
先给结论(截至 2026 年 3 月 18 日): Gemini API 的 429 RESOURCE_EXHAUSTED 通常意味着你碰到了配额、计费层级或速率限制问题,很多情况下应该先短暂等待再重试;400 INVALID_ARGUMENT 通常意味着请求体、接口版本、模型选择或计费前置条件有问题,应该先修请求而不是盲目重试;500 INTERNAL 通常意味着 Google 侧暂时不稳定,或者你的上下文太长,此时最有效的动作是先缩短输入,再使用带上限的退避重试,并在必要时临时从 Pro 切到 Flash。真正重要的不是“错误码是什么意思”,而是“下一步到底该重试、改代码,还是换模型”。
很多 Gemini 错误文章会把几个错误码塞进一张表里就结束,但 2026 年的实际问题比那张表复杂得多。429 不只是“请求太多”这么简单,它还和 2025 年 12 月 7 日之后的配额调整、Tier 1 的传播延迟、以及社区里反复出现的“低使用量也报 429”现象有关。400 也不只是“你 JSON 写错了”,它还可能是 /v1 与 /v1beta 版本不匹配,或者免费层不可用地区触发的前置条件失败。500 更不是一句“稍后再试”就够了,因为 Google 官方已经明确说明:输入上下文太长也会触发 500,而且很多时候从 Gemini 2.5 Pro 临时切到 Gemini 2.5 Flash,比长时间等服务恢复更快。
要点速览
如果你现在正在看日志、命令行或监控面板,这一节就够你先做第一轮判断。核心原则很简单:不要把 429、400、500 当成同一类问题来处理。
| 错误 | 2026 年最常见的真实含义 | 现在该重试吗? | 第一动作 |
|---|---|---|---|
429 RESOURCE_EXHAUSTED | 你撞到了 RPM / TPM / RPD,或者计费层级状态与预期不一致 | 多数情况下要 | 先检查项目层级与活跃配额,再做退避重试 |
400 INVALID_ARGUMENT | 请求体、参数、模型或接口版本不对 | 通常不要 | 先修请求结构、模型与接口版本 |
400 FAILED_PRECONDITION | 地区或计费前置条件不满足 | 不要 | 开通计费,或改用受支持的路径 |
500 INTERNAL | Google 侧暂时异常,或上下文过长 | 要,但要有策略 | 先缩短上下文,再重试,必要时切 Flash |
有三条“时间信息”会直接改变你的排查思路。第一,Google 体系内的 Firebase AI Logic FAQ 已经明确写明:Gemini Developer API 的 Free Tier 与 Paid Tier 1 配额在 2025 年 12 月 7 日 起做了调整,这就是很多应用在没有明显改代码的情况下突然更容易出现 429 的背景。第二,Google 的 Gemini API 计费文档 明确说明:400 与 500 失败请求不会计费,但仍会占用配额。第三,Google 在 2026 年 3 月 又改了使用层级和消费上限,并将在 2026 年 4 月 1 日 开始正式执行 tier spend cap,所以“以前没问题”在这个时间点已经不再是可靠的判断依据。
