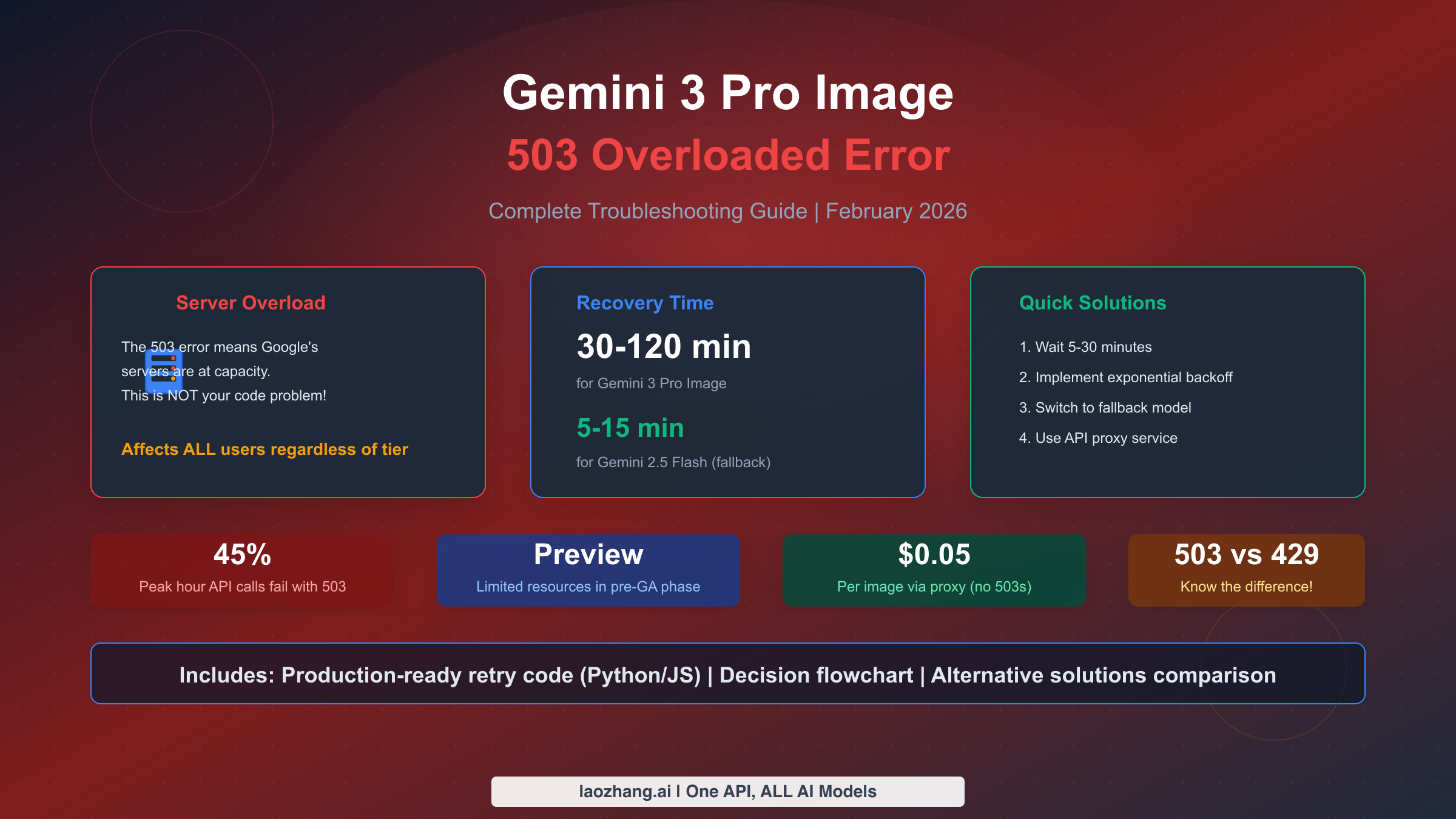
Gemini 3 Pro Image 503「模型过载」错误表示 Google 服务器已达到容量上限——这是服务器端问题,不是您的代码或配额问题。如需立即缓解,请等待 5-30 分钟后使用指数退避重试。Gemini 3 Pro 的恢复时间通常为 30-120 分钟,或者您可以切换到 Gemini 2.5 Flash,它的恢复时间仅需 5-15 分钟。与表示个人配额限制的 429 错误不同,503 错误影响所有用户,无论其层级或付费状态如何。本综合指南涵盖即时修复方案、生产级重试代码和决策框架,帮助您选择是等待还是切换到替代服务。
要点速览 - 快速解决方案表
在深入了解之前,以下是您需要在 30 秒内掌握的要点。503 错误与配额相关错误有本质区别,理解这一区别将帮助您节省数小时的错误方向排查。下表总结了基于开发者在生产环境中处理这些错误的真实经验,针对不同场景的建议操作。
| 情况 | 建议操作 | 预期恢复时间 |
|---|---|---|
| 首次 503 错误 | 等待 5-10 分钟,使用退避重试 | 70% 在 30 分钟内恢复 |
| 重复 503(超过 30% 调用失败) | 切换到 Gemini 2.5 Flash | 立即 |
| 业务关键型生产环境 | 使用 API 代理或多提供商设置 | 零停机 |
| 高峰时段(太平洋时间 9-11 AM、1-3 PM、6-10 PM) | 安排非高峰时段执行 | 完全避免问题 |
最重要的一点是:升级您的 Google Cloud 层级不会修复 503 错误。这是 Google 端的服务器容量问题,不是您账户的限制。许多开发者浪费时间请求增加配额,而实际问题需要完全不同的方法来解决。503 和 429 错误之间的根本区别决定了您排查策略的一切。
当您遇到 503 错误时,您的第一反应可能是检查计费设置或配额分配。请抑制这种冲动。503 状态码明确表示服务器理解了您的请求且您的身份验证有效,但服务器此时无法处理额外负载。您的 API 密钥、计费状态和层级与这个特定错误条件完全无关。
理解这一点的实际意义非常重要。与其在 Google Cloud 控制台中花时间调整配额或联系支持人员询问账户限制,您应该立即实施本指南中描述的重试或回退策略之一。理解这一区别所节省的时间可能意味着几分钟内解决事件与几小时之间的差异。
如果您当前正处于生产事故中,请直接跳转到下面的代码解决方案部分。否则,请继续阅读以了解为什么会发生此错误以及如何构建能够优雅处理它的系统。从理解根本原因中获得的知识将帮助您为长期可靠性做出更好的架构决策。
503 过载到底意味着什么?

当 Gemini 3 Pro Image 返回「模型过载。请稍后重试」的错误消息并带有 503 状态码时,表示 Google 的推理服务器已达到最大容量。这与 429「资源耗尽」错误有本质区别,后者表示您已超出个人配额限制。
503 错误代表服务器端基础设施约束,同时影响所有用户,无论其付费层级或配额分配如何。当 Google 的 Gemini 3 Pro Image 服务器达到容量上限时,即使是拥有最高层级计划的企业客户也会遇到此错误。这是因为 Google 为预览版(GA 前)模型分配的计算资源有限,优先考虑其面向消费者的产品(如 Gemini 应用和 AI Studio 网页界面)而非 API 请求。
理解这一区别至关重要,因为它决定了您的排查方法。对于 429 错误,您可以通过升级层级、降低请求频率或优化 token 使用来解决问题。对于 503 错误,这些解决方案都无效,因为约束不在您的账户上——而在 Google 的基础设施上。
技术解释涉及 Google 如何管理模型服务容量。截至 2026 年 2 月,Gemini 3 Pro Image 目前处于预览阶段,运行在共享的推理服务器池上。当对该模型的需求超过分配的容量时,负载均衡器开始返回 503 错误,而不是无限期地排队请求。这实际上是一种保护机制,可防止服务器崩溃并确保系统对成功通过的用户请求保持响应。
从 API 响应中,您可以通过检查 HTTP 状态码和错误消息来识别 503 错误。响应通常在原始格式中如下所示:
json{ "error": { "code": 503, "message": "The model is overloaded. Please try again later.", "status": "UNAVAILABLE" } }
