在使用 Gemini 3.1 Flash 生成图片时遇到了令人头疼的 429 RESOURCE_EXHAUSTED 错误?Gemini 3.1 Flash Image 429 限速错误意味着你已经超出了四种限速维度之一:RPM(每分钟请求数)、RPD(每日请求数)、TPM(每分钟令牌数)或 IPM(每分钟图片数)。你可以通过以下方式立即修复:实现带抖动的指数退避、升级计费层级获得最高6倍的更高限额、使用 Batch API 节省50%成本并享有独立配额、将请求分发到多个项目,或者通过 API 代理实现无限吞吐。本指南将带你精确诊断触发了哪种限制,并为你的使用场景选择正确的解决方案。
深入理解 Gemini 3.1 Flash Image 429 错误
当你的 Gemini 3.1 Flash Image API 调用返回 429 状态码时,响应体中包含了大多数开发者都会忽略的关键诊断信息。在急着寻找解决方案之前,理解错误结构能帮你定位到确切的瓶颈,而不是盲目地套用可能无法解决你特定问题的通用方法。429 错误是 Google 告诉你项目已经消耗完某个特定维度的配额,而如果你知道从哪里查看,响应实际上会告诉你具体是哪个维度。
以下是使用 Gemini 3.1 Flash Image Preview 模型触发限速时的实际错误响应:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.ErrorInfo", "reason": "RATE_LIMIT_EXCEEDED", "metadata": { "quota_limit": "GenerateContentRequestsPerMinutePerProjectPerRegion", "quota_limit_value": "10", "consumer": "projects/your-project-id", "quota_metric": "generativelanguage.googleapis.com/generate_content_requests" } } ] } }
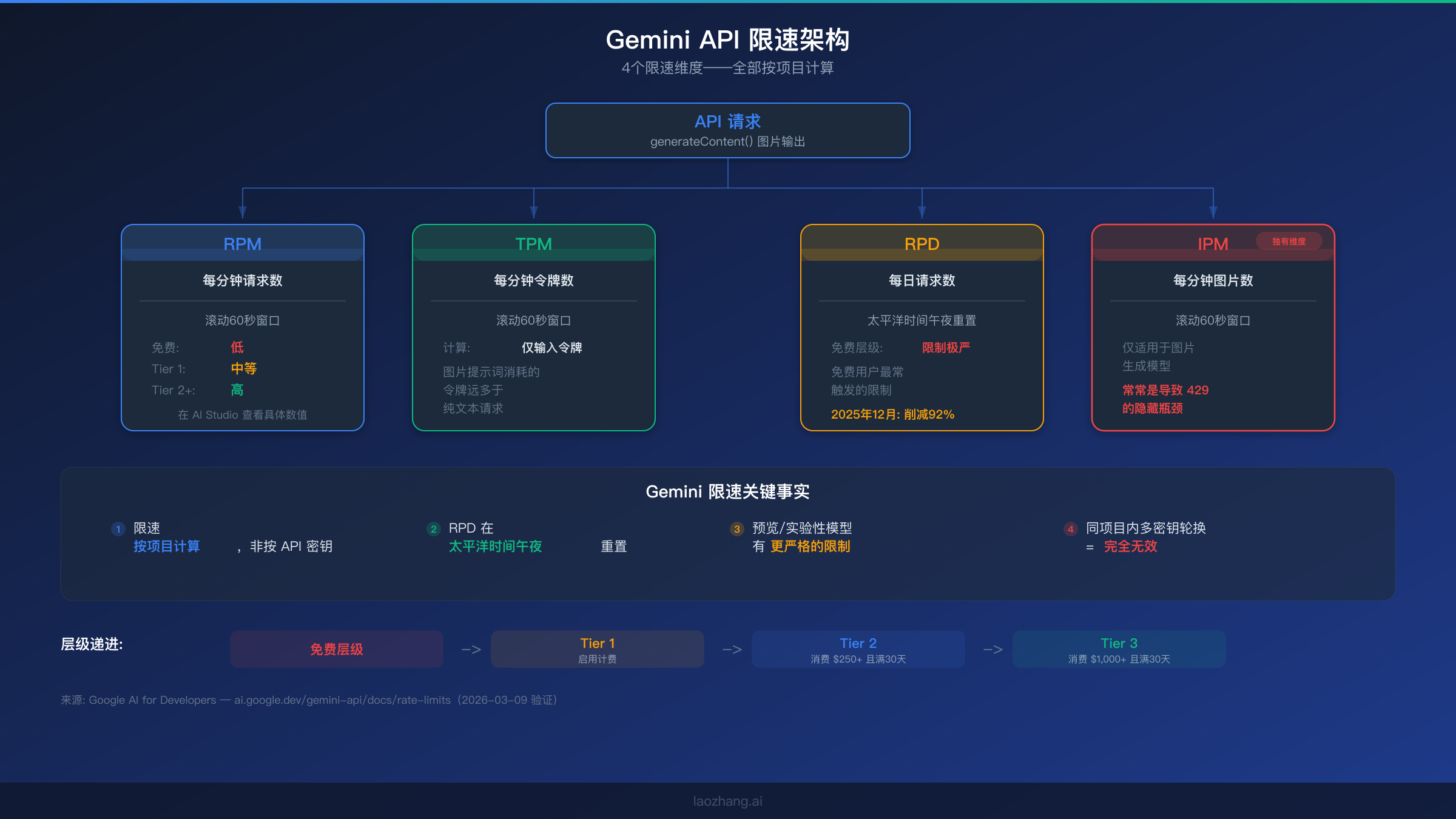
metadata.quota_limit 字段是诊断问题的关键,它准确地告诉你四种限速维度中哪一种已经耗尽。Google 的 Gemini API 在四个独立维度上实施限速,每个维度独立运作——这意味着你可能在 RPM 配额上还有很大余量,但日请求量 RPD 配额已经超标。理解这四个维度至关重要,因为 RPM 违规和 RPD 违规的修复方式是完全不同的。
Gemini 3.1 Flash Image Preview 的四种限速维度工作原理如下。RPM(每分钟请求数)统计你在滚动60秒窗口内发出的 API 调用次数,这是开发者在突发操作期间最常触发的限制。TPM(每分钟令牌数)在同一滚动窗口内跟踪消耗的总输入令牌数,这对图片生成特别重要,因为包含详细描述的图片提示词会比简单文本查询消耗明显更多的令牌。RPD(每日请求数)施加一个硬性的每日上限,在太平洋时间午夜重置——这在免费层级上限制尤为严格,Google 在2025年12月将配额削减了92%。最后,IPM(每分钟图片数)是 Gemini 3.1 Flash Image Preview 等图片生成模型特有的维度,它常常是开发者容易忽略的隐藏瓶颈,因为大家习惯了在纯文本模型中只考虑 RPM 和 TPM。
一个很多开发者不知道的关键事实:Gemini API 的限速是按项目计算的,而不是按 API 密钥。这意味着在同一个 Google Cloud 项目中创建多个 API 密钥,对限速完全没有任何帮助。如果你在一个项目中有三个密钥,这三个密钥共享同一个配额池。这个区别在我们讨论方案4——多项目分发策略时非常重要。
另外值得注意的是 429 错误和 503 错误的区别,因为两者都可能中断你的图片生成管线。429 意味着你已经消耗完分配的配额,需要等待或提高限额。503(服务不可用)表示 Google 端出现了临时的服务器端问题——在这种情况下,短暂延迟后简单重试通常就够了。修复策略差异很大,所以在应用解决方案之前检查状态码很重要。