30 秒判断 Gemini API 的 429、400 与 500
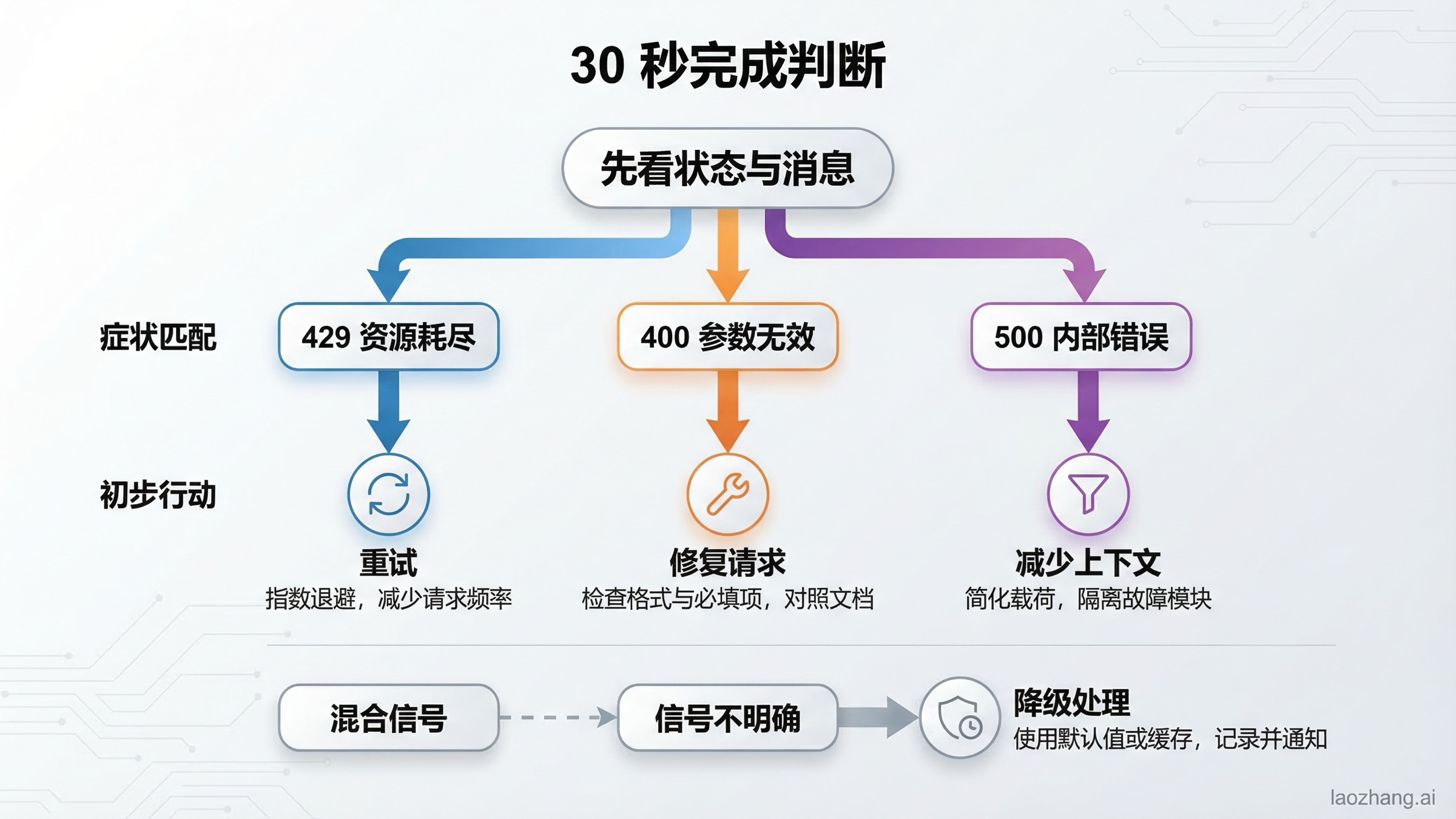
真正有用的排查方式,不是只看 HTTP 状态码,而是同时看 status、message、是否带有 QuotaFailure、是否出现 RetryInfo、请求打到了哪个模型,以及你走的是 /v1 还是 /v1beta。很多开发者只在日志里记录了“429”或者“500”,这在排查时几乎没有价值,因为你根本不知道它是配额耗尽、计费没生效、请求太大,还是模型自身不稳定。
官方的 Gemini troubleshooting guide 仍然是最应该先看的页面,因为它给出了最标准的错误码与首要动作映射。但把这张官方表真正落到操作层时,你最好这样理解:429 是“系统认为你该降速了,或者你的 tier / quota 状态和你想的不一样”;400 INVALID_ARGUMENT 是“请求本身被拒绝了”;400 FAILED_PRECONDITION 是“请求格式可能没问题,但你的地区或计费状态不允许你这么用”;500 则是“认证和基础校验已经通过,错误是在 Google 侧处理阶段发生的”。
下面这张表,比单看 HTTP 码更接近真实排障流程:
| 响应里出现的关键字 | 更可能是哪条分支 | 背后最常见的问题 | 下一步 |
|---|---|---|---|
RESOURCE_EXHAUSTED、RetryInfo、quota、per minute、per day | 429 | 真实限流或 tier / quota 状态异常 | 先退避重试,再验证项目配额与计费层级 |
Request contains an invalid argument | 400 INVALID_ARGUMENT | 请求体、参数、模型或接口版本不对 | 先停掉重试,核对请求结构 |
free tier is not available in your country 或明显的 billing/setup 提示 | 400 FAILED_PRECONDITION | 地区或计费前置条件没满足 | 先开通计费或改用支持地区 |
An internal error has occurred | 500 | Google 侧异常,或上下文太长 | 缩短上下文、退避重试,并测试 Flash |
如果你想节省真正的排查时间,请在日志里至少保留四类信息:模型 ID、接口版本、请求大小、同一 payload 是否能在另一个 Gemini 模型上通过。很多时候,正是这四个信息帮你区分“是我写坏了”还是“是某个模型当前状态不稳定”。
修复 429 RESOURCE_EXHAUSTED:配额、计费层级与“幽灵 429”
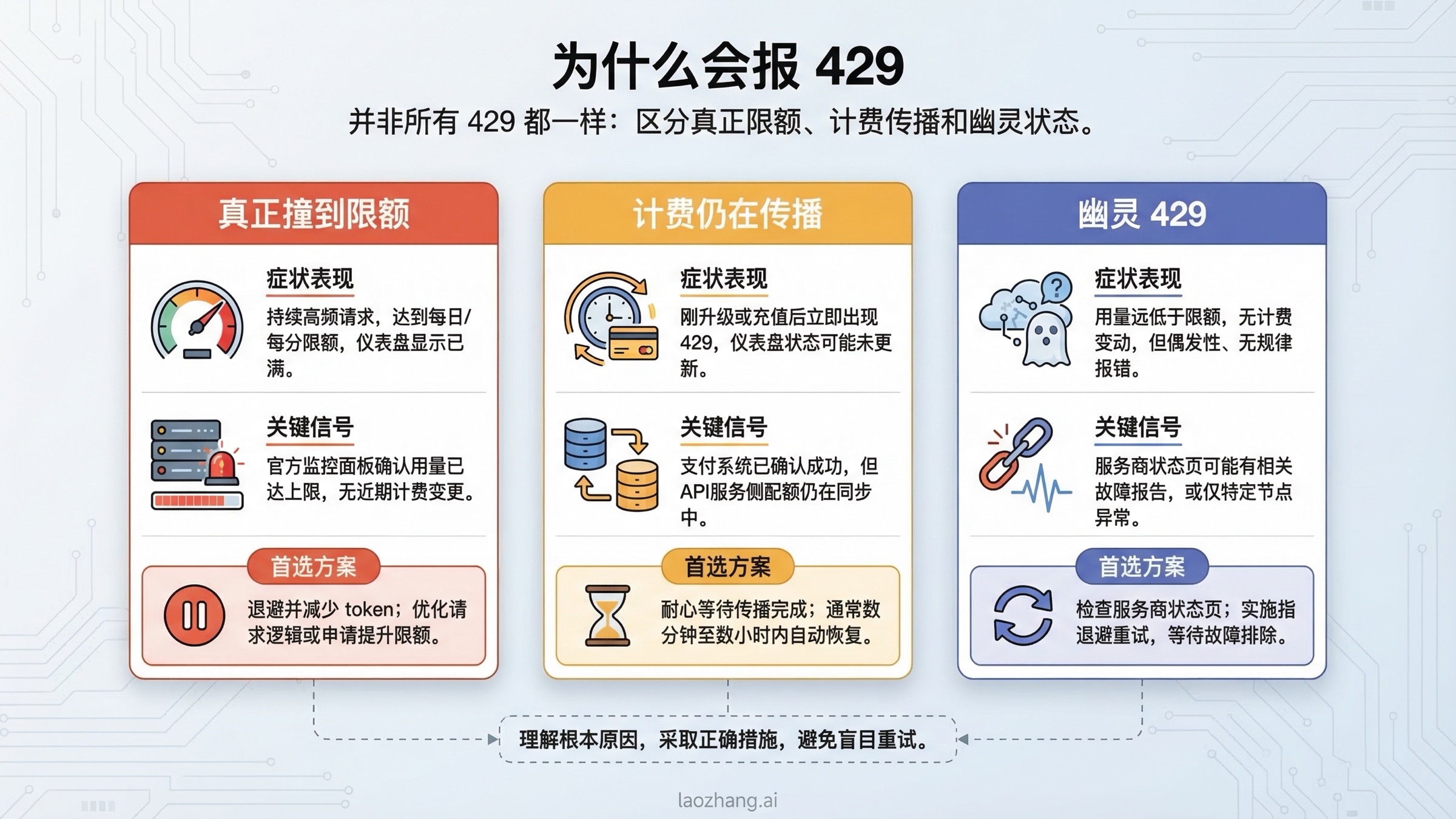
Gemini 官方对 429 的解释很直接:你超过了速率限制。这个解释是对的,但在 2026 年明显不够用。因为 Google 的 rate limits 页面 还有两个同样重要的细节。第一,你的活跃限制是动态显示在 AI Studio 里的,不是某篇旧文章里写死的数字。第二,Google 明确写着“文档列出的限制并不保证固定可得,真实容量可能变化”。这意味着如果你还拿着几个月前截图里的 RPM 表去排查,结论很容易偏掉。