一些开发者将 503 错误与 500 内部服务器错误混淆,后者表示 Google 系统中的实际 bug 或崩溃。503 明确表示「服务不可用」,通常是暂时的,而 500 错误可能表示需要 Google 工程团队解决的更深层问题。对于 503 错误,一旦容量可用,您的重试逻辑有合理的成功机会。
有关如何以不同方式处理配额相关 429 错误的详细对比,请参阅 我们的 429 错误修复完整指南。
503 错误的实际影响不仅限于简单的请求失败。在生产应用中,这些错误可能级联成用户可见的问题、失败的批处理作业和 SLA 违规。理解错误的本质有助于您与利益相关者准确沟通。当 503 发生时,您可以自信地告诉团队「这是影响所有用户的 Google 基础设施容量问题,不是我们可以通过更改配置来修复的。」这种清晰度可以防止浪费调查时间,并为解决时间线设定适当的预期。
自 2025 年底 Gemini 3 Pro Image 流行以来,503 错误的频率明显增加。随着越来越多的开发者发现该模型的高质量图像生成能力,需求开始超过 Google 为预览阶段模型分配的容量。这种模式与早期 Gemini 版本的情况相似,表明一旦模型达到正式发布状态并增加基础设施分配,情况将会改善。
恢复时间线和预期结果

根据 2025 年 12 月至 2026 年 1 月期间来自 Google AI 论坛和 GitHub Issues 的社区报告,503 错误的恢复时间线因模型和时间段而异。了解这些模式有助于您设定合理的预期,并就是等待还是切换到替代方案做出明智决策。
Gemini 3 Pro Image 在高峰拥堵期间通常在 30 到 120 分钟内恢复。这个较大的范围反映了服务器容量可用性的不可预测性。在中等拥堵期间,恢复可能只需 30 分钟,但在重大容量紧张期间——通常与产品发布或病毒式使用高峰同时发生——等待可能延长到两小时或更长。根据汇总的用户报告,大约 70% 的 503 情况在 60 分钟内解决。
相比之下,Gemini 2.5 Flash 显示出更快的恢复时间,通常在 5 到 15 分钟内恢复正常。这种更快的恢复是因为 Flash 模型由于每个请求的计算需求较低而分配了更多容量。当 Gemini 3 Pro Image 出现 503 错误时,切换到 Gemini 2.5 Flash 通常可以立即缓解,尽管对于复杂图像生成任务会有一些质量上的权衡。
503 错误最可能发生的高峰时段遵循与全球使用相关的可预测模式。在太平洋时间(Google 的服务器时间),风险最高的时段是上午 9:00-11:00(早间商务高峰)、下午 1:00-3:00(下午高峰)和晚上 6:00-10:00(晚间消费者使用)。这些时间对应北美的重叠工作时间和亚洲的晚间使用高峰。将批量图像生成作业安排在非高峰时段(太平洋时间晚上 11:00 - 早上 7:00)可以显著减少您遭遇 503 错误的风险。
统计数据为生产应用描绘了一幅令人担忧的画面。在高峰时段,大约 45% 的 Gemini 3 Pro Image API 调用可能因 503 错误而失败。这种高失败率使得实施健壮的重试逻辑不仅有帮助,而且对任何严肃的应用程序都是必不可少的。如果没有适当的错误处理,在繁忙时段您几乎一半的图像生成请求可能会失败。
影响恢复时间的一个重要因素是 Gemini 3 Pro Image 的预览状态。作为 GA 前模型,与稳定的生产模型相比,Google 分配的基础设施资源有限。根据以前 Gemini 模型发布的历史模式,预览限制通常持续 6-12 个月,直到模型达到正式发布。根据典型的 GA 时间线,用户应预期这种程度的 503 错误将持续到 2026 年中期。
有关与这些容量问题复合的速率限制和配额的详细信息,请查看我们的 Gemini 速率限制详解。
了解高峰时段与您的用户群位置之间的关系有助于优化请求时间。如果您的主要用户在欧洲,他们的晚间使用(中欧时间下午 6-10 点)与太平洋时间的早间高峰(上午 9-11 点)重叠,创造了一个特别具有挑战性的时段。相反,如果您可以将图像生成作业安排在加利福尼亚的夜间时段(太平洋时间晚上 11 点 - 早上 7 点)运行,由于 Google 服务器上的整体需求较低,您将遇到显著更少的 503 错误。
有了恢复时间数据,等待还是切换的经济计算变得更加清晰。如果您的平均图像生成作业需要 5 分钟,而您正在经历需要 60 分钟恢复的 503 错误,累积的停机成本可能超过使用替代服务的成本。对于按小时计费或在 SLA 承诺下运营的企业,这种计算通常倾向于主动回退策略而非被动等待。