快速诊断——你触发了哪种限速?
在应用任何修复方案之前,你需要确定到底是哪种限速维度被耗尽了。如果你实际上触发了每日 RPD 上限,却盲目地实现指数退避,那你的重试会持续失败好几个小时,直到太平洋时间午夜才会恢复。这种诊断方法能避免你在错误的方案上浪费时间,识别根本原因不到一分钟。
首先检查错误响应中的 quota_limit 字段。该值直接映射到四种维度之一,每种维度都有 Google 内部使用的不同字符串标识符。当你看到 GenerateContentRequestsPerMinutePerProjectPerRegion 时,表示触发了 RPM 限制——如果你暂停请求,这通常在60秒内就会恢复。如果字段显示 GenerateContentTokensPerMinutePerProjectPerRegion,则是 TPM 耗尽,意味着你的提示词消耗令牌的速度太快了。GenerateContentRequestsPerDayPerProjectPerRegion 值表示 RPD 违规,这是最令人沮丧的,因为它要到太平洋时间午夜才会重置。如果你遇到 GenerateContentImagesPerMinutePerProjectPerRegion,则是触发了专门针对图片输出的 IPM 上限——这个限制只适用于图片生成模型变体。
如果你的错误响应不包含详细的 metadata 对象(某些旧版 SDK 会出现这种情况),可以用排除法来判断。检查过去60秒的请求频率——如果你一直在快速连续调用,RPM 或 IPM 很可能是罪魁祸首。如果你整天都在运行批处理任务,检查总每日请求数是否超出了你层级的 RPD 分配。你可以访问 Google AI Studio 的配额页面验证当前层级及其关联限制,该页面会显示每个维度的实时使用量和剩余容量。
以下决策流程帮你快速缩小问题范围,直接跳转到最相关的解决方案:
- 错误出现在快速连续的 API 调用期间(几秒内)? → 很可能是 RPM 或 IPM。应用方案1(指数退避)获得即时缓解,然后考虑方案2(层级升级)做永久修复。
- 错误出现在全天持续使用后? → 很可能是 RPD。等到太平洋时间午夜,或应用方案2(层级升级)增加每日配额。
- 错误出现在使用很长或很详细的提示词时? → 很可能是 TPM。简化你的提示词或应用方案1分散请求。
- 你在免费层级上很快就触发了限制? → 最可能是 RPD(免费层级 RPD 在2025年12月被削减了92%)。方案2(启用计费升级到 Tier 1)是最快的永久修复方案。
你还可以通过检查 Google Cloud 计费状态以编程方式查看当前层级。免费层级用户在所有四个维度上都有最严格的限制。升级到 Tier 1 只需要在项目上启用计费账户——限速提升通常在几分钟内就会生效。如需了解各层级详细的限速明细,请查阅我们的专项指南,其中列出了每个模型变体的精确配额。
还有另一个值得一提的诊断技巧,适合希望主动而非被动监控配额消耗的开发者。Google Cloud Console 提供了「配额和系统限制」页面,你可以在其中查看每个限速维度的实时使用量图表。导航到你项目的 IAM 和管理部分,然后选择配额。筛选 "generativelanguage.googleapis.com" 即可看到所有 Gemini API 配额。这些图表展示了你的使用模式随时间变化的情况,能轻松发现你是持续接近某个特定限制还是只是偶尔出现峰值。设置配额告警也是可行的——你可以配置在50%、80%和90%使用率阈值时发送通知,在应用开始收到 429 错误之前给你预警。这种主动监控对于限速错误直接影响用户体验的生产系统尤其有价值。
方案1——指数退避与智能重试逻辑
指数退避是抵御 429 错误的第一道防线,应该在每个调用 Gemini API 的生产应用中实现,无论你还应用了其他什么方案。概念很简单:当收到 429 响应时,等待递增的时间后再重试。但简单地将等待时间翻倍的朴素实现,在多个实例同时重试时可能会造成雷群效应。为退避间隔添加随机抖动能更均匀地分散重试尝试,显著降低在限速边界上反复冲突的概率。
Python 实现
