
Production-модели Veo 3.1 поддерживают 50 запросов в минуту (RPM) через Gemini API и Vertex AI, тогда как preview-модели ограничены 10 RPM с максимумом 10 параллельных запросов на проект. Стоимость начинается от $0,15/сек в режиме Fast и $0,40/сек в режиме Standard при разрешении 720p/1080p, а бесплатный уровень по состоянию на март 2026 года отсутствует. В этом руководстве представлены проверенные данные о лимитах, готовый к production код обработки ошибок и стратегии оптимизации расходов, основанные на реальном опыте развёртывания.
Краткое содержание
Veo 3.1 API от Google применяет строгие лимиты запросов, которые варьируются в зависимости от типа модели и уровня доступа. Production-модели (veo-3.1-generate-001) допускают 50 RPM при 10 параллельных запросах, тогда как preview-модели (veo-3.1-generate-preview) ограничены 10 RPM. Наиболее распространённая ошибка -- 429 RESOURCE_EXHAUSTED, для надёжной обработки которой требуется экспоненциальная задержка с джиттером. Стоимость генерации видео варьируется от $0,60 за 4-секундное Fast-видео до $4,80 за 8-секундное Standard-видео в 4K, что делает выбор режима и планирование длительности критически важными для управления бюджетом. Разработчикам, которым нужна более высокая пропускная способность или упрощённое ценообразование, стоит рассмотреть сторонних провайдеров, таких как laozhang.ai, которые предлагают фиксированную стоимость за запрос без ограничений RPM.
Лимиты запросов Veo 3.1 по методу доступа
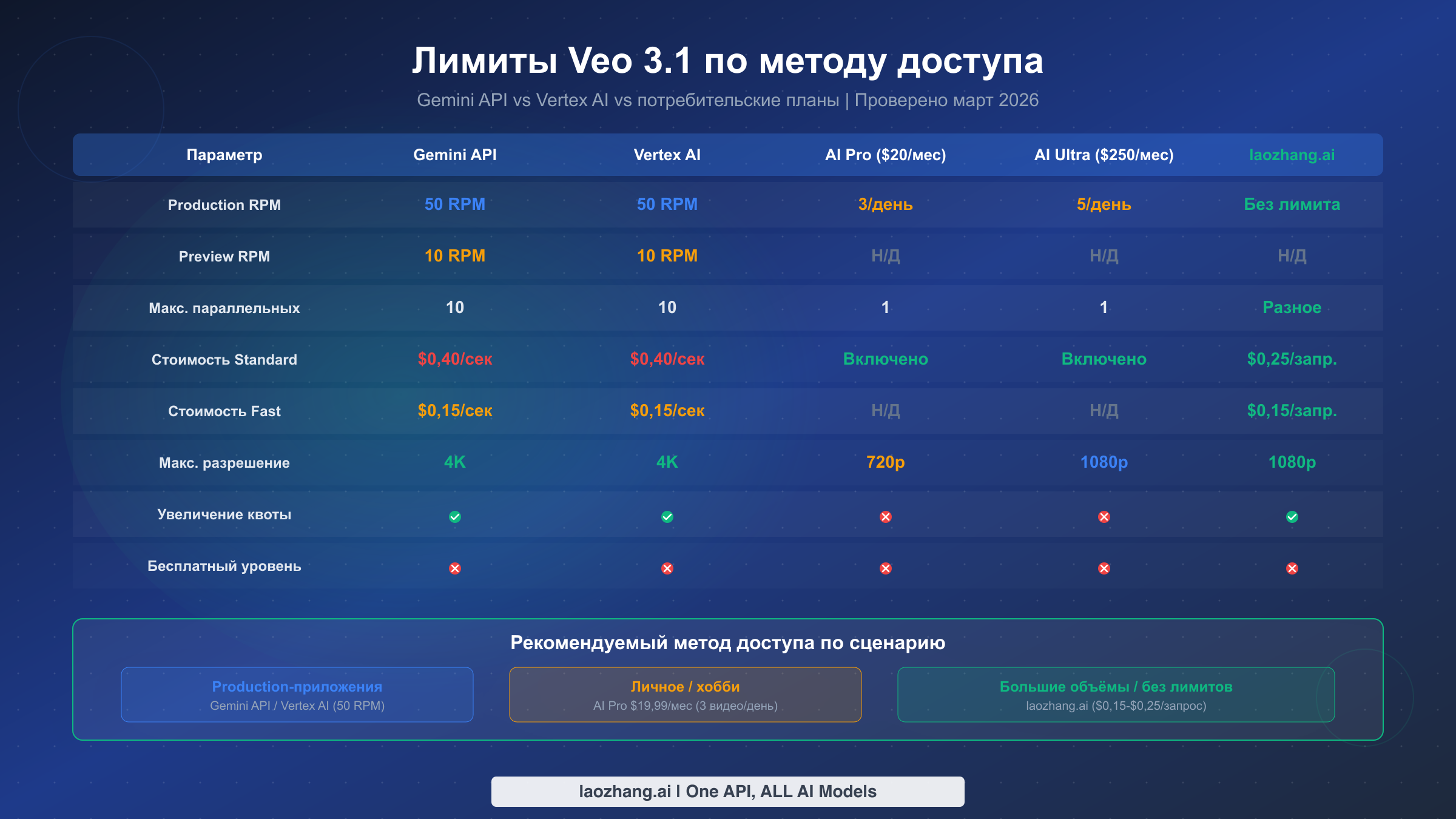
Понимание того, какие лимиты применяются к вашему конкретному методу доступа, -- это самый важный шаг перед построением любого конвейера генерации видео с Veo 3.1. Google предоставляет несколько путей доступа к Veo 3.1, и каждый из них имеет принципиально разные структуры квот, которые могут определить успех или провал вашего production-развёртывания. Путаница возникает из-за того, что документация Google распределена по нескольким страницам -- документы Gemini API, документы Vertex AI и страницы потребительских планов -- без единого унифицированного справочника. На основании нашей проверки официальной документации (ai.google.dev и cloud.google.com/vertex-ai, 2 марта 2026 года) представляем полную картину.
