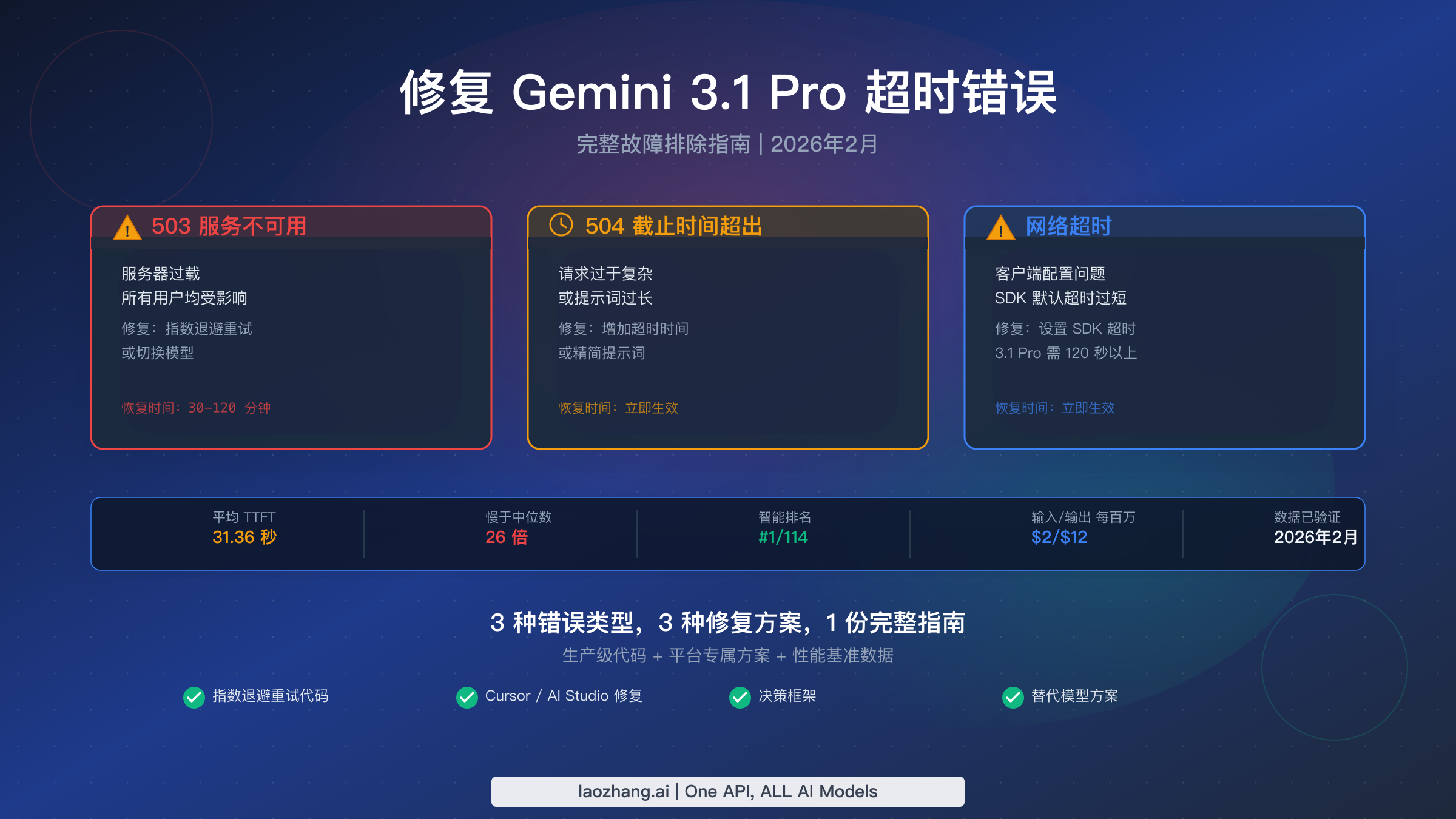
Gemini 3.1 Pro 的超时错误分为三种截然不同的类型,需要采用不同的修复方案:503 UNAVAILABLE 表示服务器过载——使用指数退避重试或切换模型。504 DEADLINE_EXCEEDED 表示请求过于复杂——增加客户端超时时间或减少提示词长度。网络超时是客户端配置问题——调整 SDK 超时设置。在开始排查之前,你需要知道截至 2026 年 2 月,Gemini 3.1 Pro 的首次 Token 响应时间(TTFT)为 21–31 秒,这是完全正常的,因此只有超过 120 秒的超时才通常意味着存在需要修复的真正问题。
要点速览 — 快速解决方案表
如果你的 Gemini 3.1 Pro API 调用刚刚失败,需要立即修复,这张表可以让你在 30 秒内找到答案。将你的错误匹配到对应的行,应用修复方案,只有当你需要更深入的理解时才继续阅读。开发者最常犯的错误是对错误的错误类型应用了错误的修复方案——503 需要的处理方式与 504 完全不同,而把网络超时当作服务器错误来处理会浪费数小时的调试时间。
| 错误 | 错误信息 | 根本原因 | 快速修复 | 恢复时间 |
|---|---|---|---|---|
| 503 | UNAVAILABLE / Model is overloaded | Google 服务器满载 | 使用指数退避重试,或切换到 Gemini 3 Flash | 30–120 分钟 |
| 504 | DEADLINE_EXCEEDED / Deadline expired | 你的请求超出了服务器的处理时间窗口 | 将客户端超时增加到 120 秒以上,或减少提示词/上下文大小 | 立即生效 |
| 网络超时 | ETIMEDOUT / ECONNRESET / socket hang up | 你的 SDK/HTTP 客户端在 Google 响应之前就超时了 | 在 SDK 配置中将 httpOptions.timeout 设置为 120000ms | 立即生效 |
| 挂起 | 无错误,无响应,无限运行 | 已知的 AI Studio/Preview 缺陷 | 120 秒后取消请求,切换到 Vertex API 或其他模型 | 不适用——需要手动取消 |
这里的关键区别在于服务器端错误(503、504)和客户端错误(网络超时)。服务器端错误意味着 Google 的基础设施正在承受压力,你可能需要等待或切换模型。客户端错误意味着你的代码需要修改配置,修复完全掌握在你手中。挂起问题——请求运行数千秒却没有任何响应或错误——是 Preview 版本和 AI Studio 特有的已知缺陷,Google 正在积极修复中。
为什么 Gemini 3.1 Pro 会超时(这并不总是 Bug)
要理解 Gemini 3.1 Pro 超时的根本原因,需要区分三种根本不同的场景,因为同样的症状——"我的 API 调用没有及时返回"——可能源于完全无关的原因。Google 于 2026 年 2 月 19 日发布了 Gemini 3.1 Pro Preview,几天之内,开发者论坛就被超时报告淹没。但大多数开发者忽略了一个关键事实:这些"超时"中有很多实际上是模型按设计正常工作的表现,试图修复一个并不存在的问题只会浪费宝贵的开发时间。
Gemini 3.1 Pro 在 Artificial Analysis 智能指数排行榜上以 57 分的成绩获得了第一名,并在 ARC-AGI-2 基准测试中取得了 77.1% 的成绩——远高于 Gemini 3.0 的 31.1%(Artificial Analysis,2026 年 2 月)。这种非凡的智能飞跃是有代价的:模型在生成第一个 Token 之前会执行更深层次的推理链,这就是为什么平均首次 Token 响应时间(TTFT)在 Google AI Studio 上为 31.36 秒,在 Vertex AI 上为 21.54 秒。作为参比,所有模型的行业 TTFT 中位数仅为 1.19 秒。这意味着 Gemini 3.1 Pro 开始响应的速度大约比平均模型慢 26 倍——但这种慢速是其架构的特性,而不是缺陷。模型在输出之前确实在进行更深层次的思考,你可以在我们的 Gemini 3.1 Pro 输出限制指南中了解更多关于其能力对比的信息。