下面的 Python 实现使用 google-generativeai SDK 和自定义重试包装器,能智能处理不同类型的限速。对于基于 RPM 的限制,使用较短的初始延迟,因为窗口每60秒重置。对于 RPD 限制,策略会切换到更长的延迟,或者抛出异常提示重试在每日重置前是无效的。
pythonimport time import random import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0): """Generate image with exponential backoff and jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Non-rate-limit error, don't retry if "PerDay" in error_str: print("Daily limit reached. Retrying won't help until midnight PT.") raise # Exponential backoff with full jitter delay = base_delay * (2 ** attempt) + random.uniform(0, 1) delay = min(delay, 60) # Cap at 60 seconds print(f"Rate limited. Retry {attempt + 1}/{max_retries} in {delay:.1f}s") time.sleep(delay) raise Exception("Max retries exceeded")
Node.js 实现
对于 Node.js 应用,实现遵循相同的模式,但使用 async/await 语法和 @google/generative-ai 包。抖动计算使用 Math.random() 为延迟间隔添加随机性,防止多个服务器实例的同步重试。
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); async function generateImageWithRetry(prompt, maxRetries = 5, baseDelay = 1000) { const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseMimeType: "image/png" } }); return result; } catch (error) { const msg = error.message || ""; if (!msg.includes("429") && !msg.includes("RESOURCE_EXHAUSTED")) throw error; if (msg.includes("PerDay")) { throw new Error("Daily limit reached. Wait until midnight PT."); } const delay = Math.min(baseDelay * Math.pow(2, attempt) + Math.random() * 1000, 60000); console.log(`Rate limited. Retry ${attempt + 1}/${maxRetries} in ${(delay/1000).toFixed(1)}s`); await new Promise(resolve => setTimeout(resolve, delay)); } } throw new Error("Max retries exceeded"); }
在生产环境中让指数退避良好运作有几个细节需要注意。首先,始终设置最大延迟上限(对于 RPM 限制,60秒是合理的),防止在持续限速期间出现过长的等待。其次,考虑在重试逻辑之上实现熔断器模式:如果你连续收到五个 429 错误,暂时停止所有请求进入冷却期,而不是继续反复调用 API。这不仅对 Google 基础设施更友好,也能让你的配额更快恢复。第三,记录每次 429 遭遇的完整错误详情,包括 quota_limit 字段——这些数据对理解你的使用模式、决定何时升级层级或切换到更可扩展的方案非常宝贵。
