tokens
- 22 working days per month
Calculation:
Monthly input tokens: 50 × 22 × 2,000 = 2,200,000
Monthly output tokens: 50 × 22 × 800 = 880,000
GPT-4o cost:
- Input: 2.2M × \$0.0000025 = \$5.50
- Output: 0.88M × \$0.00001 = \$8.80
- Total: \$14.30/month per developer
For coding assistance where accuracy significantly impacts productivity, GPT-4o's $14.30 monthly cost per developer represents strong ROI. The time saved from better code suggestions easily justifies the expense.
Scenario 4: Content Generation Pipeline
A content marketing team generating articles at scale:
Assumptions:
- 200 articles per month
- Average prompt: 500 tokens (instructions + brief)
- Average article: 2,000 tokens output
Calculation:
Monthly input tokens: 200 × 500 = 100,000
Monthly output tokens: 200 × 2,000 = 400,000
GPT-4o cost:
- Input: 0.1M × \$0.0000025 = \$0.25
- Output: 0.4M × \$0.00001 = \$4.00
- Total: \$4.25/month
Content generation is remarkably cost-effective because inputs are minimal relative to outputs. Even at scale, GPT-4o content generation costs remain negligible compared to traditional content production.
Scenario 5: Data Analysis Pipeline
Enterprise data processing with large context requirements:
Assumptions:
- 1,000 analysis requests per day
- Average context: 10,000 tokens (data + instructions)
- Average analysis: 1,500 tokens output
- 30 days per month
Calculation:
Monthly input tokens: 1,000 × 30 × 10,000 = 300,000,000
Monthly output tokens: 1,000 × 30 × 1,500 = 45,000,000
GPT-4o standard:
- Input: \$750.00
- Output: \$450.00
- Total: \$1,200/month
With Batch API:
- Total: \$600/month
With GPT-4o-mini + Batch:
- Input: 300M × \$0.000000075 = \$22.50
- Output: 45M × \$0.0000003 = \$13.50
- Total: \$36/month
At enterprise scale, model selection dramatically impacts costs. The same workload ranges from $1,200/month with GPT-4o to $36/month with optimized GPT-4o-mini usage—a 33x difference.
7 Proven Ways to Reduce GPT-4o API Costs
Controlling API costs requires strategic approaches beyond simply choosing cheaper models. These seven optimization strategies, based on production experience, can significantly reduce your GPT-4o expenses while maintaining output quality.
1. Leverage the Batch API for Non-Urgent Tasks
The Batch API's 50% discount represents the easiest cost reduction available. Any workflow that can tolerate 24-hour processing times should use batch processing:
- Content generation pipelines
- Data analysis and extraction
- Document processing queues
- Overnight report generation
- Bulk classification tasks
Implementation is straightforward: instead of individual API calls, you submit jobs as JSON arrays and poll for completion. The cost savings compound significantly at scale.
2. Maximize Cached Input Utilization
Cached inputs cost 50% less than standard inputs. To benefit from caching:
Structure prompts with static prefixes: Place system instructions, few-shot examples, and unchanging context at the beginning of your prompts. OpenAI's caching system works by matching prompt prefixes, so consistent starting content enables cache hits.
Reuse conversation context: In multi-turn conversations, the cumulative context from previous turns often qualifies for cached pricing. Design your conversation flow to maintain consistent context structures.
Centralize common instructions: If multiple requests share the same instructions or examples, structure them identically to maximize cache hit rates.
3. Choose the Right Model for Each Task
Not every request requires GPT-4o's full capabilities. Implement intelligent routing:
Simple tasks → GPT-4o-mini:
- Basic Q&A and FAQ responses
- Text formatting and transformation
- Simple data extraction
- Classification with clear categories
Complex tasks → GPT-4o:
- Multi-step reasoning
- Nuanced analysis
- Creative tasks requiring sophistication
- High-stakes decisions
Many production systems use a complexity classifier to route requests automatically, achieving 70-80% cost savings while maintaining quality where it matters.
4. Optimize Prompts to Reduce Token Usage
Efficient prompting directly reduces costs:
Be concise in instructions: Replace verbose explanations with clear, minimal directives. "Summarize this in 3 bullet points" is cheaper than a paragraph explaining what summarization means.
Use structured outputs: Request JSON or specific formats to reduce unnecessary response verbosity. A structured response with named fields is often shorter than free-form prose.
Limit response length: Use the max_tokens parameter to cap response length when appropriate. For yes/no questions, there's no need to receive lengthy explanations.
Compress context: For long documents, consider preprocessing to extract relevant sections rather than including entire texts.
5. Implement Response Caching
Beyond OpenAI's input caching, implement your own response caching:
Cache identical queries: Store responses for common questions. Customer service bots often receive the same questions repeatedly—cache and return stored responses instead of making new API calls.
Semantic caching: Use embeddings to identify similar (not just identical) queries and return cached responses when similarity exceeds a threshold.