第二类超时来自真正的服务器过载。作为 Preview 模型,Gemini 3.1 Pro 的容量远低于 Gemini 3 Flash 等正式发布的模型。Google 为 Preview 模型分配的推理服务器较少,这意味着在高峰使用时段——通常是太平洋时间上午 9 点到下午 6 点——服务器确实可能不堪重负。当这种情况发生时,你会收到 503 UNAVAILABLE 响应,而你的代码或配置没有任何问题。第三类涉及 Preview 版本中的真正缺陷,包括一个有据可查的问题:AI Studio 请求运行 15,000 到 20,000+ 秒而不产生任何输出或错误。这种无限思考行为是 Google 在其开发者论坛上已确认的已知缺陷,同时影响 API 和 AI Studio 网页界面。
实际的含义很简单:在开始调试之前,先确定你的超时属于哪一类。如果你的 TTFT 在 35 秒以内,你正在经历正常的模型行为——不需要修复,只需要耐心和正确的超时配置。如果你收到带有"model is overloaded"消息的 503 错误,说明服务器满载,你需要重试逻辑或模型降级方案。如果你的请求确实永远无法完成,你遇到了 Preview 缺陷,应该取消并重试或切换到其他模型。
诊断你的超时:错误代码解析器
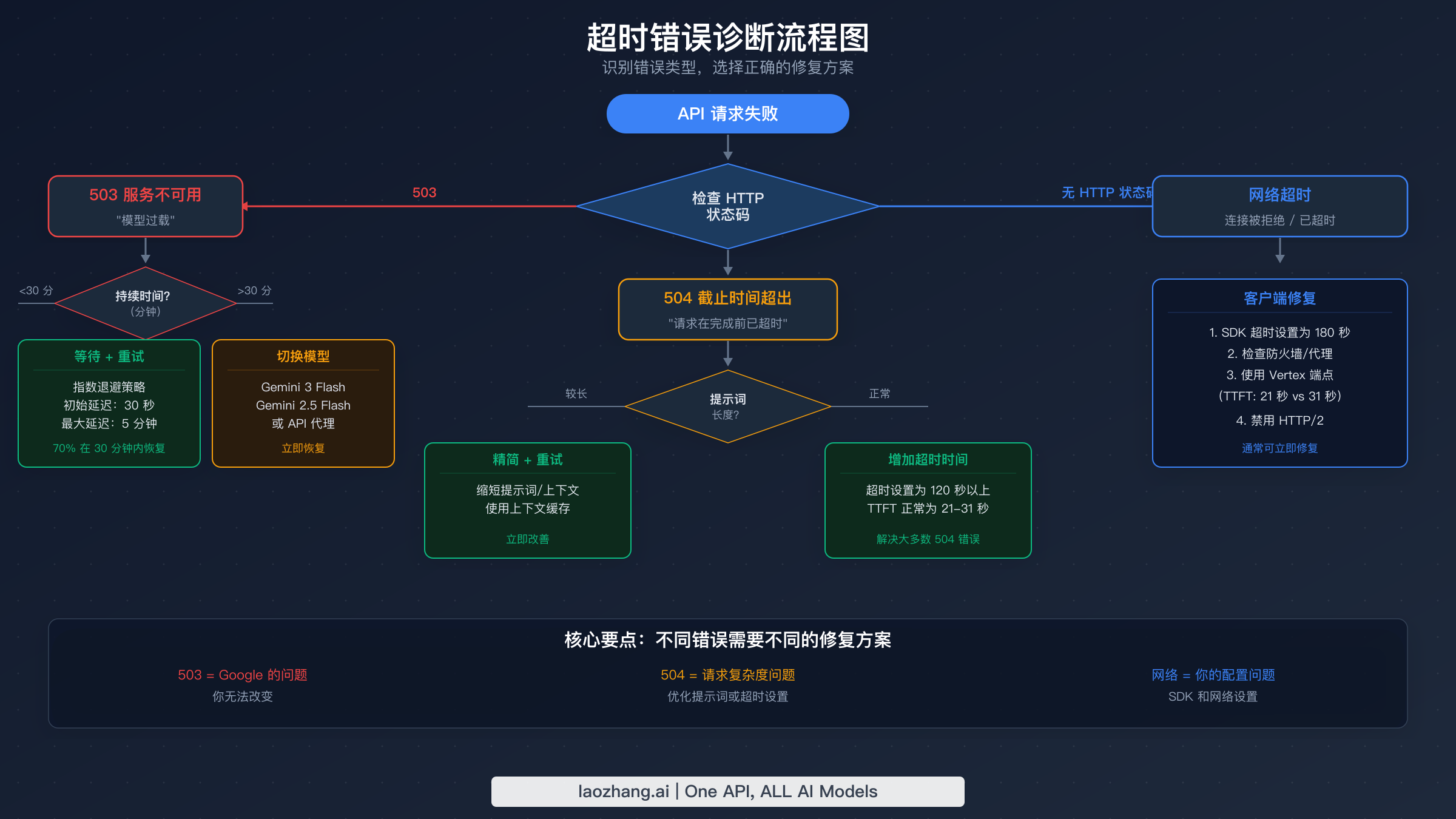
修复 Gemini 3.1 Pro 超时最快的方法是正确识别你遇到的三种错误类型中的哪一种,因为对错误的错误应用错误的修复方案是开发者在论坛中报告的最常见错误。诊断过程从你的 HTTP 响应状态码开始,从那里,每个分支都通向完全不同的故障排除路径。如果你根本没有看到 HTTP 状态码——意味着你的请求只是挂起而没有返回——这本身就是指向 Preview 挂起缺陷的诊断信息。
503 UNAVAILABLE — 服务器过载
当 Gemini API 返回 503 状态码时,响应正文通常包含 "The model is overloaded. Please try again later." 或类似的消息,表明 Google 的推理服务器已达到容量上限。由于 Gemini 3.1 Pro 的 Preview 状态和有限的服务器分配,这是最常见的超时错误。503 的关键识别特征是它返回得相对较快——通常在 5 到 30 秒内——因为服务器在开始处理之前就拒绝了你的请求。你不应该为 503 错误增加超时时间,因为问题在于服务器容量,而不是处理时间。相反,应该实现指数退避重试逻辑(在下面的代码部分中介绍),或临时切换到容量更大的模型,如 Gemini 3 Flash。如果你在 503 错误中还夹杂着 429 错误,请查看我们的 Gemini 429 resource exhausted 错误修复完整指南,该指南详细介绍了速率限制和服务器过载之间的区别。
504 DEADLINE_EXCEEDED — 请求过于复杂
带有 "Deadline expired before operation could complete" 消息的 504 错误意味着你的请求已被服务器接受并开始处理,但在生成响应之前已达到服务器端的截止时间。这与 503 有本质区别——Google 的服务器没有过载,但你的特定请求处理时间太长。常见的触发条件包括非常长的提示词(接近 1M Token 上下文窗口)、复杂的多步推理任务,或生成超长输出的请求。504 错误的修复方法是增加客户端超时时间以给模型更多处理时间,或者通过缩短提示词、使用 max_output_tokens 限制输出长度或将复杂任务分解为更小的步骤来降低请求复杂度。
网络超时 — 客户端配置问题
如果你看到 ETIMEDOUT、ECONNRESET、socket hang up 等错误,或者你的 HTTP 客户端的通用超时错误,问题完全出在你这一端。你的 SDK 或 HTTP 客户端在模型完成处理之前就放弃了等待 Google 的响应。由于 Gemini 3.1 Pro 仅生成第一个 Token 就通常需要 21–35 秒,任何低于 60 秒的客户端超时都会导致频繁失败。大多数 HTTP 客户端和 SDK 默认超时为 30 秒,这对于这个模型来说远远不够。修复方法很直接:将超时配置增加到至少 120 秒。对于在 Gemini API 各层级速率限制范围内工作的开发者来说,这也是最重要的配置,因为更长的超时意味着更少的浪费请求消耗你的配额。