虽然指数退避是必不可少的,但理解其局限性也很重要。它能很好地处理临时的 RPM 峰值,但无法解决结构性问题,比如持续超出层级的每日限额,或者需要超出分配速率的持续吞吐。把它看作安全网,而不是扩展策略。如果你发现超过10-15%的请求依赖重试,就该考虑接下来更根本性的解决方案了。
方案2——升级 API 层级获取更高限额
升级 Google Cloud 计费层级是永久提高所有四个维度限速的最直接方式。Google 的层级系统旨在随着你通过消费阈值和账户年限证明合法使用量而逐步解锁更高配额。对于许多开发者来说,仅仅启用计费(从免费层级升到 Tier 1)就能立即大幅增加可用容量,通常无需任何代码更改就能解决 429 错误。
层级系统的工作方式如下(来自 Google AI for Developers 文档,2026-03-09 验证):免费层级对符合条件的国家和地区的用户可用,具有最严格的限制,且在2025年12月进一步缩减。Tier 1 需要将付费计费账户链接到你的 Google Cloud 项目,升级通常在几分钟内生效。Tier 2 要求总消费超过 $250 且首次付款后至少30天。Tier 3 要求总消费超过 $1,000,同样需要至少30天。每个层级在 RPM、TPM、RPD 和 IPM 上都有显著更高的限额——仅 Tier 1 通常就比免费层级提升3-6倍。
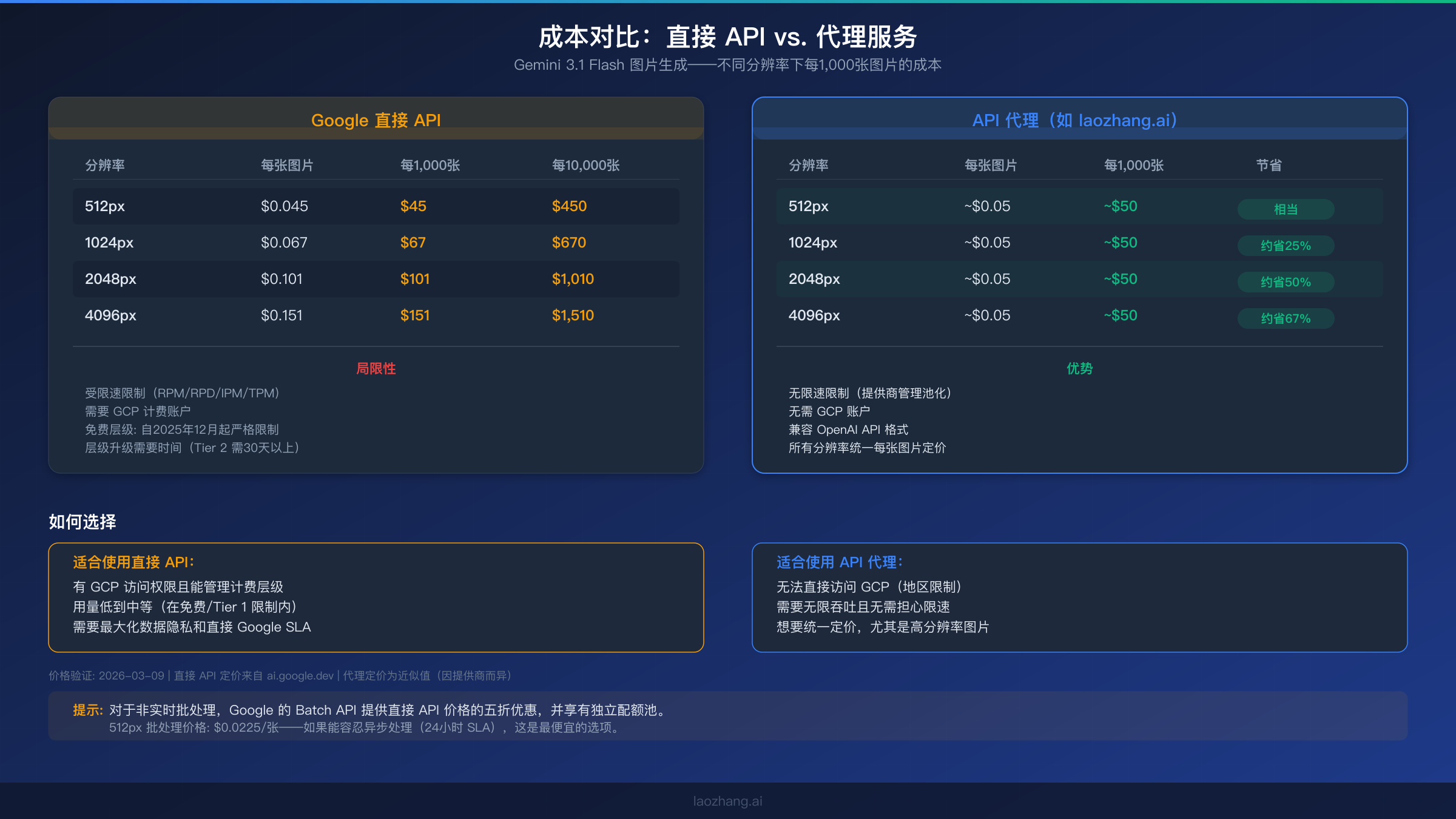
升级层级的成本考量很大程度上取决于你的使用模式。如果你每天生成的图片少于一百张,免费层级在突发时段之外技术上可能就够了,但你会持续与 RPD 限制作斗争。启用计费并不意味着你会立即花钱——你只需为超出免费配额的使用付费。Gemini 图片生成定价取决于分辨率:512px 每张 $0.045,1024px 每张 $0.067,2048px 每张 $0.101,4096px 每张 $0.151(Google AI for Developers,2026-03-09 验证)。对于每天在1024px分辨率下生成500张图片的生产应用,每日成本约为 $33.50——考虑到可靠性的提升,这是一笔合理的投资。
要升级层级,导航到 Google AI Studio 或 Google Cloud Console 并在项目上启用计费。流程很简单:如果没有计费账户就创建一个,将其链接到你的 API 项目,层级升级大约在10分钟内就会生效。要达到 Tier 2 及以上,主要要求是累计消费,这在使用 API 的过程中自然会发生。没有单独的申请或审批流程——只需要持续使用直到跨过消费阈值。
一个重要的规划说明:Tier 2 和 Tier 3 的30天等待期意味着你无法加速升级路径。如果你预计不久的将来会需要更高限额,最佳策略是尽早启用计费(即使当前使用量很小),以便开始计时。这样,当你的应用扩展并需要 Tier 2 限额时,你已经满足了时间要求。
以下是不同使用场景的实用成本效益分析,帮你判断哪个层级合适。如果你每天在1024px分辨率下生成约100张图片,Tier 1 的每日成本约为 $6.70,即每月约 $200。如果每天1,000张图片——这是生产级 SaaS 应用的常见阈值——你每天约需 $67 或每月 $2,000,这使你在第一个月内就能达到 Tier 2 的资格。对于每天生成 10,000+ 图片的高量级操作,1024px 分辨率下每天的成本达到 $670,但在这个规模下,你应该认真考虑 Batch API(方案3)或 API 代理(方案5)以获得实质性的成本节省。关键洞察是,每张图片的成本在各层级之间保持不变——变化的只是吞吐上限,而不是每次生成的价格。
方案3——Batch API 用于大批量图片生成
Batch API 是 Google 官方推荐的大批量图片生成方案,但它仍然被严重低估,因为大多数竞品指南要么完全跳过它,要么只是顺带一提。Batch API 提供两个关键优势:它在与实时 API 完全独立的配额系统上运行(意味着批处理请求不会计入你的 RPM/RPD/IPM 限额),并且所有生成成本享受50%折扣。权衡是批处理请求以异步方式处理,SLA 为24小时,因此这个方案非常适合不需要即时返回图片的工作流。