真正让 429 更复杂的是 2025 年 12 月 7 日的配额调整。Google 体系内的 Firebase AI Logic FAQ 已经明确说明,从这一天开始,Gemini Developer API 的 Free Tier 和 Paid Tier 1 配额都发生了变化,而且这会导致“意外的 429 quota-exceeded 错误”。这条信息的重要性非常高,因为它解释了为什么很多团队会遇到这种情况:请求量没明显增长,代码也没大改,但 429 突然变多了。
第二个最常被忽略的事实是:Gemini 的限制是按项目和计费账户层来生效的,不是给每个 API Key 单独发一份。Google 的 billing 文档已经写得很清楚,API Key 只是继承了项目和账单账户的状态。所以你在同一个项目里新建一个 key,并不会自动得到一份新的配额。如果项目层面已经耗尽、被限流、或者计费状态没切换过去,新 key 的表现通常和旧 key 一样。
可以把 429 大致分成下面三类场景来看:
| 429 场景 | 常见表现 | 最优先动作 |
|---|---|---|
| 真正的限流 | 并发上来了、请求突发、提示里能看出 per minute / per day / quota 信息 | 做退避重试,降并发,减少 token,必要时排队 |
| 计费刚开通但还没完全传播 | 你刚升到 Tier 1,但行为仍像免费层 | 先确认项目确实升层,再等几分钟 |
| “幽灵 429” 或低使用量异常 | 仪表板看起来很空,但请求几乎立刻报 429 | 先确认打到的是对的项目,再看错误体里的 quota 细节 |
Google AI Developers Forum 上有多个帖子的共同特点是:明明是 Paid Tier,仪表板使用量也不高,429 却还是频繁出现,而且有些错误体里还会意外提到 free-tier quota metric。这并不意味着“所有 429 都是平台 bug”,但它至少告诉你一件事:别把所有 429 都粗暴归结为“你请求太多了”。如果一个低流量、已启用计费的项目几乎在第一批请求时就开始报 429,那么在确认项目、billing account 与 key 都没搞错之后,怀疑 quota 同步或 tier 状态问题是合理的。
对于真正的限流,最实用的修复手段仍然是那些看起来不花哨、但真的有效的东西:减少突发流量、合并小请求、缩短上下文、把无意义的历史消息从 prompt 中剪掉,并在客户端实现指数退避重试。如果你的场景确实需要更稳定的吞吐量,官方路径就是升级到 Tier 1 或更高 tier。Google 的 rate limits 文档还明确提到:从 Free 到 Tier 1 通常会立即生效,后续 tier 升级通常在 10 分钟内生效。如果你早就开通了计费,但还是表现得像免费层,那么问题更可能在配置或状态传播,而不是你算错了流量。