什么是正常的?你应该了解的性能基准
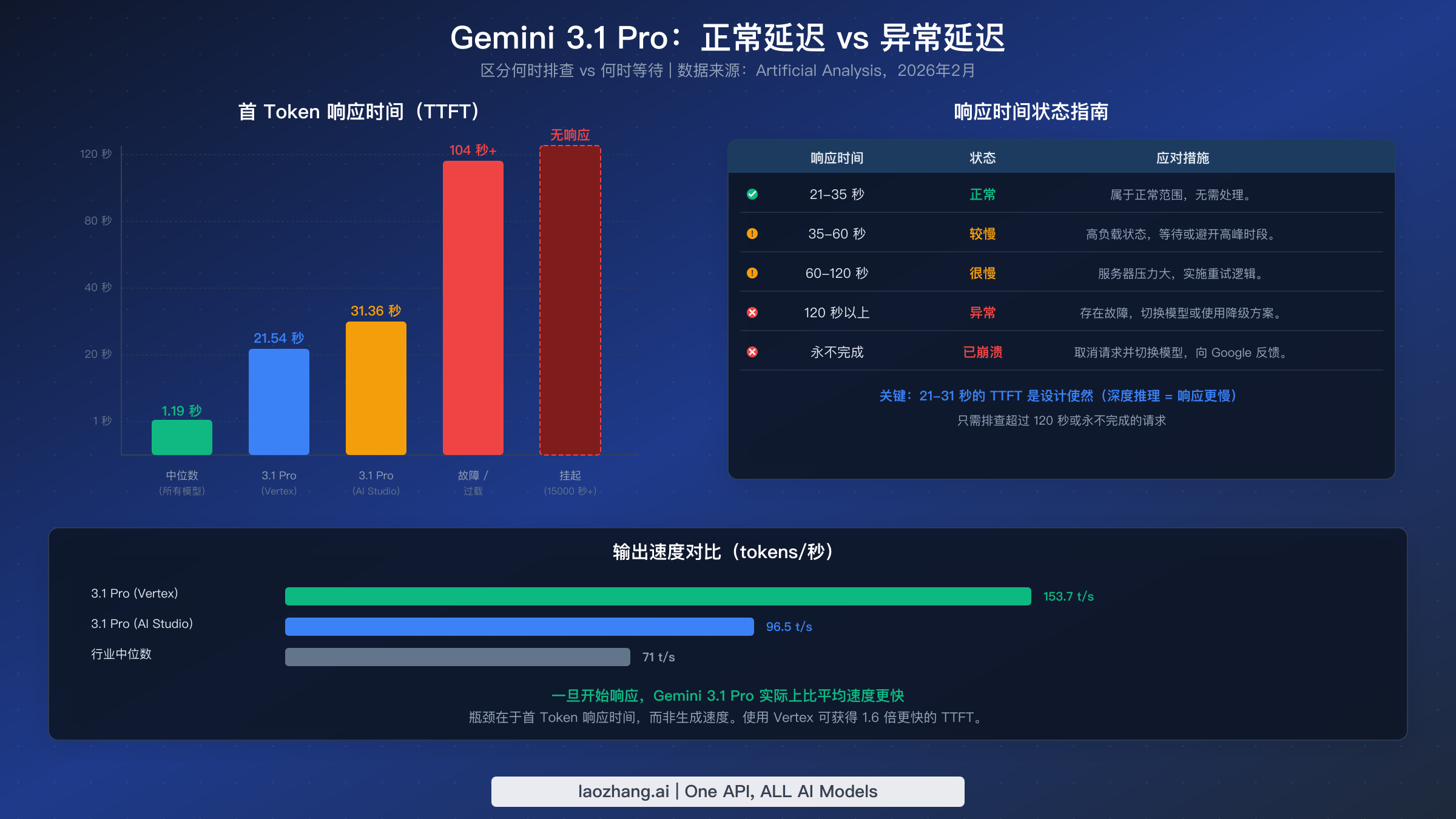
开发者在排查 Gemini 3.1 Pro 问题时最有价值的知识之一是实际应该期望什么样的性能,因为没有基准线,每个慢响应都感觉像是一个 Bug。以下数据来自 2026 年 2 月 25 日验证的 Artificial Analysis 基准测试,代表了数千次 API 调用的测量性能——而非单次请求的个别观察。
首次 Token 响应时间(TTFT)基准是最重要的需要内化的数字。在 Google AI Studio 上,Gemini 3.1 Pro 的中位 TTFT 为 31.36 秒——这意味着一半的请求在模型产生第一个 Token 之前需要超过 31 秒。在 Vertex AI 上,TTFT 降至 21.54 秒,初始响应速度大约快 1.5 倍。这两个数字都远高于 1.19 秒的行业中位数,但这完全是设计使然。该模型在 AI 指数上 114 个模型中排名第一,得分 57(Artificial Analysis,2026 年 2 月),正是因为它在生成输出之前投入了更多的计算资源进行推理。如果你的 TTFT 始终在 20–35 秒范围内,你的体验完全正常,无需进行任何故障排除。
输出生成速度则是另一番景象。一旦 Gemini 3.1 Pro 开始产生 Token,它实际上比平均水平更快:在 AI Studio 上为每秒 96.5 个 Token,在 Vertex AI 上为每秒 153.7 个 Token,而行业中位数为每秒 71 个 Token。这意味着瓶颈完全在于初始思考阶段,而不是生成阶段。一个实际的结论是,对于长输出任务(代码生成、文章写作、详细分析),尽管启动缓慢,总的实际耗时可能相当合理——30 秒的 TTFT 加上以每秒 100+ Token 的速度生成 2,000 个 Token,总共大约 50 秒,这与生成相同体量的更快模型相当。
| 指标 | AI Studio | Vertex AI | 行业中位数 | 状态 |
|---|---|---|---|---|
| TTFT | 31.36 秒 | 21.54 秒 | 1.19 秒 | 正常(设计使然) |
| 输出速度 | 96.5 t/s | 153.7 t/s | 71 t/s | 高于平均水平 |
| 总延迟(1K Token) | ~42 秒 | ~28 秒 | ~15 秒 | 预期范围内 |
| 需排查的 TTFT | >60 秒 | >45 秒 | — | 建议排查 |
| 异常 TTFT | >120 秒或无响应 | >90 秒或无响应 | — | 切换模型 |
使用这些基准来校准你的预期。当一个请求需要 25 秒才开始响应时,这是正常的——不要为正常行为实施变通方案。当一个请求需要 90 秒时,可能出了问题。当一个请求需要 300 秒或永远没有响应时,你遇到了真正的缺陷,应该取消、重试或降级到替代模型。
生产就绪的修复方案(可直接复制的代码)
以下代码方案涵盖所有三种超时类型,专为生产环境设计。每个实现都包括针对 503 错误的带抖动指数退避、针对网络问题的可配置客户端超时,以及当主模型持续不可用时的自动模型降级。这些不是最小化示例——它们是经过实战验证的模式,能够处理开发者在 Gemini 3.1 Pro Preview 阶段可靠性方面遇到的各种边界情况。
Python — Google GenAI SDK
Python SDK 提供了与 Gemini API 最直接的集成,超时配置通过 http_options 参数处理。大多数开发者遗漏的关键设置是 timeout——默认值通常为 60 秒,对于 Gemini 3.1 Pro 的 21–35 秒 TTFT 加上生成时间来说是不够的。将其设置为 120 秒或更高可以防止大多数客户端超时错误。