Batch API 的配额以排队令牌数而非每分钟请求数衡量,即使在较低层级,限额也很宽裕。Tier 1 项目可以排队最多1,000,000个令牌的批处理请求,Tier 2 解锁250,000,000个排队令牌,Tier 3 提供750,000,000个(Google AI for Developers 限速页面,2026-03-09 验证)。作为参考,一个50-100词的典型图片生成提示词大约使用70-130个令牌,这意味着 Tier 1 的批处理队列可以同时容纳约7,700-14,300个图片生成请求。
Python 批处理实现
以下是一个完整的工作示例,创建批处理任务、轮询完成状态并检索生成的图片:
pythonimport google.generativeai as genai import time genai.configure(api_key="YOUR_API_KEY") batch_requests = [] prompts = [ "A serene mountain landscape at sunset, photorealistic", "A futuristic city skyline with flying vehicles", "An underwater coral reef teeming with colorful fish" ] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"img-{i}", "method": "POST", "url": "/v1beta/models/gemini-3.1-flash-image-preview:generateContent", "body": { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseMimeType": "image/png"} } }) # Step 2: Submit batch job # Note: Use the REST API or batch-specific SDK methods # The exact SDK interface may vary — check current documentation import requests, json headers = {"Content-Type": "application/json"} api_url = "https://generativelanguage.googleapis.com/v1beta/batchJobs" response = requests.post( f"{api_url}?key=YOUR_API_KEY", headers=headers, json={"requests": batch_requests} ) job = response.json() job_name = job.get("name") print(f"Batch job created: {job_name}") # Step 3: Poll for completion while True: status_resp = requests.get(f"{api_url}/{job_name}?key=YOUR_API_KEY") status = status_resp.json() state = status.get("state", "UNKNOWN") print(f"Job state: {state}") if state in ("SUCCEEDED", "FAILED", "CANCELLED"): break time.sleep(30) # Check every 30 seconds # Step 4: Retrieve results if state == "SUCCEEDED": results = requests.get(f"{api_url}/{job_name}/results?key=YOUR_API_KEY") for result in results.json().get("responses", []): custom_id = result["custom_id"] # Process each generated image print(f"Image {custom_id} generated successfully")