如果你遇到的不是单次小故障,而是“官方直连波动导致生产业务经常被打断”,那就已经不只是配额表的问题了。对于需要统一 API 接入、多模型切换和可控降级的团队,laozhang.ai 这种 OpenAI 兼容的中转层才可能真正相关;如果你只是把一个请求写错了,它并不是答案。
如果你想看更完整的背景,可以继续读我们的 Gemini API 错误排查完全指南、Gemini API 配额升级指南 和 Google Gemini API 免费层说明。
修复 400:INVALID_ARGUMENT 与 FAILED_PRECONDITION 要分开看
400 是最容易被误判的一类错误,因为很多人一看到 “Bad Request” 就以为是同一个问题。实际上 Gemini 官方已经明确把 400 分成了至少两种完全不同的分支:INVALID_ARGUMENT 和 FAILED_PRECONDITION。前者通常是请求结构、模型、参数或接口版本不对;后者更常是地区、计划、计费前置条件没有满足。
先说 INVALID_ARGUMENT。Google 官方 troubleshooting guide 直接写明,它通常表示请求体格式错误、缺少必要字段,或者你把新版本接口的能力用在了旧 endpoint 上。这一点非常关键,因为很多开发者的 JSON 语法其实没错,问题出在你调用了 /v1,但用了只有 /v1beta 才支持的特性;或者模型本身不支持你当前传入的参数组合。换句话说,“看起来像合法请求”不代表它真的对。
2026 年里最常见的几种 400 触发点大致是这些:模型名写旧了或已经下线;参数超出了当前模型支持范围;请求体字段嵌套层级不对;文件处理方式与接口预期不匹配;或者你把某个 Beta 能力用到了不支持的 endpoint 上。Google 的官方文档已经明确提醒:如果你需要某个仍处在 Beta 状态的功能,就必须确认使用的是正确 API 版本。这也是为什么修 400 时,最好的顺序不是“随便试几次”,而是先核对 API 版本、模型页面、请求体结构,再发下一次请求。
你可以先用下面这张对照表快速归类:
| 400 类型 | 最常见根因 | 第一修复动作 |
|---|---|---|
INVALID_ARGUMENT + 泛化报错 | JSON 结构、字段或参数不对 | 对照最新官方示例检查 payload |
INVALID_ARGUMENT + 刚改了功能 | /v1 与 /v1beta 不匹配,或模型不支持该能力 | 同时检查 endpoint 版本与模型能力 |
INVALID_ARGUMENT + 文件/大输入 | 文件处理方式或 payload 体积不合适 | 改用正确上传流程,并缩小请求复杂度 |
FAILED_PRECONDITION | 地区或计费前置条件没满足 | 先开通计费,或换受支持路径 |
FAILED_PRECONDITION 则是另一类。Google 官方直接写明:如果你的国家/地区不支持 Gemini API 免费层,而项目又没有启用计费,就会触发这个错误。这个时候你去不停改 JSON、删字段、换 SDK 版本,基本都不会解决问题。真正要改的是 billing 状态或使用地区,而不是请求体。