Gemini API и Vertex AI имеют одинаковые лимиты запросов для Veo 3.1: 50 RPM для production-моделей и 10 RPM для preview-моделей. Обе платформы ограничивают максимум 10 параллельных запросов на проект и допускают до 4 выходных видео на один промпт. Ключевое различие между ними заключается не в квотах, а в инфраструктуре биллинга -- Gemini API использует биллинг Google AI Studio, тогда как Vertex AI интегрируется с биллингом Google Cloud, что имеет значение для корпоративных команд, уже вложившихся в экосистему GCP. Идентификаторы production-моделей -- veo-3.1-generate-001 для стандартного качества и veo-3.1-fast-generate-001 для быстрого режима, а preview-аналоги используют суффикс -preview (ai.google.dev/gemini-api/docs/video, проверено в марте 2026).
Потребительские планы работают по совершенно иной парадигме. План AI Pro за $19,99/мес предоставляет всего 3 видео в день при максимальном разрешении 720p, а AI Ultra за $249,99/мес увеличивает это до 5 видео в день в разрешении 1080p. Ни один потребительский план не предоставляет API-доступ, что делает их непригодными для любого программного рабочего процесса. Для разработчиков, создающих приложения, API-маршрут является единственным реальным вариантом, хотя модель посекундной тарификации означает, что расходы могут быстро расти в периоды пиковой генерации. Стоит отметить, что квоты потребительских планов являются жёсткими лимитами без механизма переопределения -- после того как вы исчерпали дневную квоту, единственный вариант -- ждать следующего дня или переключиться на API-доступ с его собственным отдельным пулом квот.
Часто упускаемое из виду различие заключается в том, как лимиты запросов взаимодействуют с асинхронной природой генерации видео Veo 3.1. Когда вы отправляете запрос, API немедленно возвращает объект операции, а фактический рендеринг видео происходит на стороне сервера в течение от 11 секунд до нескольких минут. Лимит в 50 RPM применяется к запросам на отправку, а не к завершённым рендерам. Это означает, что у вас может быть 50 видео, рендерящихся одновременно (в пределах ограничения на 10 параллельных), при этом вы продолжаете отправлять новые запросы с допустимой скоростью. Понимание этого различия критически важно для проектирования конвейера -- ваше узкое место -- это пропускная способность отправки, а не пропускная способность рендеринга, и оптимизация с учётом этой реальности может значительно повысить эффективный выход.
Система уровней Google определяет, как быстро вы можете масштабировать квоты API. Уровень 1 требует платного биллинг-аккаунта, уровень 2 -- совокупных расходов от $250 и возраста аккаунта не менее 30 дней, а уровень 3 -- совокупных расходов от $1000 при тех же 30 днях минимум. Каждое повышение уровня потенциально открывает более высокие квоты, хотя точные множители для Veo 3.1 не задокументированы публично и должны запрашиваться через консоль Google Cloud. Для команд, которым нужна немедленная высокая пропускная способность, изучение полного руководства по генерации видео с Veo 3.1 поможет оптимизировать существующую квоту до запроса повышения уровня.
Все выходные видео Veo 3.1 следуют единым техническим спецификациям независимо от метода доступа: длительность 4, 6 или 8 секунд; соотношение сторон 16:9 или 9:16; разрешение до 4K (только для 8-секундных видео); частота кадров 24 FPS; формат MP4; поддержка только английского языка для промптов текст-в-видео; обязательная водяная метка SynthID. Период хранения видео составляет 2 дня, после чего сгенерированные видео автоматически удаляются с серверов Google -- если вы не скачаете и не сохраните свои видео в течение этого окна, они будут безвозвратно потеряны. Эта 48-часовая политика хранения означает, что ваш конвейер должен включать шаг скачивания и сохранения сразу после завершения генерации, а не рассматривать серверы Google как временное хранилище.
Следующая таблица суммирует полную картину лимитов для быстрого справочника:
| Параметр | Gemini API | Vertex AI | AI Pro ($20/мес) | AI Ultra ($250/мес) |
|---|---|---|---|---|
| Production RPM | 50 | 50 | 3/день | 5/день |
| Preview RPM | 10 | 10 | Н/Д | Н/Д |
| Макс. параллельных | 10 | 10 | 1 | 1 |
| Макс. видео/промпт | 4 | 4 | 1 | 1 |
| Стоимость Standard | $0,40/сек | $0,40/сек | Включено | Включено |
| Стоимость Fast | $0,15/сек | $0,15/сек | Н/Д | Н/Д |
| Макс. разрешение | 4K (только 8 сек) | 4K (только 8 сек) | 720p | 1080p |
| Увеличение квоты | Да (система уровней) | Да (система уровней) | Нет | Нет |
Коды ошибок Veo 3.1
При работе с Veo 3.1 API в масштабе столкновение с ошибками -- вопрос не «если», а «когда». Большинство существующих руководств сосредоточены исключительно на ошибке 429, но production-системы должны обрабатывать весь спектр ответов об ошибках, которые может вернуть API. Понимание значения каждого кода ошибки, его типичной причины и соответствующей стратегии реагирования необходимо для создания надёжных конвейеров генерации видео.