使用 Batch API 时有几个实际注意事项。24小时 SLA 是最大值——实际上,大多数批处理任务完成得快得多,通常在1-4小时内,取决于队列深度和任务大小。你应该设计应用以合理的间隔(每30-60秒)轮询任务状态,而不是实现阻塞等待。批处理模式的错误处理与实时调用不同:批处理中的各个请求可以独立失败,所以你的结果处理代码需要检查每个响应的状态,并为失败的项目实现重试逻辑。另外注意,批处理队列令牌限制计算的是所有排队中(尚未完成)的任务,所以你应该避免提交超出合理时间内可处理量的工作。
Batch API 在以下场景中表现出色:电商产品图片生成(一夜之间处理数百个产品描述)、内容营销管线(批量生成社交媒体视觉素材)以及机器学习训练数据集的创建。任何能容忍分钟到小时级延迟——而非需要亚秒响应——的工作流,都应该认真考虑 Batch API,既能节省成本又能免受导致 429 错误的实时限速影响。如需更全面地了解成本优化方法,请参阅我们的 Gemini 图片限速解决方案指南。
方案4——多项目请求分发
由于 Gemini API 的限速是按项目而非按 API 密钥实施的,你可以通过将请求分发到多个 Google Cloud 项目来有效地成倍增加总可用配额。这种方法在技术上很简单:创建 N 个项目,为每个项目生成一个 API 密钥,然后在你的应用代码中实现轮询或负载均衡的分发策略。使用三个项目,你就能有效地将 RPM、RPD、IPM 和 TPM 限额提升三倍,无需任何层级升级或额外的每项目支出。
实现需要维护一个 API 密钥池(每个项目一个)并为每个请求循环使用。以下是一个生产级就绪的实现,同时处理分发和当单个项目触发限制时的回退:
pythonimport itertools import random class MultiProjectClient: def __init__(self, api_keys: list[str]): self.api_keys = api_keys self.key_cycle = itertools.cycle(api_keys) self.failed_keys = set() def generate_image(self, prompt, max_attempts=None): max_attempts = max_attempts or len(self.api_keys) * 2 for attempt in range(max_attempts): key = next(self.key_cycle) if key in self.failed_keys: continue try: genai.configure(api_key=key) model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: if "429" in str(e): self.failed_keys.add(key) if len(self.failed_keys) >= len(self.api_keys): self.failed_keys.clear() # Reset and retry raise Exception("All projects rate limited") else: raise raise Exception("Max distribution attempts exceeded") # Usage client = MultiProjectClient([ "API_KEY_PROJECT_1", "API_KEY_PROJECT_2", "API_KEY_PROJECT_3" ]) result = client.generate_image("A beautiful sunset over the ocean")