TTL-based invalidation: Cache responses with appropriate time-to-live values based on content freshness requirements.
6. Implement Rate Limiting and Budgets
Prevent runaway costs with technical controls:
Hard spending limits: Set monthly budget caps in your OpenAI dashboard to prevent unexpected charges.
Application-level rate limiting: Limit requests per user, per minute, or per feature to control consumption patterns.
Usage monitoring: Track token consumption in real-time to identify unusual patterns before they become expensive.
7. Consider API Aggregation Services
For teams using multiple AI providers or requiring cost optimization beyond what direct API access provides, aggregation services can offer value. These platforms often provide consistent pricing across providers while handling the complexity of multiple API integrations. For teams needing to compare costs across different models and providers, services like laozhang.ai offer API aggregation with transparent pricing that matches official rates while supporting easy model switching between different providers.
GPT-4o vs Claude vs Gemini: Price Comparison
Understanding how GPT-4o pricing compares to competitors helps inform strategic decisions about which API to use for different workloads. Based on official pricing documentation from each provider as of January 2026:
Complete Price Comparison Table
| Model | Input (per 1M) | Output (per 1M) | Context | Best For |
|---|---|---|---|---|
| OpenAI GPT-4o | $2.50 | $10.00 | 128K | Multimodal, balanced tasks |
| OpenAI GPT-4o-mini | $0.15 | $0.60 | 128K | Budget-conscious apps |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 200K | Coding, analysis |
| Claude 3.5 Haiku | $0.80 | $4.00 | 200K | Fast, affordable |
| Gemini 1.5 Pro | $1.25 | $5.00 | 2M | Long context needs |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M | Speed-critical, high volume |
For detailed information about Claude pricing, see our Claude API pricing guide. Similarly, our Gemini API pricing guide covers Google's offerings in depth.
Price-Performance Analysis
GPT-4o vs Claude 3.5 Sonnet: Claude Sonnet costs 20% more for input ($3.00 vs $2.50) and 50% more for output ($15.00 vs $10.00). However, Claude offers a larger 200K context window and excels in coding benchmarks. For input-heavy workloads, GPT-4o is more economical. For coding tasks specifically, Claude's superior code generation may justify the premium.
GPT-4o vs Gemini 1.5 Pro: Gemini Pro costs 50% less for input ($1.25 vs $2.50) and the same for output ($5.00 vs $10.00). Gemini's 2 million token context window dwarfs GPT-4o's 128K, making it the clear choice for processing extremely long documents. For standard context applications, the cost difference favors Gemini.
Budget Options Compared: GPT-4o-mini at $0.15/$0.60 competes with Claude Haiku ($0.80/$4.00) and Gemini Flash ($0.075/$0.30). Gemini Flash is the cheapest option overall, while GPT-4o-mini offers the best OpenAI-ecosystem compatibility at competitive prices.
When to Choose Each Provider
Choose GPT-4o when:
- You need the OpenAI ecosystem and tool compatibility
- Multimodal capabilities (vision + audio + text) are required
- You're already invested in OpenAI's platform
- Balanced performance across tasks matters most
Choose Claude when:
- Coding assistance is the primary use case
- You need the 200K context window
- Prompt caching (0.1x cost for cache reads) fits your usage pattern
- Long-form analysis and writing are priorities
Choose Gemini when:
- Extremely long context (up to 2M tokens) is required
- Cost is the primary optimization target
- You're in the Google Cloud ecosystem
- Processing large documents or codebases
Strategic Multi-Provider Approach
Many organizations benefit from using multiple providers strategically:
- Primary workload: Choose the provider with best price-performance for your dominant use case
- Specialized tasks: Route specific tasks to providers with relevant strengths
- Failover capability: Multiple provider relationships provide redundancy
- Cost arbitrage: Use cheaper providers for appropriate workloads
For information about understanding OpenAI API costs more broadly, including account management and billing optimization, our dedicated guide provides additional context.
How to Estimate Your GPT-4o Token Usage
Accurate token estimation is essential for budgeting and capacity planning. This section explains how tokens work and provides practical methods for estimating your usage before making API calls.
Understanding Tokens
Tokens are the fundamental units of text processing in language models. For English text, the relationship is approximately:
- 1 token ≈ 4 characters
- 1 token ≈ 0.75 words
- 100 tokens ≈ 75 words
- 1,000 tokens ≈ 750 words
Important variations:
- Code typically uses more tokens per character due to special characters and formatting
- Non-English languages often require more tokens per word
- Numbers and special characters may tokenize inefficiently
Token Estimation Methods
Method 1: Word Count Approximation
For English text, multiply word count by 1.33 to estimate tokens:
Estimated tokens = Word count × 1.33
Example: A 500-word prompt ≈ 665 tokens
Method 2: Character Count Approximation
For mixed content or code, divide character count by 4:
Estimated tokens = Character count ÷ 4
Example: A 2,000-character code snippet ≈ 500 tokens
Method 3: OpenAI's Tokenizer Tool
For precise counting, use OpenAI's official tokenizer at platform.openai.com/tokenizer. This tool shows exactly how your text will be tokenized.