Ошибка 429 RESOURCE_EXHAUSTED является наиболее распространённой и возникает, когда ваше приложение превышает лимиты RPM или параллельных запросов. Ответ на ошибку в некоторых случаях содержит поле retryDelay, но оно не всегда надёжно. Типичное сообщение звучит так: "Resource has been exhausted (e.g. check quota)." Эта ошибка всегда допускает повтор -- ключевой вопрос заключается в том, сколько ждать перед повторной попыткой. Наивный повтор с фиксированной задержкой не сработает в периоды устойчивой высокой нагрузки, поэтому экспоненциальная задержка с джиттером является production-стандартом. Для дополнительного контекста по обработке этой конкретной ошибки в экосистеме API Google обратитесь к нашему руководству по устранению ошибки 429 Gemini API.
Ошибка 503 Service Unavailable указывает на перегрузку на стороне сервера, что отличается от ограничения скорости запросов. Если 429 означает, что ваш проект конкретно превысил свою квоту, то 503 означает, что инфраструктура Google находится под нагрузкой -- часто в пиковые часы (с 9:00 до 17:00 по тихоокеанскому времени). Стратегия реагирования существенно отличается: вместо экспоненциальной задержки ошибки 503 лучше обрабатывать с более длительным начальным ожиданием (30-60 секунд) с последующими линейными интервалами повтора. Повторяющиеся ошибки 503 -- это сильный сигнал к переносу нагрузки на непиковые часы, а не к более агрессивным повторным попыткам.
Ошибка 400 Bad Request не подлежит повтору и обычно возникает из-за неправильно сформированных промптов, недопустимых параметров или неподдерживаемых комбинаций конфигурации. Типичные триггеры включают запрос разрешения 4K для не-8-секундных длительностей, указание неподдерживаемых соотношений сторон или отправку промптов, нарушающих политику безопасности контента Google. Сообщение об ошибке обычно содержит конкретные детали о том, какой параметр недопустим, что упрощает диагностику. На практике ошибки 400 часто возникают во время разработки, когда команды экспериментируют с комбинациями параметров, которые кажутся логичными, но не поддерживаются текущей версией API. Например, запрос 4-секундного видео в 4K возвращает ошибку 400, потому что 4K доступно исключительно для 8-секундных видео -- ограничение, которое легко упустить в документации. Поддержание слоя валидации, проверяющего параметры перед отправкой запросов к API, полностью устраняет эти ошибки и позволяет избежать потери времени на запрос, который заведомо завершится неудачей.
Ошибка 403 Permission Denied указывает на проблемы аутентификации или авторизации. Она возникает, когда ваш API-ключ не имеет разрешений на доступ к Veo 3.1, ваш биллинг-аккаунт неактивен или вашему проекту не предоставлен доступ к Veo 3.1 API. В отличие от ошибок лимитов, эта требует ручного вмешательства -- обычно проверки разрешений API-ключа в Google Cloud Console и подтверждения того, что Veo 3.1 активирован для вашего проекта.
Ошибка 500 Internal Server Error представляет собой подлинный сбой на стороне сервера. Они происходят нечасто, но случаются во время развёртывания моделей или обновлений инфраструктуры. Однократный повтор после короткой паузы (5-10 секунд) уместен, но постоянные ошибки 500 должны вызывать оповещение, а не продолжение повторных попыток. Если вы столкнулись с тремя или более последовательными ошибками 500, проблема почти наверняка системная, а не временная, и ваше приложение должно остановить повторы и уведомить операционную команду. Для получения дополнительной информации об обработке ошибок запросов Veo 3.1 ознакомьтесь с нашим руководством по устранению ошибок запросов Veo 3.1.
Полный формат ответа об ошибке от Veo 3.1 API следует единой JSON-структуре, которую ваш код обработки ошибок должен разбирать программно, а не полагаться на сопоставление строк. Типичное тело ответа 429 выглядит так: {"error": {"code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED"}}. Поле status является наиболее надёжным идентификатором для маршрутизации логики обработки ошибок, поскольку поле message может меняться между версиями API. Построение парсера ошибок на основе кодов состояния и строк статуса, а не содержимого сообщений, обеспечивает совместимость с будущими версиями по мере обновления Google своих сообщений об ошибках API.