当然,400 也有一个现实世界里的细节需要保持清醒。社区里确实存在一些“看起来像本地 bug,最后又自动恢复”的 400 案例,尤其是涉及流式输出、文件上传或某些特定模型时。Google AI Developers Forum 上就有开发者报告:完全没改代码的 gemini-2.5-flash PDF 流式请求突然开始报 400 INVALID_ARGUMENT,过一段时间后又自己恢复。正确的理解不是“400 以后也都能重试了”,而是:当你确认请求体看起来没问题,而且同一个 payload 在兄弟模型上能跑通时,就不要一上来把自己的代码推翻重写。先判断是不是模型或服务侧的暂时性异常。
如果你排查到最后发现是免费层、地区或计费路径问题,可以继续看我们的 Gemini API 免费层完全指南。
修复 500 INTERNAL:超长上下文、模型不稳定与安全重试
500 是最容易把开发者拖进无效排查里的错误,因为它看起来像“程序跑坏了”,但很多时候真正的问题不在你本地。Google 官方 troubleshooting guide 里对 500 的说明非常关键:你的输入上下文太长,也可能触发 500 INTERNAL。官方建议的修复动作不是继续把更多日志打印出来,而是先缩短上下文,再尝试临时切到另一个模型,例如从 Gemini 2.5 Pro 切到 Gemini 2.5 Flash。
这条建议之所以重要,是因为 Gemini 2.5 Pro 的模型页明确给出了 1,048,576 token 输入上限,而这恰恰会诱导很多开发者不断把更长的文档、更大的历史对话、更复杂的检索上下文塞进去。理论上限并不等于“每次都稳”。如果你把很大的多文件输入、很长的对话历史、很多检索片段和复杂系统提示一起喂给 Pro,500 的风险自然会上升。
所以 500 的第一条排查规则非常朴素:先缩上下文,再谈别的。把重复指令删掉,把历史消息剪短,把没必要的附件去掉,把 Retrieval 结果数量压缩到真正必要的范围。很多时候你不需要“重写程序”,只需要停止往模型里塞无意义的大输入。
另一种 500 则更像平台侧波动。2025 年以来,Google AI Developers Forum 上出现过多次“Gemini 2.5 Pro 大面积 500,但 Flash 正常”的讨论。这种情况下,最该做的不是花两小时怀疑自己的 JSON,而是拿同一份 payload 去试一下 gemini-2.5-flash。如果 Flash 正常、Pro 异常,那么最快的恢复策略通常就是临时降级,而不是等一个完美的官方说明。
我建议 500 的处理顺序固定成下面这样:
- 先看当前请求是否特别大、特别慢。
- 做带上限和抖动的指数退避重试。
- 如果原来用的是 Pro,就用同一 payload 测一下 Flash。
- 如果缩短输入后仍持续失败,而且多名用户/多个请求都报类似错误,就按平台侧事件来处理,不要继续只在本地打转。
如果你还想看一个更典型的服务端容量案例,可以读我们的 Gemini 3 Pro Image 503 overloaded 指南。
反复报错时的排查流程
真正高效的排查不是“来一个错误就单独修一次”,而是把重复性故障变成固定流程。这样你就不会在 Cloud Console、AI Studio、SDK 文档、日志系统和代码 diff 之间来回切换,却始终没有确定真正的瓶颈在哪里。