一个重要的架构考虑:确保每个 Google Cloud 项目都启用了自己的计费账户(或至少从一个计费账户共享计费到多个项目)。这确保每个项目独立地符合其层级的限速要求。你可以通过 Google Cloud Console 的项目选择器管理多个项目,单个 Google 账户可以拥有的项目数量在实际上没有限制。
关于服务条款合规性:Google 的文档明确说明"限速是按项目应用的",并提供了按项目的配额管理工具,这隐含地承认用户可能操作多个项目。只要每个项目是一个配置了正确计费的合法 Google Cloud 项目,这种方法不违反任何声明的条款。但是,有一些实际考虑需要注意——你需要管理多个项目的计费,分别监控配额,并处理部署管线中增加的复杂性。这个方案最适合已经在多项目 Google Cloud 环境中运营的团队。
方案5——API 代理实现无限吞吐
当你的应用需要超出 Tier 3 限额的持续高吞吐,或者无法直接访问 Google Cloud Platform(在某些地区的开发者中很常见)时,API 代理服务提供了最全面的 429 错误解决方案。API 代理通过维护跨多个项目和层级的大型 API 凭证池来工作,透明地分发你的请求以避免触发任何单个项目的限速。从你的应用角度来看,你只需向单个端点发送 API 调用,永远不会看到 429 错误,因为代理在幕后处理所有的限速管理。
在评估用于 Gemini 图片生成的 API 代理服务时,几个标准很重要。首先,检查代理是否支持你需要的特定模型——并非所有服务都支持 gemini-3.1-flash-image-preview 或其图片输出能力。其次,验证定价结构:有些代理按请求收费,有些按令牌收费,还有些使用固定的每张图片费用。第三,评估 API 兼容性——最好的代理提供与 OpenAI 兼容的 API 格式,意味着你只需更改现有代码中的 base URL 和 API 密钥即可切换,无需重写任何逻辑。最后,考虑可靠性保证,如正常运行时间 SLA、地理延迟和支持响应速度。
对于需要代理选项的开发者,laozhang.ai 等服务提供 Gemini 图片生成,大约 $0.05 每张图片的统一价格,不受分辨率影响——在较高分辨率下这代表了显著的节省,因为 Google 直接定价从 $0.101 到 $0.151。该平台聚合了多个模型和提供商,内部处理限速,且不需要 GCP 账户。你可以在图片生成测试平台上直接测试,然后再做决定。
与大多数 API 代理的集成过程非常简单,因为它们暴露了与 OpenAI 兼容的端点。在许多情况下,从直接 Google API 访问切换到代理只需要更改代码中的两个配置值——base URL 和 API 密钥。你现有的提示词格式、错误处理和响应解析逻辑通常无需修改即可工作。以下是一个最小示例,展示代理集成与直接 API 的区别:
python# Direct Google API import google.generativeai as genai genai.configure(api_key="GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") # Via API Proxy (OpenAI-compatible format) from openai import OpenAI client = OpenAI( api_key="PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": "A sunset over mountains"}] )
要判断 API 代理是否适合你的使用场景,考虑以下决策框架。在以下情况使用直接 Google API:你有可靠的 GCP 访问权限,你的量级在层级限制之内,且你需要最大化数据隐私和直接的 Google SLA。在以下情况使用 API 代理:你所在的地区 GCP 访问受限,你的吞吐需求超出了层级升级所能提供的范围,你想要简化计费而无需管理 GCP 项目,或者你正在构建原型且想完全避免 GCP 设置开销。如需了解不同提供商之间最便宜的 Gemini Flash Image API 选项,我们的对比指南覆盖了当前的市场格局。