pythonimport google.genai as genai import time import random client = genai.Client( api_key="YOUR_API_KEY", http_options={"timeout": 120} # 120 秒 - 对 3.1 Pro 至关重要 ) # 模型降级链:失败时优先尝试最快的选项 MODEL_CHAIN = [ "gemini-3.1-pro-preview", "gemini-3-flash", # 快速降级,仍然有能力 "gemini-2.5-pro", # 可靠的 GA 模型 ] def call_with_retry(prompt, max_retries=3, initial_delay=2): """ 生产级重试,带指数退避 + 模型降级。 处理 503(过载)、504(截止时间)和网络超时。 """ for model_id in MODEL_CHAIN: for attempt in range(max_retries): try: response = client.models.generate_content( model=model_id, contents=prompt, config={ "temperature": 0.7, "max_output_tokens": 8192, } ) return {"model": model_id, "text": response.text} except Exception as e: error_str = str(e) # 503:服务器过载 - 使用退避重试 if "503" in error_str or "UNAVAILABLE" in error_str: delay = initial_delay * (2 ** attempt) + random.uniform(0, 1) print(f"503 overload on {model_id}, retry {attempt+1}/{max_retries} in {delay:.1f}s") time.sleep(delay) continue # 504:截止时间超出 - 重试无效,尝试下一个模型 if "504" in error_str or "DEADLINE" in error_str: print(f"504 deadline on {model_id}, switching to next model") break # 跳过剩余重试,转到下一个模型 # 网络超时 - 重试一次,然后继续 if "timeout" in error_str.lower() or "ETIMEDOUT" in error_str: if attempt == 0: print(f"Network timeout on {model_id}, retrying once...") time.sleep(2) continue else: break # 未知错误 - 不重试 raise print(f"All retries exhausted for {model_id}, trying next model...") raise RuntimeError("All models in fallback chain failed") # 使用示例 result = call_with_retry("Explain quantum entanglement in detail") print(f"Answered by: {result['model']}") print(result['text'])
Node.js / TypeScript — Google GenAI SDK
JavaScript/TypeScript SDK 遵循类似的模式,但超时配置使用 httpOptions,值以毫秒为单位。最重要的区别是确保 HTTP 客户端超时和任何包装器超时(如 Express 请求超时)都设置得足够高。
typescriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY!, httpOptions: { timeout: 120_000 }, // 120 秒,单位为毫秒 }); const MODEL_CHAIN = [ "gemini-3.1-pro-preview", "gemini-3-flash", "gemini-2.5-pro", ]; async function callWithRetry( prompt: string, maxRetries = 3, initialDelay = 2000 ): Promise<{ model: string; text: string }> { for (const modelId of MODEL_CHAIN) { for (let attempt = 0; attempt < maxRetries; attempt++) { try { const response = await ai.models.generateContent({ model: modelId, contents: prompt, config: { temperature: 0.7, maxOutputTokens: 8192 }, }); return { model: modelId, text: response.text ?? "" }; } catch (err: any) { const msg = err?.message ?? String(err); // 503 — 退避并重试 if (msg.includes("503") || msg.includes("UNAVAILABLE")) { const delay = initialDelay * 2 ** attempt + Math.random() * 1000; console.log(`503 on ${modelId}, retry ${attempt + 1}/${maxRetries} in ${(delay / 1000).toFixed(1)}s`); await new Promise((r) => setTimeout(r, delay)); continue; } // 504 — 跳到下一个模型 if (msg.includes("504") || msg.includes("DEADLINE")) { console.log(`504 on ${modelId}, switching model`); break; } // 网络超时 — 重试一次然后继续 if (/timeout|ETIMEDOUT|ECONNRESET/i.test(msg)) { if (attempt === 0) { await new Promise((r) => setTimeout(r, 2000)); continue; } break; } throw err; // 未知错误 } } } throw new Error("All models in fallback chain failed"); } // 使用示例 const result = await callWithRetry("Explain quantum entanglement in detail"); console.log(`Model: ${result.model}\n${result.text}`);
cURL — 快速超时测试
对于快速诊断测试,使用 cURL 并配合显式的连接超时和最大时间参数,以确定你的超时问题是服务器端还是客户端引起的。如果这个 cURL 命令成功但你的应用程序失败了,问题就出在你的应用程序超时配置上。
bash# 使用 120 秒超时进行测试 curl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ --connect-timeout 30 \ --max-time 120 \ -d '{ "contents": [{"parts": [{"text": "Say hello"}]}] }'
所有实现的核心原则是一致的:将超时设置为至少 120 秒,实现区分不同错误的分级重试逻辑,并维护一个模型降级链,以确保你的应用程序在 Gemini 3.1 Pro 不可用时不会完全失败。
各平台特定的故障排除