随时间监控 503 错误模式可以揭示有用的趋势。一些开发者报告说,503 错误集中在 Google 重大产品公告或更新前后,表明内部测试和演示可能消耗了原本服务于 API 用户的容量。虽然这是推测性的,但将您的错误率与 Google 的产品日历进行追踪可能有助于您预期和准备拥堵期。
生产级代码解决方案
处理 503 错误最有效的方法是将指数退避重试逻辑与智能回退机制相结合。以下代码示例是可直接用于您应用程序的生产级实现。
Python 实现(使用 Tenacity)
Python 实现使用 tenacity 库进行复杂的重试处理,结合手动回退逻辑进行模型切换。这种方法提供可配置的重试行为,并使用抖动来避免多个客户端同时重试时的惊群问题。
pythonimport google.generativeai as genai from tenacity import ( retry, stop_after_attempt, wait_exponential_jitter, retry_if_exception_type ) from google.api_core.exceptions import ServiceUnavailable, ResourceExhausted import logging from datetime import datetime logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) # 配置 API genai.configure(api_key="YOUR_API_KEY") class GeminiImageGenerator: """ 生产级 Gemini 图像生成器,带重试和回退逻辑。 使用指数退避处理 503 过载错误。 """ def __init__(self): self.primary_model = "gemini-3-pro-image" self.fallback_model = "gemini-2.5-flash" self.max_retries = 5 self.base_wait = 30 # 秒 self.max_wait = 300 # 最长 5 分钟 @retry( retry=retry_if_exception_type((ServiceUnavailable, ResourceExhausted)), stop=stop_after_attempt(5), wait=wait_exponential_jitter(initial=30, max=300, jitter=10), before_sleep=lambda retry_state: logger.info( f"第 {retry_state.attempt_number} 次重试(503 错误后)。" f"等待 {retry_state.next_action.sleep} 秒..." ) ) def _generate_with_retry(self, model_name: str, prompt: str): """生成图像,503 错误时自动重试。""" model = genai.GenerativeModel(model_name) response = model.generate_content(prompt) return response def generate_image(self, prompt: str, allow_fallback: bool = True) -> dict: """ 生成图像,支持回退。 参数: prompt: 图像生成提示词 allow_fallback: 失败时是否尝试回退模型 返回: 包含 'success'、'model_used'、'response' 或 'error' 的字典 """ start_time = datetime.now() # 首先尝试主模型 try: logger.info(f"正在使用 {self.primary_model} 尝试生成") response = self._generate_with_retry(self.primary_model, prompt) duration = (datetime.now() - start_time).total_seconds() logger.info(f"使用 {self.primary_model} 成功,耗时 {duration:.1f} 秒") return { "success": True, "model_used": self.primary_model, "response": response, "duration_seconds": duration } except Exception as primary_error: logger.warning(f"主模型在重试后失败: {primary_error}") if not allow_fallback: return { "success": False, "model_used": self.primary_model, "error": str(primary_error) } # 尝试回退模型 try: logger.info(f"正在使用 {self.fallback_model} 进行回退") response = self._generate_with_retry(self.fallback_model, prompt) duration = (datetime.now() - start_time).total_seconds() logger.info(f"使用 {self.fallback_model} 回退成功") return { "success": True, "model_used": self.fallback_model, "response": response, "duration_seconds": duration, "used_fallback": True } except Exception as fallback_error: logger.error(f"两个模型都失败了: {fallback_error}") return { "success": False, "model_used": "both_failed", "primary_error": str(primary_error), "fallback_error": str(fallback_error) } # 使用示例 if __name__ == "__main__": generator = GeminiImageGenerator() result = generator.generate_image( "日落时分宁静的山景,湖中倒影" ) if result["success"]: print(f"使用模型生成: {result['model_used']}") else: print(f"生成失败: {result.get('error', '未知错误')}")
JavaScript/TypeScript 实现
对于 Node.js 应用程序,此实现使用 async/await 模式和可配置的重试行为提供类似功能。
typescriptimport { GoogleGenerativeAI } from '@google/generative-ai'; interface RetryConfig { maxRetries: number; baseDelayMs: number; maxDelayMs: number; jitterMs: number; } interface GenerationResult { success: boolean; modelUsed: string; response?: any; error?: string; usedFallback?: boolean; durationMs?: number; } class GeminiImageGenerator { private genAI: GoogleGenerativeAI; private primaryModel = 'gemini-3-pro-image'; private fallbackModel = 'gemini-2.5-flash'; private retryConfig: RetryConfig = { maxRetries: 5, baseDelayMs: 30000, // 30 秒 maxDelayMs: 300000, // 5 分钟 jitterMs: 10000 // 10 秒抖动 }; constructor(apiKey: string) { this.genAI = new GoogleGenerativeAI(apiKey); } private async sleep(ms: number): Promise<void> { return new Promise(resolve => setTimeout(resolve, ms)); } private calculateBackoff(attempt: number): number { // 带抖动的指数退避 const exponentialDelay = Math.min( this.retryConfig.baseDelayMs * Math.pow(2, attempt), this.retryConfig.maxDelayMs ); const jitter = Math.random() * this.retryConfig.jitterMs; return exponentialDelay + jitter; } private is503Error(error: any): boolean { return ( error?.status === 503 || error?.message?.includes('overloaded') || error?.message?.includes('UNAVAILABLE') ); } private async generateWithRetry( modelName: string, prompt: string ): Promise<any> { const model = this.genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < this.retryConfig.maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result; } catch (error: any) { if (this.is503Error(error) && attempt < this.retryConfig.maxRetries - 1) { const delay = this.calculateBackoff(attempt); console.log( `第 ${attempt + 1} 次尝试出现 503 错误。` + `${(delay / 1000).toFixed(1)} 秒后重试...` ); await this.sleep(delay); } else { throw error; } } } throw new Error('超过最大重试次数'); } async generateImage( prompt: string, allowFallback = true ): Promise<GenerationResult> { const startTime = Date.now(); // 尝试主模型 try { console.log(`正在使用 ${this.primaryModel} 尝试生成`); const response = await this.generateWithRetry(this.primaryModel, prompt); return { success: true, modelUsed: this.primaryModel, response, durationMs: Date.now() - startTime }; } catch (primaryError: any) { console.warn(`主模型失败: ${primaryError.message}`); if (!allowFallback) { return { success: false, modelUsed: this.primaryModel, error: primaryError.message }; } // 尝试回退模型 try { console.log(`正在使用 ${this.fallbackModel} 进行回退`); const response = await this.generateWithRetry(this.fallbackModel, prompt); return { success: true, modelUsed: this.fallbackModel, response, usedFallback: true, durationMs: Date.now() - startTime }; } catch (fallbackError: any) { return { success: false, modelUsed: 'both_failed', error: `主模型: ${primaryError.message}, 回退模型: ${fallbackError.message}` }; } } } } // 使用示例 const generator = new GeminiImageGenerator('YOUR_API_KEY'); const result = await generator.generateImage( '日落时分宁静的山景' ); if (result.success) { console.log(`使用模型生成: ${result.modelUsed}`); } else { console.error(`失败: ${result.error}`); }