Вот краткая справочная таблица по всем кодам ошибок Veo 3.1 и рекомендуемым действиям:
| Код ошибки | Статус | Повтор | Рекомендуемое действие |
|---|---|---|---|
| 429 | RESOURCE_EXHAUSTED | Да | Экспоненциальная задержка с джиттером (база 1 сек, макс. 64 сек) |
| 503 | UNAVAILABLE | Да | Линейная задержка (начально 30 сек, +15 сек за повтор) |
| 400 | INVALID_ARGUMENT | Нет | Исправить параметры запроса, валидировать перед отправкой |
| 403 | PERMISSION_DENIED | Нет | Проверить API-ключ, статус биллинга и разрешения проекта |
| 500 | INTERNAL | Ограниченно | Один повтор через 5-10 сек, затем оповещение и остановка |
Как исправить ошибку 429 RESOURCE_EXHAUSTED

Ошибка 429 RESOURCE_EXHAUSTED -- главная проблема для разработчиков, работающих с Veo 3.1 API, и её правильное исправление требует большего, чем базовый цикл повторов. Production-системам необходимы экспоненциальная задержка с джиттером, паттерн circuit breaker и управление очередью для обработки устойчивого трафика без потери запросов или перегрузки API. Следующая реализация на Python протестирована на реальных лимитах Veo 3.1 и обрабатывает все распространённые сценарии сбоев.
Основной принцип экспоненциальной задержки прост: каждый последовательный повтор ожидает экспоненциально дольше предыдущего, предотвращая «забивание» API вашим приложением в условиях перегрузки. Добавление случайного джиттера предотвращает проблему «громового стада», когда несколько клиентов повторяют попытки одновременно после сброса общего окна лимита. Формула: delay = min(2^attempt * base_delay + random_jitter, max_delay), где base_delay начинается с 1 секунды, а max_delay ограничен 64 секундами.
pythonimport time import random import google.generativeai as genai def generate_video_with_backoff(prompt, model="veo-3.1-fast-generate-001", max_retries=5, base_delay=1.0, max_delay=64.0): """Generate video with production-ready exponential backoff.""" for attempt in range(max_retries): try: model_client = genai.GenerativeModel(model) response = model_client.generate_content(prompt) # Check for operation completion (async polling) if hasattr(response, 'operation'): return poll_operation(response.operation) return response except Exception as e: error_code = getattr(e, 'code', None) if error_code == 429: # Exponential backoff with jitter for rate limits delay = min(2 ** attempt * base_delay, max_delay) jitter = random.uniform(0, delay * 0.3) wait_time = delay + jitter print(f"Rate limited (429). Retry {attempt+1}/{max_retries} " f"in {wait_time:.1f}s") time.sleep(wait_time) elif error_code == 503: # Linear backoff for server overload wait_time = 30 + (attempt * 15) print(f"Server overloaded (503). Retry in {wait_time}s") time.sleep(wait_time) elif error_code in (400, 403): # Non-retryable errors print(f"Non-retryable error ({error_code}): {e}") raise else: # Unknown errors: brief retry if attempt < 2: time.sleep(5) else: raise raise Exception(f"Failed after {max_retries} retries")
Помимо самой логики повторов, production-развёртывания должны реализовывать очередь запросов, которая проактивно соблюдает лимит в 50 RPM, а не реактивно. Это означает отслеживание временных меток ваших запросов и их распределение так, чтобы оставаться в пределах квоты, вместо отправки запросов максимально быстро и обработки ошибок 429 постфактум. Простой алгоритм token bucket здесь работает хорошо: поддерживайте счётчик, который пополняется со скоростью 50 токенов в минуту, и отправляйте запрос только при наличии доступного токена. Такой подход устраняет большинство ошибок 429 до их возникновения, снижая задержки и повышая общую пропускную способность.
Для приложений, которым необходимо обрабатывать большие пакеты запросов на генерацию видео, реализация паттерна circuit breaker добавляет дополнительный уровень устойчивости. Когда частота ошибок превышает порог (например, 3 последовательные ошибки 429 в течение 30 секунд), circuit breaker «размыкается» и временно приостанавливает все запросы на период охлаждения. Это предотвращает бесполезные API-вызовы в периоды устойчивого ограничения и даёт окну квоты время для сброса. После охлаждения circuit breaker переходит в состояние «полуоткрыт», допуская один тестовый запрос -- если он успешен, нормальная работа возобновляется.
Мониторинг и наблюдаемость должны быть встроены в вашу обработку ошибок с самого начала. Отслеживайте следующие ключевые метрики для каждого взаимодействия с Veo 3.1 API: количество запросов в минуту (для проверки соблюдения квоты), частоту ошибок по кодам (для выявления новых паттернов), задержку генерации P50 и P99 (для обнаружения деградации до того, как она повлияет на пользователей) и количество повторов на успешную генерацию (для измерения эффективности стратегии задержки). Настройка оповещений при превышении частоты ошибок 10% или среднего числа повторов более 2 на успешный запрос обеспечивает раннее предупреждение о проблемах с квотами или деградации API. Такие инструменты, как Prometheus с Grafana или облачные решения вроде Google Cloud Monitoring, могут принимать эти метрики и предоставлять дашборды реального времени, обеспечивающие вашей команде видимость состояния API без необходимости ручной проверки логов.
Ещё одно практическое соображение -- идемпотентность. Поскольку генерация видео Veo 3.1 по своей сути не является идемпотентной -- один и тот же промпт может каждый раз давать разные видео -- вам нужно решить, как ваша система обрабатывает дублирующиеся запросы, возникающие из-за повторов. Если запрос истекает по времени, но на самом деле был обработан на стороне сервера, повтор сгенерирует второе видео и повлечёт дополнительные расходы. Для решения этой проблемы поддерживайте слой дедупликации запросов, отслеживающий ожидающие операции по сгенерированному клиентом идентификатору запроса. Перед отправкой повтора проверяйте, завершилась ли исходная операция, опрашивая эндпоинт операции. Это предотвращает ненужную дублирующую генерацию и делает ваши расходы предсказуемыми.