Method 4: Tiktoken Library
For programmatic token counting in Python:
pythonimport tiktoken encoder = tiktoken.encoding_for_model("gpt-4o") tokens = encoder.encode("Your text here") token_count = len(tokens)
Estimating Input vs Output Tokens
Production cost estimation requires predicting both input and output tokens:
Input tokens include:
- System prompt (constant per request)
- User message content
- Conversation history (for multi-turn)
- Any included context or documents
Output tokens include:
- Generated response
- Structured data if using JSON mode
- Any requested formatting
Typical ratios by use case:
| Use Case | Input:Output Ratio |
|---|---|
| Chatbot | 2:1 |
| Summarization | 8:1 |
| Code generation | 3:1 |
| Content writing | 1:4 |
| Q&A | 4:1 |
Monthly Usage Planning
To estimate monthly costs:
-
Identify typical request patterns: How many requests per day? What's the average token count?
-
Calculate daily token consumption:
Daily tokens = Requests × (Avg input + Avg output) -
Project monthly costs:
Monthly cost = Daily tokens × 30 × Token price -
Add buffer: Include 20-30% buffer for usage variance
-
Consider growth: Factor in expected user growth or feature expansion
Frequently Asked Questions About GPT-4o Pricing
How much does GPT-4o cost per token?
GPT-4o costs $0.0000025 per input token and $0.00001 per output token. Expressed per million tokens, that's $2.50 for input and $10.00 for output. Cached inputs cost $0.00000125 per token ($1.25 per million).
Is GPT-4o cheaper than GPT-4?
Yes, significantly. GPT-4o costs 92% less for input and 83% less for output compared to GPT-4's original pricing. GPT-4 cost $30/$60 per million tokens (input/output), while GPT-4o costs $2.50/$10.00.
What's the difference between GPT-4o and GPT-4o-mini?
GPT-4o-mini is a smaller, faster, and cheaper version of GPT-4o. It costs $0.15 per million input tokens (vs $2.50) and $0.60 per million output tokens (vs $10.00)—making it 16x cheaper. Both share the 128K context window, but GPT-4o offers superior reasoning capabilities for complex tasks.
How can I reduce my GPT-4o API costs?
The most effective strategies are: (1) Use the Batch API for 50% off non-urgent tasks, (2) Leverage cached inputs for 50% off repeated prompts, (3) Route simple tasks to GPT-4o-mini, (4) Optimize prompts to reduce token usage, and (5) Implement response caching for repeated queries.
Does GPT-4o charge differently for images?
Image analysis is included in the standard token pricing. Images are converted to tokens based on their resolution—a 1024x1024 image uses approximately 765 tokens. Audio processing uses separate pricing: $100 per million tokens for input and $200 per million tokens for output.
How does GPT-4o pricing compare to Claude and Gemini?
GPT-4o ($2.50/$10.00 per million) is cheaper than Claude 3.5 Sonnet ($3.00/$15.00) for both input and output. Gemini 1.5 Pro ($1.25/$5.00) is cheaper than GPT-4o but offers a much larger 2M context window. For budget options, Gemini Flash ($0.075/$0.30) is cheapest, followed by GPT-4o-mini ($0.15/$0.60).
Is there a free tier for GPT-4o?
OpenAI doesn't offer a free tier for API access. New accounts receive $5 in credits that expire after 3 months. ChatGPT Plus subscribers ($20/month) get access to GPT-4o through the chat interface, but API usage is billed separately based on token consumption.
Conclusion: Making Smart GPT-4o Pricing Decisions
GPT-4o's pricing at $2.50 per million input tokens and $10.00 per million output tokens represents remarkable value for state-of-the-art AI capabilities. The key to controlling costs lies in strategic model selection, optimization techniques, and understanding your specific usage patterns.
Key takeaways for cost-effective GPT-4o usage:
-
Use GPT-4o-mini for routine tasks—the 16x cost reduction makes it ideal for high-volume, lower-complexity workloads
-
Leverage the Batch API whenever real-time response isn't required—50% savings add up quickly at scale
-
Structure prompts for caching—consistent prompt prefixes enable 50% cached input discounts
-
Monitor and route intelligently—implement complexity-based routing to use premium models only where they add value
-
Compare providers for your specific needs—GPT-4o isn't always the most cost-effective choice for every task
The AI pricing landscape continues to evolve rapidly, with costs declining and capabilities expanding. The strategies outlined in this guide provide a foundation for managing GPT-4o costs effectively, but staying current with pricing changes from OpenAI and competitors ensures you're always making informed decisions.
For additional resources on AI API pricing and optimization, the official documentation at https://docs.laozhang.ai/ provides comprehensive guides for managing costs across multiple providers.