两个示例中值得注意的关键实现细节包括在退避计算中使用抖动,这可以防止多个客户端同时重试而同时命中服务器。回退机制优雅地降级到恢复更快的模型,而不是完全失败。全面的日志记录有助于生产环境中的调试和监控。
有关处理相关 429 错误类型的更多信息,请参阅我们的 429 错误故障排除指南。
上述实现模式遵循处理瞬态故障的行业最佳实践。带抖动的指数退避可防止「惊群」问题,即多个客户端在完全相同的时刻重试,可能在服务器刚恢复时就将其压垮。抖动为重试时间添加随机性,分散负载并给服务器更好的稳定机会。
这些实现中的错误日志记录不仅仅用于调试。503 错误频率的历史日志有助于您识别模式,向利益相关者证明基础设施投资的合理性,并为事后审查提供数据。考虑将这些日志与您的可观测性堆栈(Datadog、New Relic 或类似工具)集成,以创建可视化错误率随时间变化并将其与业务指标相关联的仪表板。
回退模型选择值得根据您的具体用例仔细考虑。虽然 Gemini 2.5 Flash 提供更快的恢复和更好的可用性,但对于复杂图像生成任务的质量差异可能很明显。如果您的应用程序生成营销图像或产品可视化,其中质量至关重要,您可能更喜欢使用重试逻辑进行更长的等待,而不是自动回退到较低质量的模型。相反,如果您生成的是缩略图或占位图像,速度比完美更重要,则积极回退到 Flash 是有意义的。
在生产事故之前测试您的重试和回退逻辑至关重要。考虑实施「混沌工程」方法,在测试期间故意注入模拟的 503 错误,以验证您的回退机制是否正常工作。许多团队只有在实际故障期间才发现其错误处理中的 bug,这是发现重试逻辑存在问题的最糟糕时机。
决策框架:应该等待还是切换?
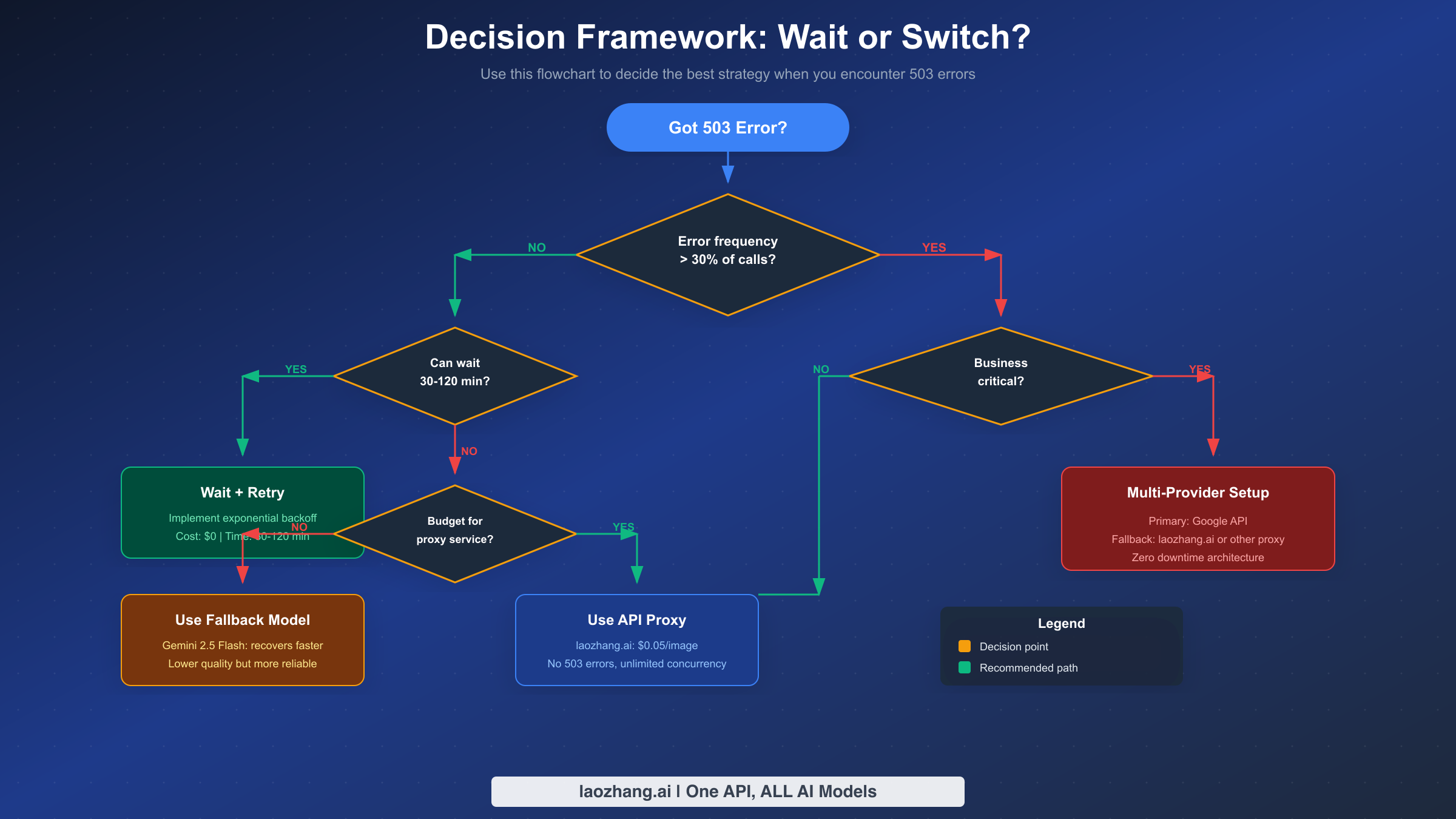
在等待恢复和切换到替代方案之间做出正确选择取决于您的具体情况。此决策框架帮助您系统地评估选项,而不是在事故期间做出反应性选择。
首先要问的问题是关于错误频率。如果少于 30% 的 API 调用因 503 错误而失败,您正在经历可能自行解决的中等拥堵。在这种情况下,实施指数退避重试逻辑通常就足够了。您的请求最终会成功,临时延迟对大多数应用程序来说是可接受的。这种方法不需要额外成本,并保持对 Gemini 3 Pro Image 功能的完全使用。
当错误频率超过 30% 时,计算发生了显著变化。在这种失败率下,仅靠重试逻辑会导致不可接受的延迟,您需要考虑替代方案。下一个问题是您的应用程序是否能够容忍等待 30 到 120 分钟恢复。对于批处理作业、计划任务或非时间敏感的应用程序,使用重试逻辑等待仍然是可行的选择。您不需要支付替代服务费用,并且保持图像生成质量的一致性。
对于不能容忍长时间延迟的应用程序——如面向用户的功能、实时图像生成或时间敏感的工作流——您需要评估替代解决方案的预算。如果预算限制显著,切换到 Gemini 2.5 Flash 作为回退模型可以提供缓解。Flash 模型恢复更快(5-15 分钟对比 30-120 分钟),在高峰期提供更好的可用性。权衡是复杂图像生成任务的质量可能较低,但对于许多用例来说这种差异是可接受的。
如果您的应用程序是业务关键型且需要高可用性,推荐的方法是多提供商架构。此设置使用 Google 的 API 作为主要提供商,当主要提供商失败时自动故障转移到辅助服务。第三方 API 代理如 laozhang.ai 以每张图像 0.05 美元的价格提供无限并发且无 503 错误,相比之下 Google 直接定价为每张图像 0.134-0.234 美元。成本溢价提供了 Google 预览阶段模型无法匹配的可靠性保证。
决策树可以用实际术语总结。对于业余项目和实验,使用重试逻辑等待。对于有灵活时间要求的生产应用程序,实施重试加 Flash 回退。对于需要零停机的业务关键应用程序,投资多提供商冗余。可靠性基础设施的前期投资在每次 503 故障发生时都会产生回报。
真实世界的决策示例有助于说明这些原则。考虑一家为客户生成社交媒体图像的营销机构。他们的交付期限通常以天而非分钟计算。对于这种用例,实施重试逻辑并在非高峰时段进行夜间批处理可以在不增加额外成本的情况下提供足够的可靠性。工作时间偶尔出现的 503 错误是不便,而不是危机。