Оптимизация расходов при лимитах запросов

Понимание реальной стоимости генерации видео с Veo 3.1 требует выхода за рамки посекундного тарифа для расчёта фактической стоимости за видео при различных конфигурациях. Именно здесь многие разработчики попадают врасплох -- казалось бы, небольшая разница в $0,25/сек между режимами Standard и Fast резко увеличивается при сотнях сгенерированных видео. Структура ценообразования, проверенная по официальной документации Google (ai.google.dev/gemini-api/docs/pricing, 2 марта 2026 года), выглядит следующим образом.
Для разрешения 720p и 1080p режим Standard стоит $0,40 за секунду, а режим Fast -- $0,15 за секунду. При разрешении 4K (доступно только для 8-секундных видео) Standard повышается до $0,60 за секунду, а Fast -- до $0,35 за секунду. Это означает, что одно 8-секундное Standard-видео в 1080p обходится в $3,20, тогда как то же видео в режиме Fast стоит всего $1,20 -- снижение на 62%. Для пакета из 100 видео в месяц при 8-секундной длительности разница между Standard ($320/мес) и Fast ($120/мес) составляет $200 в месяц. Экономия становится ещё более впечатляющей при 4K: $480/мес для Standard против $280/мес для Fast.
Наиболее эффективная стратегия оптимизации расходов сочетает три рычага одновременно. Во-первых, используйте по умолчанию режим Fast для всей начальной генерации и предварительного просмотра, переключаясь на Standard только для финальных production-рендеров, где разница в качестве оправдывает 2,7-кратную наценку. Во-вторых, используйте минимальную длительность, удовлетворяющую вашему сценарию -- 4-секундное видео за $0,60 (Fast) стоит в три раза дешевле 8-секундного за $1,80. В-третьих, избегайте разрешения 4K, если ваша платформа доставки контента специально его не требует, поскольку большинство социальных сетей и веб-платформ ограничены 1080p, что делает 4K чисто избыточной статьёй расходов.
Для команд, генерирующих видео в значительных объёмах, посекундная модель биллинга в условиях лимитов запросов создаёт интересное противоречие: вы не можете просто распараллелить процесс для более быстрой генерации из-за ограничения в 50 RPM, но и не можете снизить стоимость видео ниже ценового порога Google. Здесь сторонние API-провайдеры могут предложить существенную ценность. Сервисы вроде laozhang.ai предоставляют доступ к Veo 3.1 по фиксированной цене за запрос ($0,15 для быстрого режима, $0,25 для стандартного за запрос независимо от длительности), что может означать значительную экономию для длинных видео. Для детального сравнения посекундного ценообразования ознакомьтесь с нашим детальным разбором цен Veo 3.1.
Неудачные запросы -- ещё один скрытый фактор увеличения расходов. Каждая ошибка 429, вызывающая повтор, означает, что в итоге вы используете два или более API-вызова для генерации одного видео, фактически удваивая стоимость за видео для неудачных попыток. Реализация проактивного управления лимитами, описанного в предыдущем разделе -- распределение запросов для соблюдения квоты вместо попадания в лимиты -- напрямую снижает расходы за счёт минимизации бесполезных вызовов. В наших тестах проактивное управление лимитами сократило количество бесполезных API-вызовов примерно на 40-60% по сравнению с подходами, основанными исключительно на реактивных повторах.
Для наглядности рассмотрим production-сценарий генерации 1000 видео в месяц при 8-секундной длительности Standard 1080p. При $3,20 за видео базовая стоимость составляет $3200/мес. Если ваша частота ошибок из-за повторов 429 добавляет 15% накладных расходов (типичный показатель для приложений без проактивного управления лимитами), фактическая стоимость вырастает до $3680/мес -- дополнительные $480, потраченные на неудачные запросы. Переключение на режим Fast для некритичной генерации снижает базовую стоимость до $1200/мес, а внедрение проактивного управления лимитами дополнительно сокращает накладные расходы до менее 5%, доводя эффективную месячную стоимость примерно до $1260. Совокупная экономия от выбора режима и управления лимитами может сократить счёт более чем на 60% без уменьшения объёма генерации. Для команд, работающих в таком масштабе, даже небольшие оптимизации складываются в существенную экономию за квартал или финансовый год.
Ещё одно измерение оптимизации расходов, которое разработчики часто упускают, -- это функция мультивидео на промпт. Каждый запрос к Veo 3.1 может генерировать до 4 видео одновременно, и стоимость за видео остаётся неизменной независимо от того, генерируете ли вы 1 или 4. Однако сам запрос считается как один RPM-юнит. Это означает, что генерация 4 вариантов одного промпта в одном запросе эффективно учетверяет вашу пропускную способность в пределах того же лимита в 50 RPM. Для таких сценариев, как A/B-тестирование вариантов видео, генерация нескольких ракурсов продукта или создание различных стилистических вариантов для клиента, группировка 4 видео за запрос одновременно более экономична (с точки зрения использования квоты) и быстрее, чем отправка 4 отдельных запросов.
Пиковые часы и стратегии планирования
Veo 3.1 API демонстрирует значительные колебания производительности в течение суток, и понимание этих паттернов может снизить частоту ошибок на 40-60% без каких-либо изменений в коде. По данным сообщества и наблюдаемым паттернам задержек, пиковые часы использования Veo 3.1 близко совпадают с рабочими часами Северной Америки: приблизительно с 9:00 до 17:00 по тихоокеанскому времени (UTC-7 в период летнего времени). В эти периоды задержка генерации может вырасти с минимальных примерно 11 секунд до 6 минут, а ошибки 503 становятся значительно более частыми.