比较推荐的做法是,先固定一份失败请求和一份成功请求,如果能拿到的话,把两者逐项比较:模型 ID、API 版本、参数、payload 大小、上下文长度、以及是否带文件。如果差异主要在流量和并发,那更像 429;如果差异主要在字段结构,那更像 400;如果完全一样的 payload 在一个模型失败、另一个模型成功,那更像平台侧或模型侧不稳定。
很多团队之所以会在 Gemini 错误上越排越乱,是因为从一开始就没有回答一个最关键的问题:时间会不会让它自己变好? 对 429 和相当一部分 500 来说,时间确实可能有效;对确定性的 400 来说,时间几乎没有帮助。如果你已经拿同一个 INVALID_ARGUMENT payload 重试了三次,你不是在“坚持”,你是在继续消耗配额。
比较实用的一套排查顺序是:
| 步骤 | 要确认什么 | 为什么重要 |
|---|---|---|
| 1 | 完整错误体和模型 ID | 防止把平台侧事件当成本地 bug |
| 2 | /v1 还是 /v1beta | 很多 400 本质上是版本问题 |
| 3 | prompt / 文件 / 上下文大小 | 很多 500 和部分 400 都跟体积有关 |
| 4 | 项目与 billing account | 429 很多时候卡在这一层 |
| 5 | 同一 payload 换模型是否通过 | 快速区分请求错误与模型状态问题 |
如果这是生产业务,请再补一条纪律:不要让“API 报错了”成为你日志里的唯一有效信息。至少记住模型、接口版本、请求体积和归一化后的错误分类。长期来看,这比背多少错误码都更有用。
生产环境重试模板:哪些该重试,哪些要立即失败
重试逻辑真正重要的不是 sleep 函数写成什么样,而是哪些错误允许重试,哪些错误必须尽快失败。Gemini 的通用原则可以简化成一句话:对 429、500、503、504 这类瞬态错误做有限次退避重试;对 400、401、403、404 这类确定性错误直接失败并把错误体打全。
Python
pythonimport random import time from google import genai from google.genai import errors client = genai.Client(api_key="YOUR_GEMINI_API_KEY") RETRYABLE = {429, 500, 503, 504} FAIL_FAST = {400, 401, 403, 404} def generate_with_retry(model: str, contents, max_retries: int = 5): for attempt in range(max_retries): try: return client.models.generate_content(model=model, contents=contents) except errors.ClientError as exc: status = getattr(exc, "code", None) message = str(exc) if status in FAIL_FAST: raise RuntimeError( f"Non-retryable Gemini error {status}: {message}" ) from exc if status in RETRYABLE and attempt < max_retries - 1: delay = min(2 ** attempt, 30) jitter = random.uniform(0, delay * 0.2) time.sleep(delay + jitter) continue raise RuntimeError( f"Retry budget exhausted after Gemini error {status}: {message}" ) from exc
Node.js
tsimport { GoogleGenAI } from "@google/genai"; const client = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY! }); const retryable = new Set([429, 500, 503, 504]); const failFast = new Set([400, 401, 403, 404]); export async function generateWithRetry(model: string, contents: string) { for (let attempt = 0; attempt < 5; attempt += 1) { try { return await client.models.generateContent({ model, contents }); } catch (error: any) { const status = error?.status ?? error?.code ?? 0; if (failFast.has(status)) { throw new Error(`Non-retryable Gemini error ${status}: ${error.message}`); } if (retryable.has(status) && attempt < 4) { const delayMs = Math.min(1000 * 2 ** attempt, 30000); const jitterMs = Math.random() * delayMs * 0.2; await new Promise((resolve) => setTimeout(resolve, delayMs + jitterMs)); continue; } throw error; } } }
上面这段代码最关键的地方不是指数退避的具体参数,而是分支逻辑:如果你把 400 一路重试下去,你是在把确定性问题放大成更多失败;如果你对 429 和 500 一次都不重试,你又会错过很多其实只需要几秒钟等待就能成功的请求。
让旧经验失效的 2026 变化