Gemini 3.1 Pro 超时问题在不同的访问平台上表现不同,每个平台都有其特定的修复方案。以下小节涵盖了开发者报告超时问题最多的五个平台,并提供了针对每个平台的解决方案。如果你的平台未在此列出,上面代码部分的通用 API 修复方案可以普遍适用。
Google AI Studio(网页界面)
最严重的超时问题直接影响 Google AI Studio。多名开发者报告了请求运行 15,000 到 20,000+ 秒——超过 4 小时——却不产生任何输出或返回错误的情况。这是 Preview 版本中的一个已确认的缺陷,不是配置问题。AI Studio 界面显示"Running...",计数器无限增长。唯一的修复方法是手动取消请求,然后要么重试(如果服务器状态已改变,有时可以成功),要么在 AI Studio 中切换到其他模型。Google 已在其开发者论坛上确认了这个问题,并正在修复中。如果你持续遇到此问题,切换到 Vertex AI 端点可以提供明显更好的可靠性和更快的 TTFT(根据 2026 年 2 月验证的 Artificial Analysis 基准测试,21.54 秒 vs 31.36 秒)。
Cursor IDE
Cursor 用户在使用 Gemini 3.1 Pro 时报告了两种不同的超时模式。第一种是 "Unable to reach the model provider",通常在 30–60 秒后出现,表明 Cursor 的内部 HTTP 超时在 Gemini 响应之前就到期了。第二种是在 Agent 模式任务中出现 "Taking longer than expected",模型进入一个永远不会产生工具调用的思考循环。对于第一个问题,Cursor 的超时在设置中按模型配置——导航到 Settings > Models,将 Gemini 3.1 Pro 的超时增加到 120 秒或更高。对于无限思考循环,当前的解决方法是取消 Agent 步骤,并将任务分解为更小、更具体的指令,避免需要长时间推理链。一些 Cursor 用户报告说添加明确的指令(如"直接回答,不要过度分析")可以减少思考时间,效果更好。
Android Studio(IDE 中的 Gemini)
据报告,Android Studio 集成的 Gemini 助手在使用 Gemini 3.1 Pro 时会进入无限思考循环,加载图标在本应几秒完成的任务上运行 3–5 分钟。这似乎与 AI Studio 挂起问题有相同的底层原因。Android Studio 集成目前不提供超时配置选项。建议的解决方法是在 Android Studio 任务中切换到 Gemini 3 Flash 或 Gemini 2.5 Pro,因为这些正式发布的模型具有明显更快的 TTFT,且不会出现挂起行为。你可以在 Android Studio 的 Settings > Gemini > Model selection 中更改模型。
直接 API(REST/gRPC)
对于通过 REST 或 gRPC 的直接 API 集成,超时完全由你控制。最常见的错误是根本没有设置超时,导致默认的系统超时(通常为 30 秒)生效。对于 REST API 调用,将 HTTP 客户端超时设置为至少 120 秒。对于通过 Vertex AI 客户端的 gRPC 调用,在调用选项中配置 timeout 参数。上一节中的代码示例涵盖了这两种方法。还要验证你的基础设施中任何中间代理、负载均衡器或 API 网关的超时设置为至少 180 秒,以考虑代理本身的处理开销。
Gemini CLI
Gemini CLI 工具已内置了 Gemini 3.1 Pro 超时处理,包括在主模型不可用时自动降级到 Gemini 2.5 Pro,以及针对 503 错误的指数退避。如果你在使用 CLI 时仍然遇到超时,请更新到最新版本。CLI 的默认超时已针对长时间运行的模型调用进行了设置。如果你正在构建自己的 CLI 包装器,可以参考 Gemini CLI 的源代码来了解其重试和降级模式。
何时切换:决策框架 + 替代模型
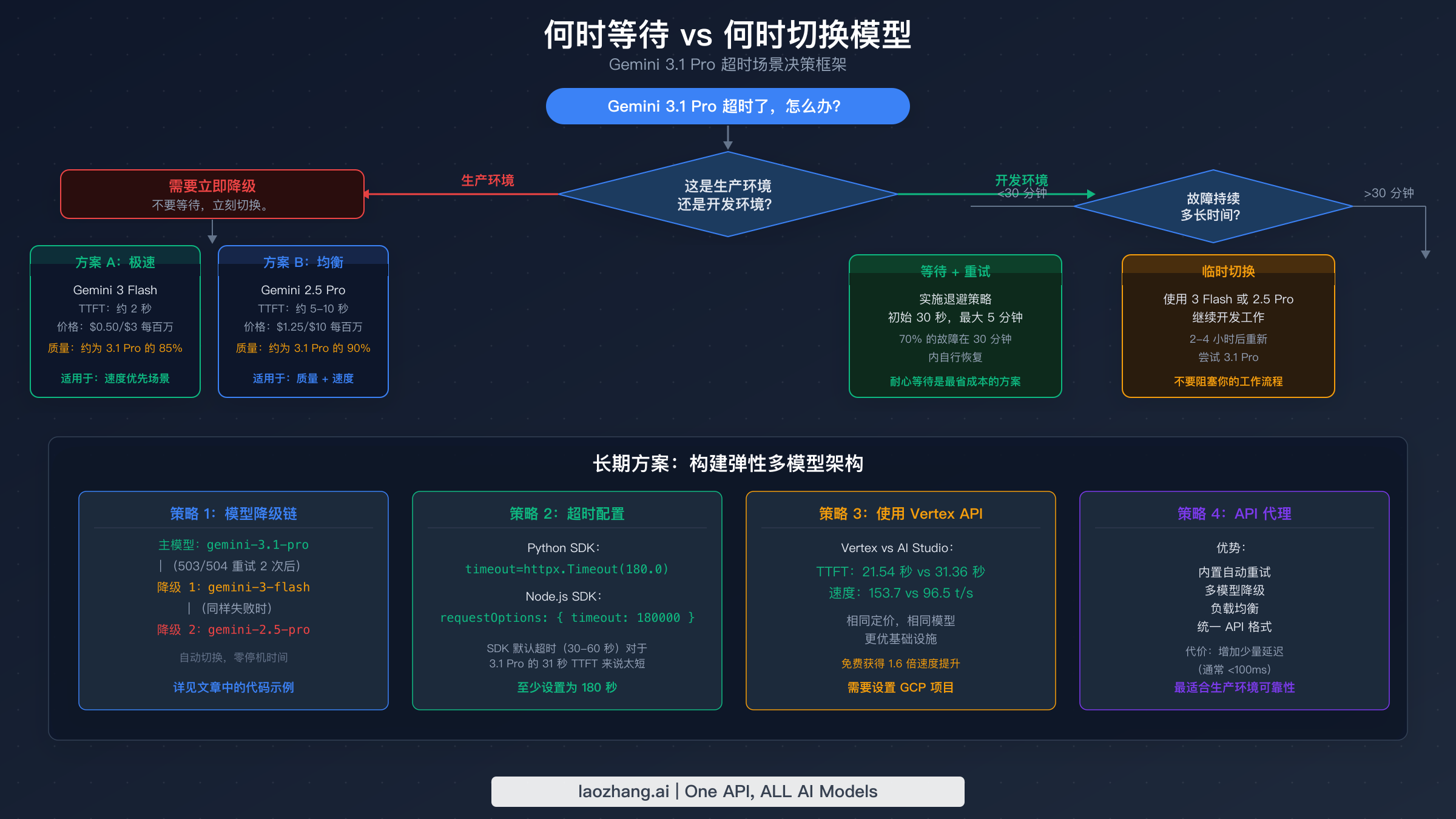
知道何时停止故障排除并切换到其他模型是一个战略决策,取决于你的具体情况——你需要结果的紧迫程度、你是在开发环境还是生产环境,以及你的任务实际需要多高的智能水平。下面的决策框架提供了快速做出决定的具体标准,而不是论坛帖子中常见的模糊"稍后再试"建议。