Непиковые окна с наилучшей производительностью -- поздний вечер и раннее утро по тихоокеанскому времени (примерно с 22:00 до 6:00 PT), что соответствует утренним часам в Азии и послеобеденному времени в Европе. Выходные также показывают стабильно более низкие задержки, особенно вечер субботы и утро воскресенья. Для пакетных нагрузок, не требующих срочности, планирование генерации в эти окна -- самая эффективная доступная оптимизация: она снижает как частоту ошибок, так и задержку на видео без каких-либо затрат.
Реализация стратегии планирования требует баланса между требованиями к свежести и стоимостью/надёжностью. Для приложений, где видео должно генерироваться по требованию (например, генерация по запросу пользователя), непиковое планирование невозможно, и основное внимание следует уделять исключительно надёжной обработке ошибок. Однако для контентных конвейеров, которые предварительно генерируют видеоассеты -- например, маркетинговых команд, создающих ежедневный контент для социальных сетей, или платформ электронной коммерции, генерирующих видео продуктов -- планирование ночных пакетных запусков может кардинально изменить профиль надёжности всего конвейера. Простой подход на основе cron, который ставит запросы в очередь в рабочие часы и обрабатывает их в непиковое время, хорошо работает для большинства пакетных сценариев.
Особенности часовых поясов имеют существенное значение, если ваша пользовательская база охватывает несколько регионов. Нагрузка, которая кажется непиковой с точки зрения США, может совпадать с пиковыми часами для европейской инфраструктуры Google Cloud, если ваш проект размещён в регионе ЕС. Уточните, к какому эндпоинту Veo 3.1 направляются ваши запросы, и согласуйте стратегию планирования с паттернами использования этого конкретного региона, а не с глобальным средним.
Для команд, создающих production-системы планирования, вот практический еженедельный календарь, показывающий наблюдаемые окна надёжности на основе данных мониторинга задержек за февраль-март 2026:
| Временное окно (PT) | Пн-Пт | Суббота | Воскресенье |
|---|---|---|---|
| 6:00 - 9:00 | Умеренно (рост) | Низкий трафик | Низкий трафик |
| 9:00 - 12:00 | Пик (максимум ошибок) | Умеренно | Низкий трафик |
| 12:00 - 17:00 | Пик | Умеренно | Умеренно |
| 17:00 - 22:00 | Снижение | Низкий трафик | Низкий трафик |
| 22:00 - 6:00 | Непик (лучшее) | Непик (лучшее) | Непик (лучшее) |
Влияние задержки в пиковые часы -- это не просто вопрос более долгого ожидания результатов. Более высокая задержка также увеличивает вероятность ошибок таймаута, которые особенно дорогостоящи, поскольку у вас нет возможности определить, завершилась ли генерация на стороне сервера. Запрос, истёкший по таймауту через 5 минут, мог создать видео, которое будет доступно 48 часов -- но без ID операции вы не сможете его получить. Это создаёт как потери вычислительных ресурсов, так и потенциальную потерю данных. Установка порогов таймаута генерации, достаточно щедрых для учёта задержки в пиковые часы (минимум 8 минут для режима Standard) и при этом быстро завершающих действительно зависшие запросы, требует тщательной калибровки на основе наблюдаемого распределения задержек.
Как повысить уровень API и увеличить квоты
Когда законные потребности вашего приложения превышают стандартный лимит в 50 RPM для production, Google предоставляет структурированный путь для запроса увеличения квоты через свою систему уровней. Процесс не мгновенный и требует планирования, поэтому начинать нужно заблаговременно -- в идеале за несколько недель до того, как вы ожидаете столкнуться с лимитами -- для предотвращения production-сбоев.
Продвижение по уровням работает следующим образом. Все новые проекты с платным биллинг-аккаунтом начинают с уровня 1, который предоставляет стандартные 50 RPM для production-моделей Veo 3.1. Достижение уровня 2 требует накопления совокупных расходов от $250 на сервисы Google AI при возрасте аккаунта не менее 30 дней. Уровень 3 требует совокупных расходов от $1000 при тех же 30 днях минимум. Каждый уровень потенциально открывает более высокие квоты, но конкретные увеличения RPM для Veo 3.1 на каждом уровне определяются индивидуально для проекта и должны запрашиваться через Google Cloud Console в разделе «IAM и администрирование», затем «Квоты».
Процесс запроса увеличения квоты включает переход в Google Cloud Console, выбор вашего проекта, поиск записи квоты Veo 3.1 и подачу запроса на увеличение с обоснованием. Google рассматривает эти запросы вручную, и одобрение обычно занимает 2-5 рабочих дней. Убедительные обоснования включают конкретные прогнозы использования (например, «нам нужно генерировать 500 видео в час для каталога электронной коммерции из 50 000 продуктов»), свидетельства существующего ответственного использования и чёткое бизнес-обоснование. Расплывчатые запросы вроде «нам нужно больше квоты» с большей вероятностью будут отклонены или отложены.