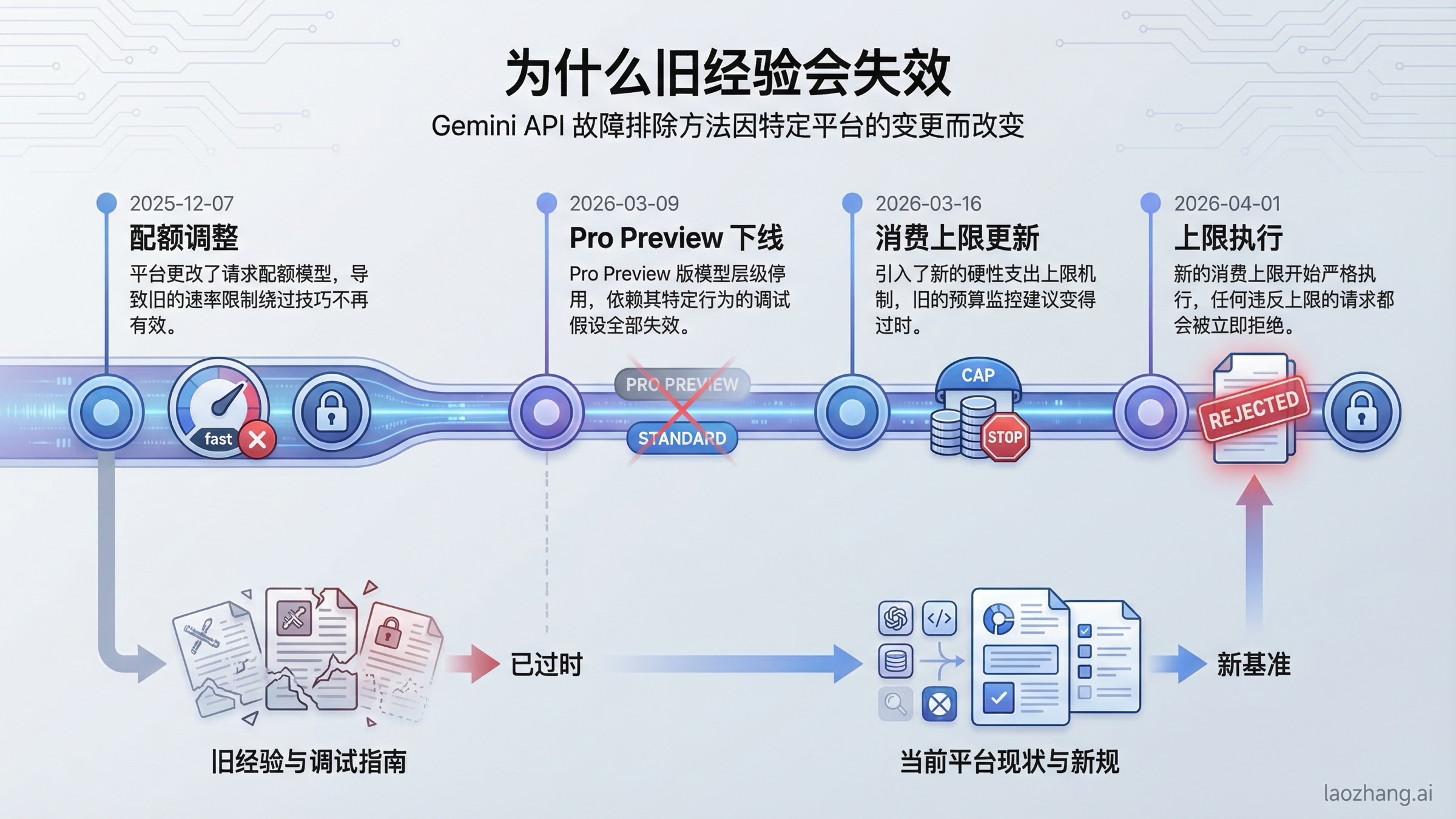
很多旧的 Gemini 排错文章默认平台是“静态不变”的,但这在 2026 年已经不成立了。下面这几条时间线,会直接影响你今天该如何理解错误:
| 日期 | 发生了什么 | 为什么会影响排错 |
|---|---|---|
| 2025-12-07 | Free Tier 与 Paid Tier 1 配额调整 | 很多应用在没改代码的情况下开始更容易报 429 |
| 2026-03-09 | Gemini 3 Pro Preview 下线 | 旧模型名、旧 alias 会突然变成新错误来源 |
| 2026-03-12 | AI Studio 引入项目级 spend cap | 预算控制开始进入故障排查范围 |
| 2026-03-16 | 使用层级与 billing account spend cap 更新 | 旧 tier 假设已经不可靠 |
| 2026-04-01 | tier spend cap 开始正式执行 | 达到上限后可能表现为“服务突然不可用” |
这也是为什么很多旧文章看起来“道理没错,但还是不好用”。问题不在于它们每一句都错误,而在于它们没有把建议绑定到具体日期,所以你分不清那是长期有效的规则,还是已经被平台变化淘汰的经验。
FAQ
失败请求会计费吗?
一般不会。Google 官方 billing FAQ 明确写着:返回 400 或 500 的请求不会按 token 收费,但仍然占用 quota。所以即便你没有直接增加费用,错误的重试策略也还是会拖垮配额。
Gemini 的限制是按 API Key 还是按项目算?
优先按项目和 billing account 理解,而不是按 key 理解。API Key 只是继承项目和账单账户状态,在同一个项目里多建一个 key,不会平白多出一份配额。
开通计费后多久应该生效?
Google 官方 rate limits 页面说明,从 Free 升到 Tier 1 通常会立即生效,后续更高 tier 一般在 10 分钟内完成。如果你明显超过这个传播时间,行为却还是像免费层,那就该优先排查项目、billing account 和 key 的绑定关系。
什么时候应该从 Gemini 2.5 Pro 切到 Gemini 2.5 Flash?
当同一份 payload 在 Flash 能跑、在 Pro 不稳定;当 500 与超长上下文明显相关;或者当你现在更需要“先恢复服务”而不是“保持最高推理质量”时,就应该果断切。Google 官方 troubleshooting guide 本身就把“从 Pro 暂时切到 Flash”作为 500 / 503 的官方缓解建议之一。
有没有一个官方页面能解决所有 Gemini 错误?
没有。官方 troubleshooting guide 是最好的起点,但在 2026 年你还需要同时结合 rate limits、billing、pricing、release notes 这些页面,才能把 429、400、500 判断准确。如果你需要更宽口径的全量参考,也可以看我们的 Gemini API 错误排查完全指南。