对于生产环境,决策是二元的:如果 Gemini 3.1 Pro 持续返回 503 错误超过 30 分钟,或者你的请求挂起超过 2 分钟,立即切换到降级模型。生产系统不能容忍在等待 Preview 模型恢复时出现数小时的中断。你的降级方案应该已经在代码中配置好了(参见上面代码部分中的模型降级链),切换应该是自动的。对于开发和测试环境,你有更大的灵活性——在 503 波期间等待 15–30 分钟然后重试是合理的做法,因为 Preview 模型容量波动是暂时性的。
下面的对比表显示了当 Gemini 3.1 Pro 没有响应时最实用的替代方案,以及它们在最重要的指标上的比较——智能水平、速度和成本。所有定价数据来自 Google 官方定价页面和独立基准测试,于 2026 年 2 月 25 日验证。如需完整的定价分析,请参阅我们的 Gemini API 定价完整指南。
| 模型 | 智能水平 | TTFT | 输出速度 | 输入成本 | 输出成本 | 最适合 |
|---|---|---|---|---|---|---|
| Gemini 3.1 Pro | 第 1/114 | 21–31 秒 | 97–154 t/s | $2.00/1M | $12.00/1M | 最高智能任务 |
| Gemini 3 Flash | 良好 | ~1 秒 | 200+ t/s | $0.50/1M | $2.00/1M | 快速降级,适合大多数任务 |
| Gemini 2.5 Pro | 高 | ~3 秒 | 80 t/s | $1.25/1M | $10.00/1M | 可靠的 GA 替代方案 |
| Gemini 2.5 Flash | 中等 | <1 秒 | 300+ t/s | $0.30/1M | $1.50/1M | 成本敏感型工作负载 |
| Claude Opus 4.6 | 非常高 | ~3 秒 | 60+ t/s | $15.00/1M | $75.00/1M | 复杂推理,高可靠性 |
如需了解前两大推理模型之间的更详细对比,请查看我们的 Gemini 3.1 Pro 与 Claude Opus 4.6 对比。虽然 Gemini 3.1 Pro 在原始智能基准测试中领先,但 Claude Opus 4.6 提供了明显更一致的响应时间和更高的可用性,这使得它在可靠性比基准分数更重要时成为一个强有力的选择。
对于需要跨多个 AI 模型保持一致可靠性的生产环境,API 代理服务如 laozhang.ai 可以通过提供单一 API 端点来简化降级流程,该端点处理模型路由、自动重试和提供商之间的故障切换。当你的应用程序需要在 Google 和非 Google 模型之间进行降级时,这种方法尤其有价值,因为直接集成多个提供商的 API 会为你的代码库增加相当大的复杂性。laozhang.ai 平台以统一的 API 格式支持所有主要模型提供商,并内置重试逻辑,这消除了上面代码示例中展示的降级链的实现需求。
会好转吗?Preview 到 GA 的展望
每个使用 Gemini 3.1 Pro 的开发者都想知道的问题是,这些超时问题是永久性的还是暂时性的,以及 Google 何时——而不是是否——会解决它们。根据 Google 之前 Gemini 版本的历史模式和公开声明,有充分的理由期待显著改善,尽管时间表尚不确定。
Google 在 Preview 到 GA 过渡方面的过往记录提供了最有用的预测数据。Gemini 2.5 Pro 遵循了类似的模式:初始 Preview 版本容量有限,503 错误频发,随后大约 2–3 个月后发布 GA 版本,服务器分配和稳定性大幅提升。Gemini 2.5 Flash 经历了更快的周期。这一模式表明,Google 在 Preview 期间利用有限的容量来验证模型架构,然后在 GA 发布时扩展基础设施。如果 Gemini 3.1 Pro 遵循这一模式,2026 年 4 月或 5 月的 GA 发布将与历史时间线一致,届时你可以期待 503 频率的显著降低和更快的 TTFT。