与此形成对比的是一个电子商务平台,当卖家上传新商品时实时生成产品图像。每分钟的延迟都会直接影响卖家体验和平台竞争力。对于这种用例,具有自动故障转移的多提供商架构通过改善卖家满意度和减少支持工单来证明其成本的合理性。代理服务费是可预测的运营费用,而不是紧急成本。
第三个场景涉及一个在用户入门时生成个性化头像的移动应用。用户在注册期间的耐心有限,任何延迟都有导致放弃的风险。在这里,积极的回退方法是有意义的——从 Gemini 3 Pro Image 开始以保证质量,但在几秒钟内而非几分钟内故障转移到 Gemini 2.5 Flash。轻微的质量降低比失去等待放弃的用户更可取。
零停机替代解决方案
在评估直接 Google API 访问的替代方案时,重要的是考虑运行时间以外的多个维度。以下比较提供了可用选项的客观评估,帮助您根据具体需求做出明智决策。
选项 1:等待和重试(零成本)
最简单的方法是实施前面展示的重试逻辑,并在高峰拥堵期间接受临时延迟。此选项没有额外成本,保持完全的 API 兼容性,但无法保证响应时间。它最适合偶尔 30-120 分钟延迟可接受的应用程序,如批处理或离线内容生成。
选项 2:模型回退到 Gemini 2.5 Flash
使用 Gemini 2.5 Flash 作为回退模型可在保持在 Google 生态系统内的同时提供更快的恢复时间。Flash 模型通常在 5-15 分钟内恢复,相比之下 Pro Image 需要 30-120 分钟。Flash 的定价也更低。权衡是复杂提示的图像生成质量降低,但对于许多用例来说差异可以忽略不计。当您需要在不增加服务提供商的情况下提高可靠性时,此选项效果很好。
选项 3:第三方 API 代理
对于需要零停机的开发者,第三方 API 代理通过分布式基础设施路由请求,即使 Google 的直接端点拥堵时也能保持可用性。laozhang.ai 等服务以每张图像 0.05 美元的价格提供 Gemini 3 Pro Image 访问,具有无限并发且无 503 错误。API 格式与 Google 的 SDK 保持兼容,需要最少的代码更改。您可以在 docs.laozhang.ai 找到详细文档。
比较表总结了关键区别:
| 因素 | 等待 + 重试 | Flash 回退 | API 代理 |
|---|---|---|---|
| 额外成本 | $0 | 每张图像更低 | ~$0.05/张 |
| 恢复时间 | 30-120 分钟 | 5-15 分钟 | 立即 |
| 503 风险 | 高峰期高 | 中等 | 无 |
| 图像质量 | 完整 Pro 质量 | 降低 | 完整 Pro 质量 |
| 代码更改 | 仅重试逻辑 | 模型切换 | 端点更改 |
| 最适合 | 非关键批处理 | 灵活质量需求 | 零停机生产 |
做出此决策时,考虑您的实际使用模式。如果您每月生成少于 100 张图像且可以容忍偶尔延迟,等待和重试方法完全足够。对于生成数千张图像且有正常运行时间要求的应用程序,代理选项的可靠性溢价通常是值得的。
从技术角度来看,从直接 Google API 访问过渡到代理服务非常简单。大多数代理服务与 Google 的 SDK 保持 API 兼容性,只需要更改端点 URL 和 API 密钥。这意味着您可以在暂存环境中测试代理集成,而无需进行重大代码更改。在生产环境中准备好但不激活此集成允许您在长时间 503 故障期间快速启用它,即使您不经常使用它也可以提供紧急逃生舱口。
在评估第三方代理时,安全考虑值得关注。您的图像生成提示可能包含敏感的业务信息,生成的图像可能包含专有设计或机密内容。在提交之前评估每个代理提供商的数据处理政策、加密实践和合规认证。信誉良好的提供商将清楚地记录其安全实践,并可能提供具有额外保护的企业协议。
跨这些替代方案的成本优化需要持续监控。跟踪您的实际 503 错误率,并计算您特定情况下停机的真实成本。一些团队发现他们最初的估计过于悲观——他们实际的 503 暴露可能低于预期,使等待和重试方法足够。其他人发现停机的隐藏成本(开发人员处理紧急情况的时间、客户支持工单、声誉影响)远远超过替代服务的直接成本。
有关各种 API 访问选项的详细定价信息,请参阅我们的 Nano Banana Pro 定价指南。
构建优雅处理故障的系统
除了即时修复之外,设计能够预期并优雅处理 503 错误的系统可以防止未来的事故造成业务影响。这种架构视角帮助技术负责人规划长期可靠性,而不是处理单个故障。
最健壮的架构采用多提供商策略,具有自动健康检查和故障转移。主要提供商(Google 的直接 API)在正常运行期间处理请求,而辅助提供商在主要提供商健康检查失败时激活。典型实现包括断路器模式,在连续失败后打开,将流量路由到备份,直到主要提供商恢复。