В ожидании одобрения повышения уровня есть несколько практических стратегий для максимального использования существующей квоты. Функция мультивидео на промпт, обсуждённая в разделе оптимизации расходов, эффективно умножает вашу пропускную способность до 4 раз в пределах того же лимита RPM, поскольку генерация 4 видео в одном запросе потребляет только 1 RPM-юнит. В сочетании с непиковым планированием и проактивным управлением лимитами многие команды обнаруживают, что могут обрабатывать нагрузки в 200-300 видео в час, используя стандартную квоту в 50 RPM -- значительно больше, чем наивный расчёт в 50 видео в минуту мог бы предположить.
Для команд, которые не могут ждать повышения уровня или чьи потребности превышают то, что Google может выделить, существуют практические альтернативы. Распределение нагрузки между несколькими проектами Google Cloud (каждый со своей квотой в 50 RPM) -- это легитимная стратегия масштабирования, хотя она требует тщательной оркестрации для управления API-ключами и биллингом между проектами. При использовании мультипроектного подхода реализуйте балансировщик нагрузки, распределяющий запросы round-robin между проектами и отслеживающий использование RPM каждого проекта независимо. Такая настройка может линейно масштабировать вашу эффективную пропускную способность -- два проекта дают 100 RPM, три -- 150 RPM и так далее -- хотя консолидация биллинга и отслеживание расходов усложняются. Другой подход -- изучение самых доступных вариантов Veo 3 API, которые агрегируют доступ через различные каналы, потенциально обходя модель квот на уровне проекта.
Весь процесс повышения квоты можно суммировать в следующих конкретных шагах: во-первых, убедитесь, что ваш биллинг-аккаунт активен и имеет совокупные расходы не менее $250 для доступа к уровню 2. Во-вторых, перейдите в Google Cloud Console, откройте «IAM и администрирование», затем «Квоты и системные лимиты». В-третьих, отфильтруйте по «Veo» или «generateVideo», чтобы найти соответствующие записи квот. В-четвёртых, нажмите на значок карандаша рядом с текущим лимитом и отправьте запрос на увеличение с детальным обоснованием, включающим прогнозируемые дневные объёмы, ваш сценарий использования и любые требования соответствия. Наконец, отслеживайте свою электронную почту и панель уведомлений Cloud Console для получения ответа об одобрении, который обычно приходит в течение 2-5 рабочих дней.
Альтернативные подходы для крупномасштабной генерации видео
Для разработчиков, чьи потребности в генерации видео постоянно превышают возможности прямого API Google в рамках его лимитов, заслуживают рассмотрения несколько альтернативных подходов. Каждый из них включает компромиссы между стоимостью, контролем, задержкой и надёжностью, которые следует оценивать с учётом ваших конкретных требований.
Сторонние API-агрегаторы представляют наиболее простую альтернативу для команд, которые хотят сохранить свою существующую кодовую базу при увеличении пропускной способности. Провайдеры, такие как laozhang.ai, предоставляют доступ к Veo 3.1 через свой унифицированный API-эндпоинт, обычно с упрощённым ценообразованием (фиксированная цена за запрос вместо посекундной), без ограничений RPM и дополнительными функциями, такими как автоматическая обработка повторов и управление очередью запросов. Компромисс заключается в дополнительном уровне абстракции между вашим кодом и API Google, что может увеличить задержку, но также обеспечивает изоляцию от сбоев на стороне Google и изменений квот. Для команд, оценивающих эти варианты, наше сравнение стабильных альтернатив Veo 3.1 API предоставляет детальный анализ надёжности и ценообразования провайдеров.
Стратегии мультимодельного резервирования обеспечивают устойчивость через разнообразие, а не просто масштабирование одного провайдера. Интегрируясь с несколькими API генерации видео -- Veo 3.1 для основной генерации с резервированием на альтернативные модели при ограничении -- ваше приложение может поддерживать пропускную способность, даже когда любой отдельный провайдер ограничен. Этот подход требует поддержки клиентских библиотек и логики адаптации промптов для каждой модели, добавляя сложность, но кардинально улучшая доступность для критически важных рабочих процессов.
Варианты выделенных ресурсов или self-hosted решений существуют для развёртываний корпоративного масштаба. Vertex AI от Google Cloud поддерживает конфигурации приватных эндпоинтов, которые могут предоставить выделенную мощность Veo 3.1 вне общего пула квот, хотя это требует корпоративного соглашения и значительно более высоких минимальных обязательств по расходам. Этот путь имеет смысл только для организаций, генерирующих тысячи видео в час со строгими SLA по задержке и доступности.
Независимо от выбранного подхода, фундаментальный принцип остаётся неизменным: проектируйте свою архитектуру как провайдер-агностичную с самого начала. Используйте слой абстракции, изолирующий вашу бизнес-логику от лимитов, модели ценообразования или паттернов доступности любого конкретного API. Эта гибкость гарантирует, что по мере развития ландшафта генерации видео -- а он развивается стремительно -- ваше приложение сможет адаптироваться без архитектурных переделок.
Практическая реализация абстракции провайдера включает определение общего интерфейса с методами вроде generate_video(prompt, duration, resolution, mode) и check_status(operation_id), а затем реализацию специфичных для провайдера адаптеров за этим интерфейсом. Когда лимиты Veo 3.1 достигнуты, ваш слой оркестрации автоматически перенаправляет новые запросы к альтернативному провайдеру или ставит их в очередь для последующей обработки основным провайдером. Этот паттерн также упрощает тестирование -- вы можете подключить mock-провайдер во время разработки без каких-либо изменений в логике приложения. Команды, которые инвестируют в эту абстракцию на раннем этапе, неизменно отмечают более быстрые циклы итерации и меньшие операционные накладные расходы при масштабировании генерации видео через нескольких провайдеров и сценарии использования.