然而,即使在 GA 之后,TTFT 也不太可能大幅下降。21–31 秒的思考时间是模型推理方法的架构特征,而不是服务器容量问题。Google 可能会优化推理以在一定程度上减少它——也许降至 10–15 秒——但 Gemini 3.1 Pro 可能始终是产生第一个 Token 最慢的模型之一,因为这正是它获得智能优势的地方。输出速度已经高于行业平均水平,应该保持优秀。
挂起缺陷——请求无限运行而不返回——几乎可以确定是一个软件缺陷,将在 GA 之前或 GA 时修复。这类问题正是 Preview 期间旨在捕获的。99 小时锁定缺陷同样属于 Google 正在根据开发者论坛报告积极处理的缺陷类别。目前,实际的策略是将 Gemini 3.1 Pro 用于真正需要其排名第一的智能水平的任务,同时为时间敏感的工作维护降级模型,并围绕 GA 发布规划你的架构——GA 将带来更好的可靠性但相似的延迟特征。
常见问题解答
为什么 Gemini 3.1 Pro 需要 30 多秒才能响应,而其他模型只需 1-2 秒?
Gemini 3.1 Pro 的 21–31 秒首次 Token 响应时间是设计使然,而非缺陷。该模型在 AI 指数上获得了第一名的智能排名(得分:57,Artificial Analysis,2026 年 2 月),并在 ARC-AGI-2 上取得了 77.1% 的成绩,正是因为它在生成输出之前投入了更多的计算资源进行推理。可以将其理解为模型在说话之前进行更深入的思考。1.19 秒的行业中位 TTFT 来自那些优先考虑速度而非推理深度的模型。一旦 Gemini 3.1 Pro 开始生成 Token,它实际上以每秒 96.5–153.7 个 Token 的速度产生输出,比行业中位数的每秒 71 个 Token 更快。瓶颈完全在于初始思考阶段。
99 小时锁定缺陷会影响超时错误吗?
99 小时锁定缺陷与超时错误是两个独立的问题,尽管两者都影响 Gemini 3.1 Pro 用户。当你的 API 密钥配额耗尽(或被错误标记为耗尽)时,系统会在重置之前强制执行 99 小时的冷却期,此时就会发生锁定。在锁定期间,你收到的是 429 RESOURCE_EXHAUSTED 错误,而不是 503 或 504 超时错误。如果你怀疑自己被锁定了,请在 Google Cloud Console 中检查配额使用情况。这个缺陷已在 Google AI Developer Forum 上被广泛报告,Google 正在修复中。
超时的 API 请求会被收费吗?
根据 Google 的计费模型,你需要按模型处理的 Token 数量付费。对于服务器立即拒绝请求的 503 错误,没有 Token 被处理,你不应该被收费。对于模型已开始处理但未完成的 504 错误,Google 的政策是对输入 Token 收费但不对输出 Token 收费,因为没有成功生成输出。对于没有返回响应的挂起缺陷,计费行为尚不明确——一些开发者报告说在控制台中看到了从未完成的请求的 Token 使用量。请在超时事件期间密切监控你的 API 使用量仪表板。
Vertex AI 是否比 AI Studio 对 Gemini 3.1 Pro 明显更好?
是的,根据当前基准测试。Vertex AI 的 TTFT 为 21.54 秒,而 AI Studio 为 31.36 秒——大约快 1.5 倍(Artificial Analysis,2026 年 2 月)。Vertex 的输出速度也明显更高,为每秒 153.7 个 Token,而 AI Studio 为每秒 96.5 个 Token。Vertex AI 似乎也较少受到挂起缺陷的影响。权衡之处在于 Vertex AI 需要一个启用了计费的 Google Cloud 项目和稍微复杂的身份验证设置,而 AI Studio 只需要一个简单的 API 密钥。
我可以通过第三方 API 提供商使用 Gemini 3.1 Pro 来避免超时吗?
可以,多家第三方 API 提供商提供对 Gemini 3.1 Pro 的访问,并带有它们自己的重试逻辑、超时处理和模型降级配置。这些提供商通常通过 Vertex AI(更快的端点)进行路由,并添加自己的重试层,与直接 API 访问相比可以提高可靠性。但是,它们会增加一层延迟和成本。请评估可靠性的提升是否值得为你的特定用例增加额外的开销。