典型的多提供商设置使用 Google 的 API 作为主要提供商,并回退到 laozhang.ai 等服务以获得可靠性。断路器在滑动窗口内跟踪失败率,当失败阈值超过 30% 时自动重定向流量。一旦主要提供商在配置的恢复期内通过健康检查,流量逐渐转移回来。这种方法在主要提供商可用时通过优先使用它来实现零停机运营,同时最大限度地降低成本。
请求队列为非时间敏感的工作负载提供另一层弹性。当 503 错误发生时,请求进入具有自动重试调度的持久队列。工作程序在容量可用时处理队列,确保不会丢失任何请求。这种模式特别适用于完成时间灵活但可靠性至关重要的批量图像生成。
监控和告警完善了可靠性图景。跟踪的指标包括 503 错误率、成功前的平均重试次数、回退激活频率和 P95 响应延迟。告警阈值应在用户影响变得严重之前触发——例如,当 5 分钟 503 率超过 10% 时告警,而不是等到达到 50%。
对于考虑将速率限制优化与 503 处理相结合的应用程序,了解层级系统有助于容量规划。有关详细信息,请参阅我们关于 理解速率限制层级 的指南。
弹性架构的投资会产生复合回报。每次避免的故障都保持了用户信任,防止了收入损失,并消除了事故响应的压力。Gemini 3 Pro Image 的预览阶段限制使这项投资特别值得——根据典型的发布时间线,这些 503 问题将持续到模型达到正式发布,可能在 2026 年中期。
文档和运行手册完善了运营图景。即使有自动故障转移,人类操作员也需要了解事故发生时发生了什么。创建运行手册,解释如何解释监控仪表板、何时手动干预自动故障转移决策,以及如何向利益相关者传达状态。包括升级路径的联系信息和事后审查程序。
考虑您的弹性策略对用户体验的影响。如果您的应用程序在 503 事件期间自动回退到较低质量的模型,您应该通知用户吗?一些应用程序显示微妙的指示器(「使用替代模型生成」)以设定适当的期望。其他应用程序只是交付结果而不解释,优先考虑无缝体验而非透明度。正确的选择取决于您的用户群及其对质量变化的敏感度。
长期容量规划受益于将 503 事故视为数据点而非仅仅是要解决的问题。跟踪它们发生的时间、持续多长时间以及造成的业务影响。这些数据有助于证明基础设施投资的合理性,为供应商谈判提供信息,并为架构决策提供证据。有据可查的 503 事故历史可以支持可能被否定为过度工程的可靠性改进预算请求。
常见问题
为什么我没有超过配额却收到 503 错误?
503 错误表示 Google 基础设施的服务器容量限制,这与您的账户配额完全分开。429 错误意味着您已超出个人限制,而 503 错误意味着 Google 此模型的服务器对所有用户都处于容量上限。升级您的层级或购买更多配额不会解决 503 错误,因为约束在 Google 端,而不是您的账户。
503 错误后应该等多久再重试?
第一次重试从 30 秒开始,然后每次后续尝试将等待时间加倍(指数退避)。添加 5-10 秒的随机抖动以防止多个客户端同步重试。大多数 503 情况在典型拥堵期间 30-60 分钟内解决,但高峰期可能需要等待 2 小时或更长。
升级到付费层级或企业计划会修复 503 错误吗?
不会。与通过层级升级解决的 429 错误不同,503 错误影响所有用户,无论付款层级如何。Google 的预览阶段模型容量有限,不会随个人账户层级扩展。即使企业客户在高峰拥堵期间也会遇到 503 错误。
Gemini API 的 503 和 500 错误有什么区别?
503 错误(服务不可用)表示临时容量约束——服务器是健康的但过载。一旦容量可用,您的重试逻辑有很好的成功机会。500 错误(内部服务器错误)表示可能需要 Google 工程团队解决的实际系统故障或 bug。对于 500 错误,在底层问题修复之前重试可能没有帮助。
我可以监控 Gemini 3 Pro Image 容量何时可用吗?
Google 在 aistudio.google.com/status 提供状态页面,显示服务健康状况。但是,此页面显示一般服务状态,而不是特定模型的实时容量。要进行更细粒度的监控,实施您自己的健康检查,定期发出测试请求并跟踪成功率。这为您提供了特定于应用程序的容量可用性可见性。
Gemini 3 Pro Image 可用性有 SLA 吗?
没有。作为预览版(GA 前)模型,Gemini 3 Pro Image 没有官方服务级别协议。Google 不保证正常运行时间百分比或为故障提供补偿。需要 SLA 保证的生产应用程序应该使用 GA 模型或实施具有提供合同正常运行时间承诺的服务的多提供商冗余。