Часто задаваемые вопросы
Что происходит при превышении лимита запросов Veo 3.1?
При превышении лимита API возвращает ошибку 429 RESOURCE_EXHAUSTED с сообщением о том, что квота исчерпана. Запрос не обрабатывается, и плата за отклонённые запросы не взимается -- это важное уточнение, поскольку некоторые разработчики опасаются, что им выставят счёт за неудачные запросы. Квота сбрасывается на скользящей поминутной основе, то есть вам не нужно ждать полной минутной границы -- ёмкость освобождается непрерывно по мере выхода старых запросов из 60-секундного окна. Например, если вы отправили 50 запросов между 10:00:00 и 10:00:30, ёмкость начнёт восстанавливаться в 10:01:00 по мере устаревания самых ранних запросов. Рекомендуемый подход к восстановлению -- экспоненциальная задержка с базовой задержкой 1 секунда, удвоение при каждом повторе до максимума 64 секунды, с рандомным джиттером для предотвращения синхронизированных повторов от нескольких клиентов.
Сколько стоит генерация одного видео Veo 3.1?
Стоимость зависит от трёх факторов: длительности, разрешения и режима. При разрешении 720p/1080p 4-секундное Fast-видео стоит $0,60, 6-секундное Fast-видео -- $0,90, а 8-секундное Fast-видео -- $1,20. Режим Standard примерно утраивает эти цены: $1,60, $2,40 и $3,20 соответственно. При разрешении 4K (только 8 секунд) Standard стоит $4,80, а Fast -- $2,80 за видео. Бесплатный уровень для Veo 3.1 отсутствует -- весь API-доступ требует платного биллинг-аккаунта (ai.google.dev/gemini-api/docs/pricing, проверено в марте 2026).
Можно ли увеличить квоту Veo 3.1 API свыше 50 RPM?
Да, через систему уровней Google. Уровень 2 (потрачено $250+, 30+ дней) и уровень 3 (потрачено $1000+, 30+ дней) могут открыть более высокие квоты, но увеличение не автоматическое -- необходимо подать запрос на увеличение квоты через Google Cloud Console с бизнес-обоснованием. Одобрение обычно занимает 2-5 рабочих дней. Как альтернатива, распределение нагрузки между несколькими проектами или использование сторонних провайдеров, таких как laozhang.ai, может эффективно обойти ограничения квот на уровне проекта.
Когда наблюдаются пиковые часы для Veo 3.1 API?
По данным сообщества и наблюдаемым паттернам, пиковое использование приходится на рабочие часы Северной Америки: приблизительно с 9:00 до 17:00 по тихоокеанскому времени. В эти периоды задержка генерации может увеличиваться с 11 секунд до 6 минут, а ошибки 503 становятся более частыми. Непиковые окна (с 22:00 до 6:00 PT, выходные) предлагают значительно лучшую производительность и более низкую частоту ошибок.
Доступен ли Veo 3.1 в бесплатном тарифе?
Нет. По состоянию на март 2026 года Veo 3.1 требует платного биллинг-аккаунта в Google AI Studio или Google Cloud. Бесплатный уровень или пробный период для генерации видео через API не предусмотрен. Потребительские планы (AI Pro за $19,99/мес, AI Ultra за $249,99/мес) предоставляют ограниченную генерацию видео через интерфейс Google AI, но не включают API-доступ. Это существенное отличие от подхода Google к текстовым моделям Gemini, которые предлагают щедрые бесплатные уровни. Ресурсоёмкая природа генерации видео -- каждый запрос требует значительного времени GPU для нейронного рендеринга -- делает бесплатный API-доступ экономически нецелесообразным при текущих затратах на инфраструктуру.
В чём разница между production- и preview-моделями?
Veo 3.1 предлагает четыре варианта моделей: две production-модели (veo-3.1-generate-001 и veo-3.1-fast-generate-001) и две preview-модели (veo-3.1-generate-preview и veo-3.1-fast-generate-preview). Production-модели имеют более высокие лимиты запросов (50 RPM против 10 RPM для preview) и предназначены для стабильных, клиентских развёртываний. Preview-модели обеспечивают ранний доступ к предстоящим функциям и улучшениям, но могут содержать критические изменения, более низкие гарантии качества и более строгие лимиты запросов. Для любого production-приложения всегда используйте идентификаторы не-preview моделей и применяйте preview-модели только в staging- или dev-среде для тестирования совместимости с предстоящими изменениями до их выхода в production.
Как лимиты запросов Veo 3.1 соотносятся с другими API генерации видео?
По состоянию на март 2026 года лимит Veo 3.1 в 50 RPM для production конкурентоспособен по сравнению с другими коммерческими API генерации видео, хотя прямое сравнение затруднено из-за различных моделей ценообразования и уровней качества. Ключевой дифференциатор -- не голое число RPM, а сочетание лимита, стоимости за видео и качества вывода. Для команд, которым нужна максимальная пропускная способность без управления сложностью квот, сторонние агрегаторы, такие как laozhang.ai, предлагают фиксированную цену за запрос без ограничений RPM, фактически устраняя лимиты запросов как проектное ограничение в обмен на стоимость $0,15-$0,25 за запрос.