选择你的修复方案——方案对比 + 常见问题
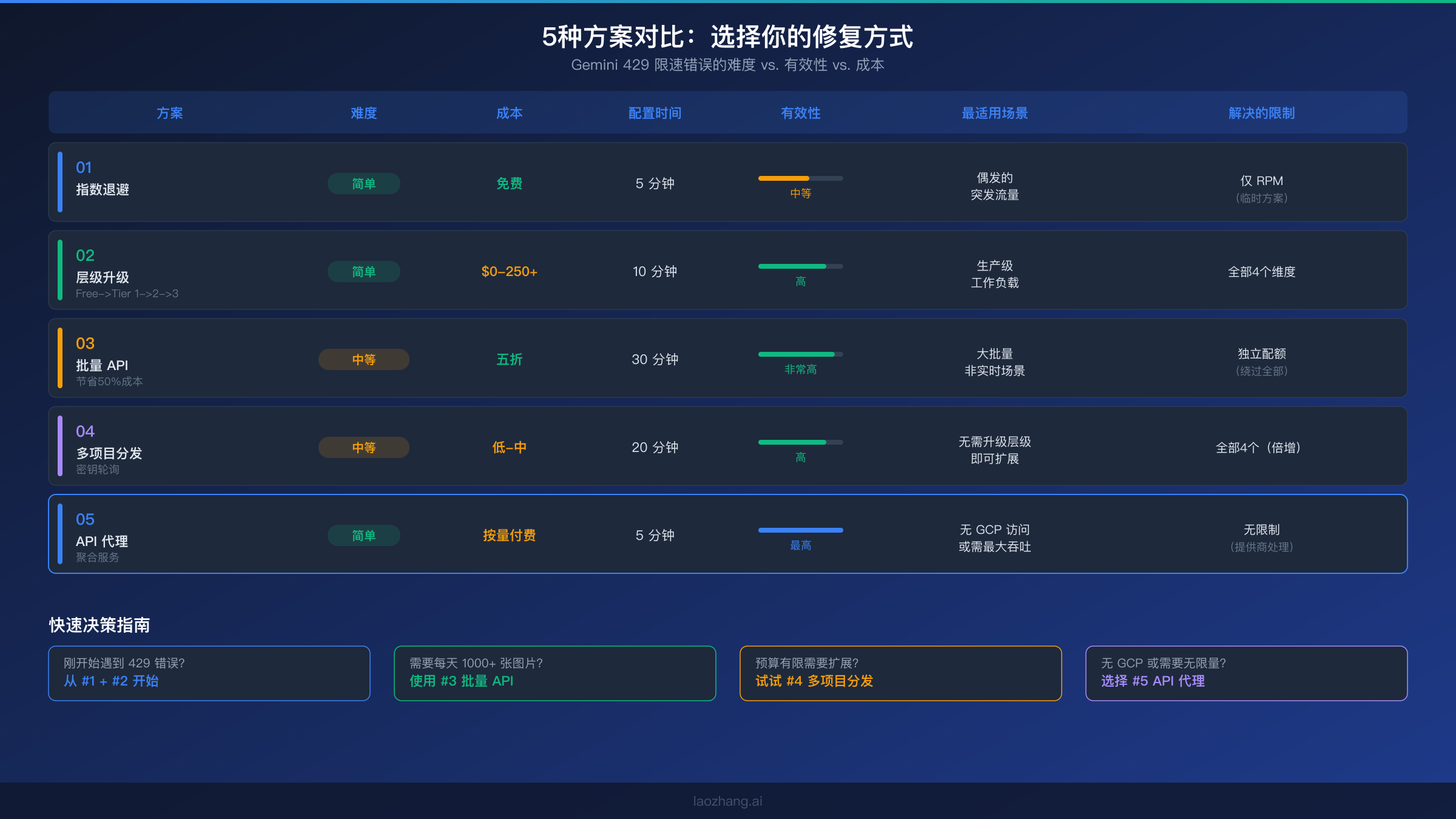
正确的方案取决于你的具体情况:修复错误的紧迫程度、预算限制、技术基础设施以及长期的吞吐需求。大多数生产环境部署都受益于组合使用多种方案——例如,实现指数退避(方案1)作为基础安全网,同时升级到 Tier 1 或 Tier 2(方案2)以获得持续容量。
以下是五种方案在最重要的决策因素上的对比总结。方案1和2是每个项目都应该实现的基础——退避提供韧性,层级升级提供容量。方案3、4和5是针对不同约束的扩展策略:Batch API 在延迟不关键时优化成本,多项目在 Google 生态系统内提供免费扩展,API 代理则提供最大简便性和无限吞吐。
对于刚开始使用 Gemini 图片生成并在免费层级上遇到 429 错误的开发者,最快的解决路径是:首先,实现指数退避以优雅地处理即时错误。其次,在项目上启用计费以达到 Tier 1——这通常是影响最大的单一改变,因为它在所有四个维度上都大幅增加了配额。这两个步骤解决了绝大多数开发和中低量级生产工作负载的 429 错误。
对于每天生成数千张图片的高量级生产工作负载,最优策略取决于你的延迟要求。如果图片可以异步生成(电商目录、营销内容管线、机器学习训练数据),Batch API(方案3)以50%折扣和独立的配额池提供最佳成本效益。如果你需要大规模的实时图片生成,将层级升级(方案2)与多项目分发(方案4)结合,以倍增你的有效限额。如果你想彻底消除限速的顾虑,API 代理(方案5)将所有配额管理卸载给提供商。
常见问题
Gemini API 的 429 限速持续多久?
对于 RPM、TPM 和 IPM 限制,窗口是滚动的60秒——意味着如果你停止发送请求,配额在一分钟内就会刷新。对于 RPD 限制,你必须等到太平洋时间午夜每日计数器才会重置。没有办法手动重置任何限速计数器;唯一的选项是等待自然重置或通过层级升级增加限额。
我可以向 Google 申请限速豁免吗?
Google 不为 Gemini API 提供个别限速豁免。层级系统是增加限额的指定途径。如果你需要超出 Tier 3 的限额,推荐的方法是联系 Google Cloud 销售团队签订企业协议,这可能包括自定义配额分配。
在同一个项目中使用多个 API 密钥有帮助吗?
没有。限速是按项目应用的,不是按 API 密钥。在单个项目中创建额外的密钥不会增加任何维度的配额。要从多个密钥中获益,每个密钥必须属于不同的 Google Cloud 项目(参见方案4)。
429 错误和 503 错误有什么区别?
429 错误意味着你已经超出了分配的配额——你需要等待配额刷新或增加限额。503 错误意味着 Google 服务本身暂时不可用,与你的使用量无关。对于 503 错误,1-5秒后简单重试通常就有效。对于 429 错误,你需要本指南中描述的针对性解决方案。
Batch API 会一直便宜50%吗?
Google 的 Batch API 定价自推出以来一直保持为实时 API 价格的50%。虽然定价可能会变化,但该折扣激励开发者使用批处理,这对 Google 的基础设施更高效。在做成本预测之前,请查看 Gemini 官方定价页面上的当前价格。
如何实时监控我的限速使用量?
Google Cloud Console 在 IAM 和管理 > 配额下提供实时配额监控。筛选 "generativelanguage.googleapis.com" 服务即可看到所有 Gemini API 配额及使用量图表。你还可以设置配额告警,在可配置的阈值(如80%使用率)时通知你,在生产环境中 429 错误出现之前给你预警。对于编程式监控,Cloud Monitoring API 允许你查询配额使用指标并将其集成到现有的仪表板或告警系统中。
有办法在不付费的情况下提高免费层级限额吗?
没有。免费层级限额是固定的,且在2025年12月已被大幅缩减。增加限速的唯一方法是在项目上启用计费(这会将你升级到 Tier 1),或者使用方案4中描述的多项目分发方法。Google 偶尔会调整免费层级配额,但趋势一直是朝着更严格的限制方向发展,这使得免费层级主要适合开发和实验,而不是生产工作负载。